继上一篇文章:Spark2.0.2源码分析——Application的注册启动(standalone 模式下)
application 向 Master 注册并提交后,Master 最终会调用 schedule 方法规划分配将要 worker 上运行的 executor 的资源,然后调用 allocateWorkerResourceToExecutors 将资源分配给 executor,并启动 executor。
launchExecutor:
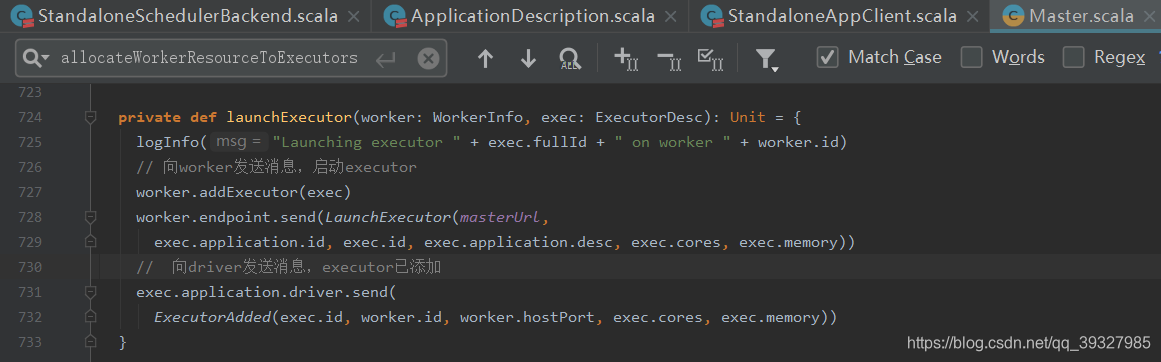
来到 Worker 端:
worker 端接收到 launchExecutor 消息后
- 先会判断消息发送的
master是否为alive - 接着创建
executor的工作目录和本地临时目录 - 将
master发送来的信息封装为ExecutorRunner对象,ExecutorRunner用来管理一个executor进程的执行,目前只在standalone模式下使用 - 调用
ExecutorRunner的start方法 - 记录
executor使用的资源 - 向
Master发送消息,报告当前executor的状态
// 启动executor
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
// 判断是否是alive master发送来的消息
if (masterUrl != activeMasterUrl) {
// 如果不是,打印warn信息,无效的master尝试启动executor
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// 创建executor工作目录
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// 为executor创建本地目录
// executor在环境变量中获取SPARK_EXECUTOR_DIRS配置
// application完成后,worker将其删除
val appLocalDirs = appDirectories.getOrElse(appId,
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
