参考资料:
https://blog.csdn.net/m0_37788308/article/details/78115209 PCA主成分分析(入门计算+深入解析)(一)
https://www.cnblogs.com/pinard/p/6251584.html 奇异值分解(SVD)原理与在降维中的应用
https://zhuanlan.zhihu.com/p/32658341 LDA线性判别分析
《机器学习》 周志华
维度灾难
什么是维度灾难:维基百科
https://zh.wikipedia.org/wiki/%E7%BB%B4%E6%95%B0%E7%81%BE%E9%9A%BE#%E9%87%87%E6%A0%B7
维数灾难(英语:curse of dimensionality)用来描述当(数学)空间维度增加时,分析和组织高维空间(通常有成百上千维),因体积指数增加而遇到各种问题场景。
在机器学习中,维度灾难常指以下问题:
1. 在高维情况下,数据样本稀疏。
比如,knn 的讨论中经常涉及到维度灾难,是因为 k 近邻算法基于一个重要的基本假设:任意样本附近任意小的距离内总能找到一个训练样本,即训练样本的采样密度足够大,也称为“密采样”,才能保证分类性能;当特征维度很大时,满足密采样的样本数量会呈指数级增长,大到几乎无法达到。
2. 在高维情况下,涉及距离、内积的计算变得困难。
其实,不仅是 K 近邻,其他机器学习算法几乎都会遇到维度灾难的问题。
降维
缓解维度灾难的一个重要途径就是 降维 。
为什么能够进行降维?
这是因为很多时候,数据是高维的,但是与学习任务(分类、回归等)密切相关的仅是某个低维分布,即高维空间中的某个低维嵌入。因此,很多情况下,高维空间中的样本点,在低维嵌入子空间中更容易学习。线性降维
一般来说,欲获得低维子空间,最简单的方法是对原始高维空间进行线性变换:
给定 维空间中的样本 ,变换之后得到 维空间中的样本
其中 是变换矩阵, 是样本在新空间中的表达。
变换矩阵 可以视为 个 维基向量,新空间中的属性是原空间属性的线性组合,基于线性变换来进行降维的方法称为线性降维方法,都符合上面的式子,主要区别在于对低维子空间的性质有所不同,相当于对 施加了不同的约束。降维效果的评估
通常通过比较降维前后学习器性能,若性能有提高则认为降维起到了作用。针对已经降到二维或者三维的情况,可以利用可视化技术直观地判断降维效果。
PCA 主成分分析
PCA 主成分分析是一种最常用的无监督降维方法,通过降维技术把多个变量化为少数几个主成分(综合变量)的统计分析方法。这些主成分能够反映原始变量的绝大部分信息,它们通常表示为原始变量的某种线性组合。
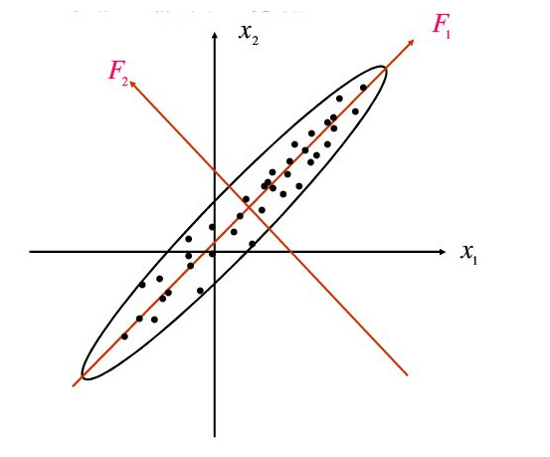
PCA理论基础: 方差最大理论
什么是方差最大理论呢?
简单解释就是:我们要做降维,相当于投影,就像下面的二维数据降到一维,我们自然希望降维之后能够保留原来数据中尽可能多的信息 ,如何才能尽可能的保留信息呢,这就需要找一个方向使得投影后它们在投影方向上的方差尽可能达到最大,即在此方向上所含的有关原始信息样品间的差异信息是最多的。
方差越大,数据压缩相对越小,保留的信息量越大,方差和熵均可以描述不确定性来量化信息,虽然熵更合适。
参考知乎:https://www.zhihu.com/question/36481348 如何理解“方差越大信息量就越多”?
