线性判别分析(LDA)与主成分分析(PCA)
简介
线性判别分析(LDA)
- 什么是LDA
线性判别分析(Linear Discriminant Analysis,LDA)是一种经典的降维方法。LDA是一种监督学习的降维技术,数据集的每个样本有类别输出。
- LDA的特点
- 多维空间中,数据处理分类问题较为复杂,LDA算法将多维空间中的数据投影到一条直线上,将d维数据转化成1维数据进行处理。
- 对于训练数据,设法将多维数据投影到一条直线上,同类数据的投影点尽可能接近,异类数据点尽可能远离。
- 对数据进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定样本的类别(找到更合适分类的空间)。 如果用一句话概括LDA思想,即“投影后类内方差最小,类间方差最大”。 (与PCA不同,更关心分类而不是方差)
-
LDA的核心思想
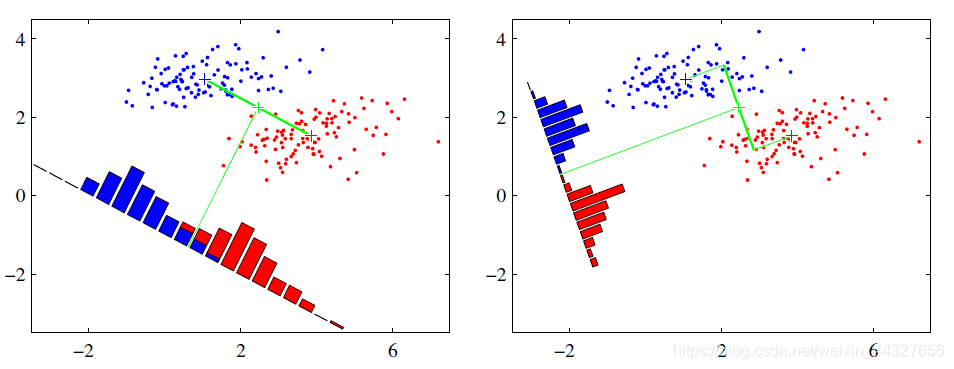
左图:让不同类别的平均点距离最远的投影方式 , 右图:让同类别的数据挨得最近的投影方式。从上图直观看出,右图红色数据和蓝色数据在各自的区域来说相对集中,根据数据分布直方图也可看出,所以右图的投影效果好于左图,左图中间直方图部分有明显交集。
以上例子是基于数据是二维的,分类后的投影是一条直线。如果原始数据是多维的,则投影后的分类面是一低维的超平面。 -
LDA算法原理
输入:数据集 ,其中样本 是n维向量, ,降维后的目标维度 。定义 为第 类样本个数;
为第 类样本的集合;
为第 类样本的均值向量;
为第 类样本的协方差矩阵。
其中 假设投影直线是向量 ,对任意样本 ,它在直线 上的投影为 ,两个类别的中心点 , $u_1 $在直线 的投影分别为 、 。
LDA的目标是让两类别的数据中心间的距离 尽量大,与此同时,希望同类样本投影点的协方差 、 尽量小,最小化 。 定义 类内散度矩阵 类间散度矩阵
据上分析,优化目标为 根据广义瑞利商的性质,矩阵 的最大特征值为 的最大值,矩阵 的最大特征值对应的特征向量即为 。
-
LDA算法降维流程
输入:数据集 ,其中样本 $x_i $ 是n维向量, ,降维后的目标维度 。
输出:降维后的数据集 $\overline{D} $ 。步骤:
- 计算类内散度矩阵 。
- 计算类间散度矩阵 。
- 计算矩阵 。
- 计算矩阵 的最大的 d 个特征值。
- 计算 d 个特征值对应的 d 个特征向量,记投影矩阵为 W 。
- 转化样本集的每个样本,得到新样本 。
- 输出新样本集
-
LDA的优缺点