appDir.getAbsolutePath()
}.toSeq)
appDirectories(appId) = appLocalDirs
// worker将接受到的信息,封装成ExecutorRunner对象
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
// 调用ExecutorRunner的start方法,启动线程
manager.start()
coresUsed += cores_
memoryUsed += memory_
// 向master发送消息,报告当前executor的状态
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
// 异常处理
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
// 向master发送消息,executor状态改变,状态为FAILED
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}
其中,重点是 ExecutorRunner 的 Start 方法:
创建 workerThread 线程,该线程运行时执行 fetchAndRunExecutor 方法
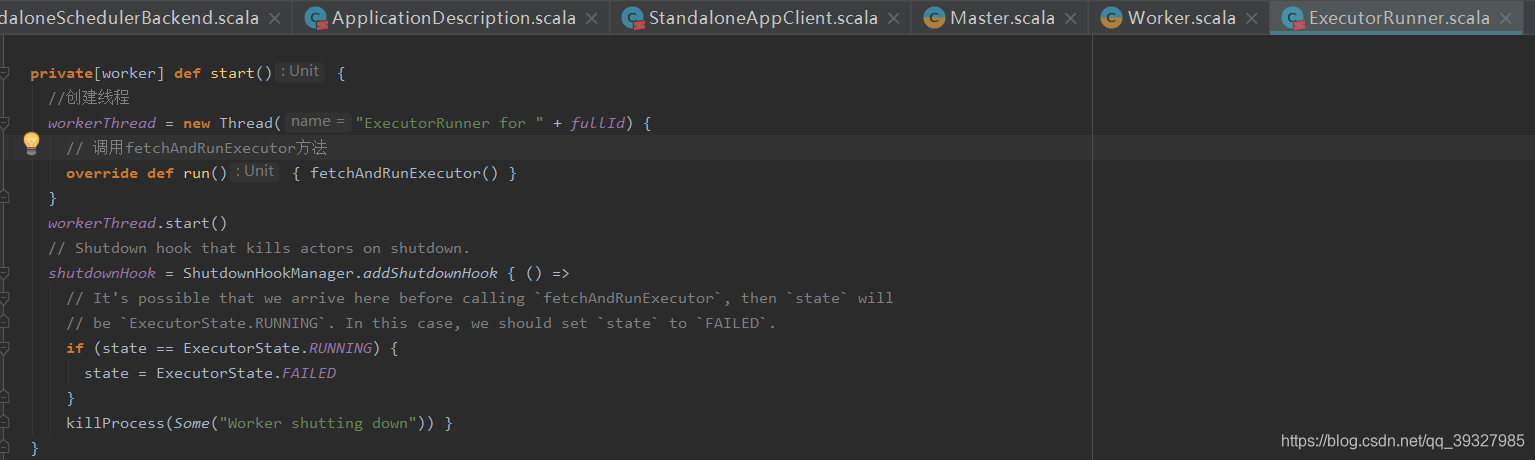
fetchAndRunExecutor 方法将接收到的信息后,执行步骤如下:
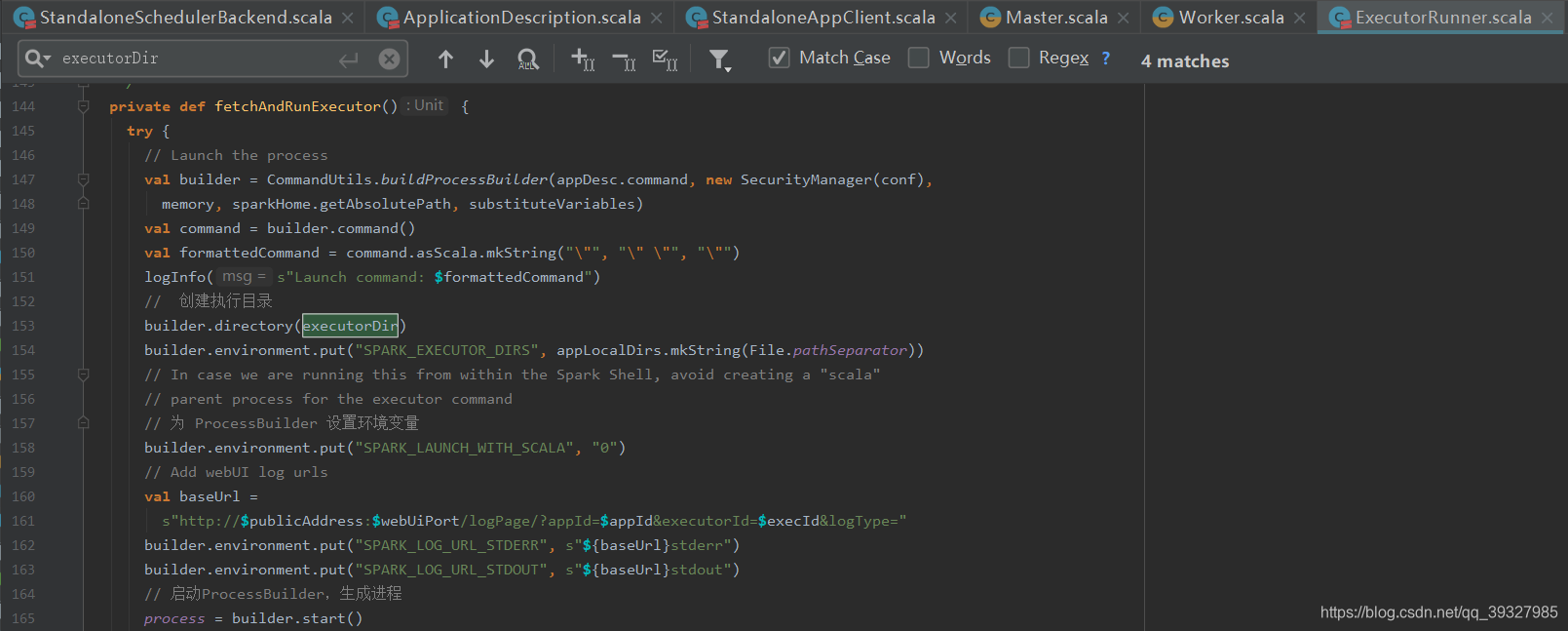
- 创建
ProcessBuilder,用于在本地执行命令或者执行脚本 - 为
ProcessBuilder创建执行目录,该目录为executorDir目录,即worker创建的executor工作目录 - 为
ProcessBuilder设置环境变量 - 启动
ProcessBuilder,生成进程,
这里就会执行命令,执行命令后会产生一个进程CoarseGrainedExecutorBackend,该进程为executor的守护进程:
这里注意:CoarseGrainedExecutorBackend 就是在 appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)) 这行的 appDesc 中包含,