这里盗图:
PCA 算法
——————————————————————————————————————————————————
输入: 样本集
; 低维空间维数
。
输出:投影(变换)矩阵
。
过程:
- 对所有样本进行中心化 (去均值): ;
- 计算样本的协方差矩阵 (计算各维度之间的相关性);
- 对协方差矩阵 做特征值分解;
- 取最大的 个特征值所对应的特征向量
——————————————————————————————————————————————————
在主成分分析 PCA 中,需要找到样本协方差矩阵
的最大的
个特征向量,然后用这最大的
个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵
,当样本数多样本特征数也多的时候,这个计算量是很大的。
这个时候,就需要一种新的方法简化计算了,这就是线性代数中的 SVD 奇异值分解。
这里学有余力推荐看一本书《Linear Algebra Done Right , 3E》 中文版叫做《线性代数应该这样学》 …算了,不推荐了,我看过一遍现在回头看看不懂了╥﹏╥
SVD 奇异值分解可以不过多介绍,具体详细过程可以参考 https://www.cnblogs.com/pinard/p/6251584.html
主要提一下 SVD 的好处,首先是 SVD 主要是处理不是方阵的特征值分解,其次有一些SVD的实现算法可以不用先求出协方差矩阵 ,也能求出我们的右奇异矩阵 。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
左奇异矩阵可以用于行数的压缩,相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
LDA 线性判别分析
另一个常用的降维方法(也可作为一种分类方法),是基于有监督学习的 LDA 线性判别分析,也就是说数据样本都是带有其类别标签的。
LDA 的基本降维策略是:
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点中心尽可能远离。更简单的概括为一句话,就是“投影后类内方差最小,类间方差最大”。
(盗图):
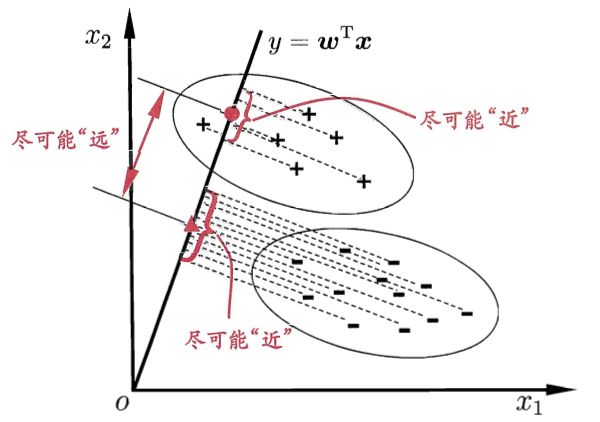
LDA 优化目标包含两部分:
欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能的小;
欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能的大;同时考虑以上两者即是 LDA 的优化目标。
给定数据集 ,令 、 、 分别表示第 类实例的集合、均值向量、协方差矩阵。
若将数据投影到直线
上,则两类样本的中心在直线上的投影分别为
和
;
若将所有样本点都投影到直线上,则两类样本的协方差分别为
和
;
LDA 优化目标可表示为最大化:
定义“类内散度矩阵”:
定义“类间散度矩阵”:
则可重写
这就是 LDA 的最大化目标,即 和 的 “广义瑞利商”。
求解参数
不失一般性,令
,则
由拉格朗日乘数法,上式等价于
因为 方向恒为 ,则令 ,得到
实践中,考虑数值解的稳定性,通常是对 进行奇异值分解(SVD),即 ,再由 得到 。
PCA 和 LDA 的对比
- PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性(方差最大);而LDA是为了让映射后的样本有最好的分类性能(投影后类内方差最小,类间方差最大)。
- PCA 是无监督学习,LDA 是有监督学习(考虑了类别信息),因此 LDA 也可以进行分类。
- LDA在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
其他降维方法
对于一些可能需要非线性映射才能得到低维嵌入的高维空间,可以使用类似 SVM 中的核技巧,即 核化线性降维 ,如核化主成分分析(KPCA)。
借鉴拓扑流形概念,可以使用 流形学习 的降维方法。