优点 缺点 1.可以使用类别的先验知识,2. 以标签、类别衡量差异性的有监督降维方式,相对于PCA的模糊性,其目的更明确,更能反映样本间的差异; 1. LDA不适合对非高斯分布样本进行降维;2. LDA降维最多降到k-1维;3. LDA在样本分类信息依赖方差而不是均值时,降维效果不好;4. LDA可能过度拟合数据。
主成分分析(PCA)
-
什么是PCA
PCA就是将高维的数据通过线性变换投影到低维空间上去,投影思想是找出最能够代表原始数据的投影方法。被PCA降掉的那些维度只能是那些噪声或是冗余的数据。去冗余的目的是去除可以被其他向量代表的线性相关向量,因为这部分信息量是多余的。去噪声的目的去除较小特征值对应的特征向量,特征值的大小反映了变换后在特征向量方向上变换的幅度,幅度越大,说明这个方向上的元素差异也越大,要保留。 -
PCA的特点
PCA可解决训练数据中存在数据特征过多或特征累赘的问题。核心思想是将m维特征映射到n维(n < m),这n维形成主元,是重构出来最能代表原始数据的正交特征
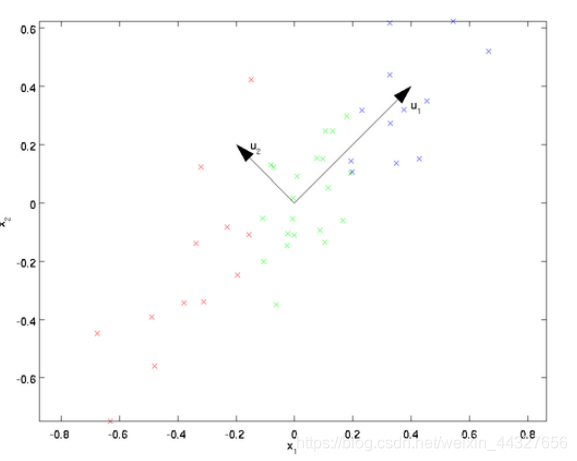
从图可看出, 比 好,为什么呢?有以下两个主要评价指标:
1) 样本点到这个直线的距离足够近。
2)样本点在这个直线上的投影能尽可能的分开。
如果我们需要降维的目标维数是其他任意维,则:
1)样本点到这个超平面的距离足够近。
2)样本点在这个超平面上的投影能尽可能的分开。 -
PCA的核心思想
-
PCA算法流程
输入: 维样本集 ,目标降维的维数 。
输出:降维后的新样本集 。
主要步骤如下:- 对所有的样本进行中心化,$ x^{(i)} = x^{(i)} - \frac{1}{m} \sum^m_{j=1} x^{(j)} $ 。
- 计算样本的协方差矩阵 。
- 对协方差矩阵 进行特征值分解。
- 取出最大的 $n’ $ 个特征值对应的特征向量 。
- 标准化特征向量,得到特征向量矩阵 。
- 转化样本集中的每个样本 。
- 得到输出矩阵 。 注:在降维时,有时不明确目标维数,而是指定降维到的主成分比重阈值 。假设 个特征值为 ,则 可从 得到。
-
PCA算法主要优缺点
| 优点 | 缺点 |
|---|---|
| 1.仅仅需要以方差衡量信息量,不受数据集以外的因素影响,2.各主成分之间正交,可消除原始数据成分间的相互影响的因素。3. 计算方法简单,主要运算是特征值分解,易于实现。 | 1.主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。2. 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。 |
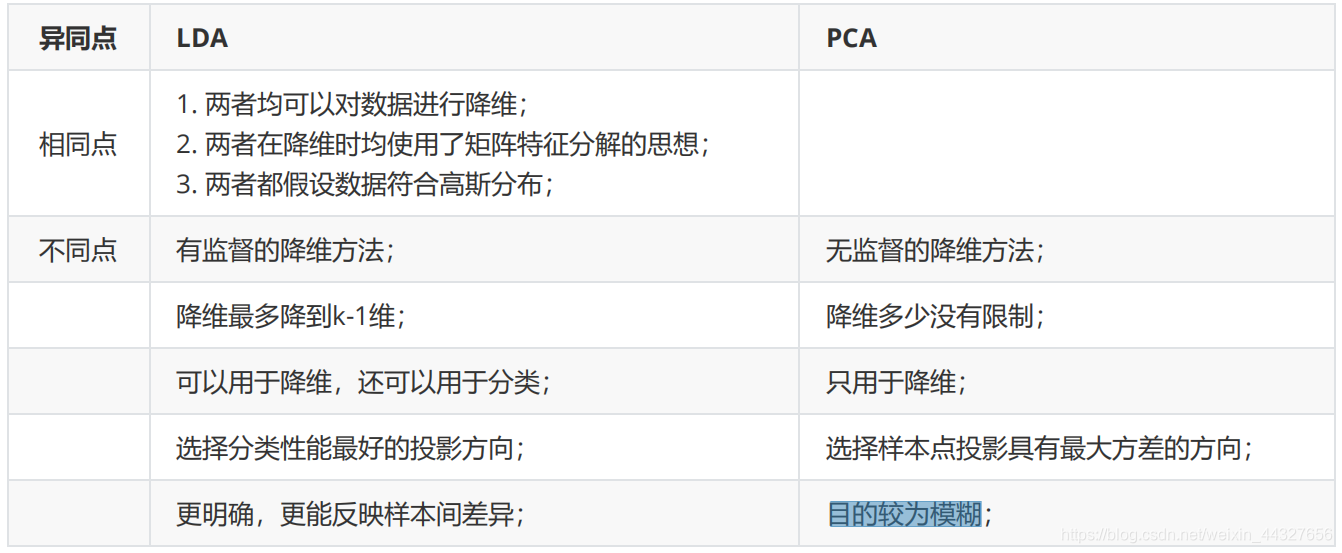
LDA和PCA的异同点