在 sparkcontext 初始化的时候,如果是 Standalone 模式,在初始化 val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls) 对象,StandaloneSchedulerBackend 对象中 command 包含了创建 CoarseGrainedExecutorBackend 的命令:

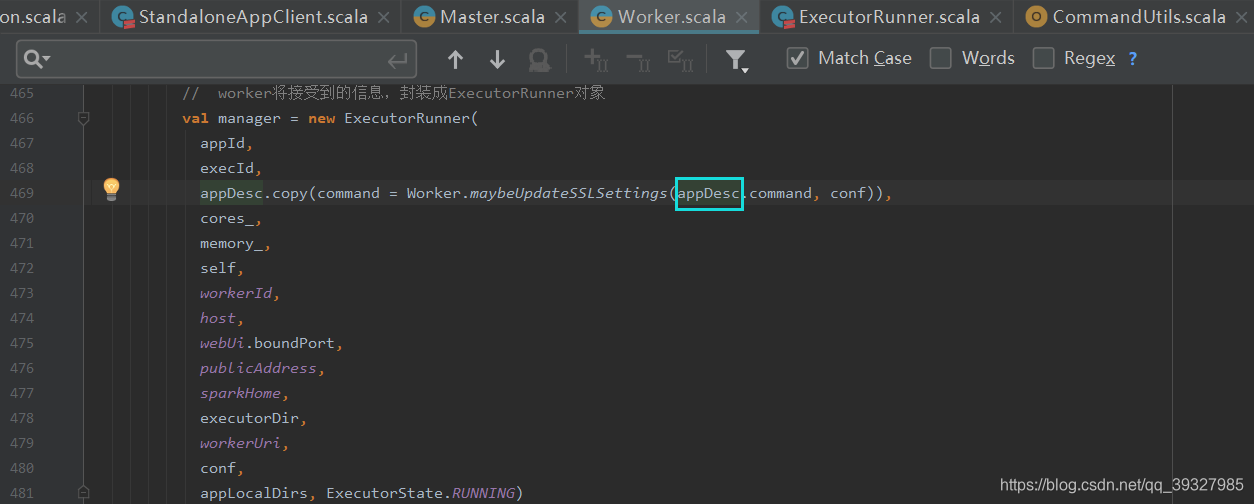
会把如下命令给 ProcessBuilder 构造器,可以看出就是一个 java -cp *.jar main 类:
/opt/jdk1.8/bin/java -Dhdp.version=2.6.0.3-8 \
-cp /usr/hdp/2.6.0.3-8/spark2/conf/:/usr/hdp/2.6.0.3-8/spark2/jars/*:/usr/hdp/current/hadoop-client/conf/ \
-Xmx1024M \
-Dspark.history.ui.port=18081 \
-Dspark.driver.port=33197 \
org.apache.spark.executor.CoarseGrainedExecutorBackend \
–driver-url spark://[email protected]:33197 \
–executor-id 0 \
–hostname 192.168.1.20 \
–cores 5 \
–app-id app-20180419170349-0522 \
–worker-url spark://[email protected]:37617
这里的 spark 运行参数,由 substituteVariables 将其替换为分配好实际值
执行该命令会调用 CoarseGrainedExecutorBackend 的 main 方法,对命令行的 args 参数进行处理
- 重定向进程输出流文件
- 重定向进程错误流文件
- 等待获取
executor进程的退出状态码,等到executor的状态为已退出,向worker发送消息,executor状态改变

executor 的启动成功~