Spark集群启动流程-Worker启动-源码分析
上篇文章介绍了Master启动(Master启动点击:https://blog.csdn.net/weixin_43637653/article/details/84073849
),接下来,我们在源码里继续分析Worker的启动
总结:(和Master几分相似)
1.创建ActorSystem对象,并将初始化参数传入
2.创建了属于Worker的Actor
3.启动生命周期方法(preStart),向Master进行注册,通过Master的Url获取Master的actor,
4.Worker接收到Master发送过来的注册成功信息,然后更新url
5.调用定时器,定时地向Master发送心跳信息
全部图解:
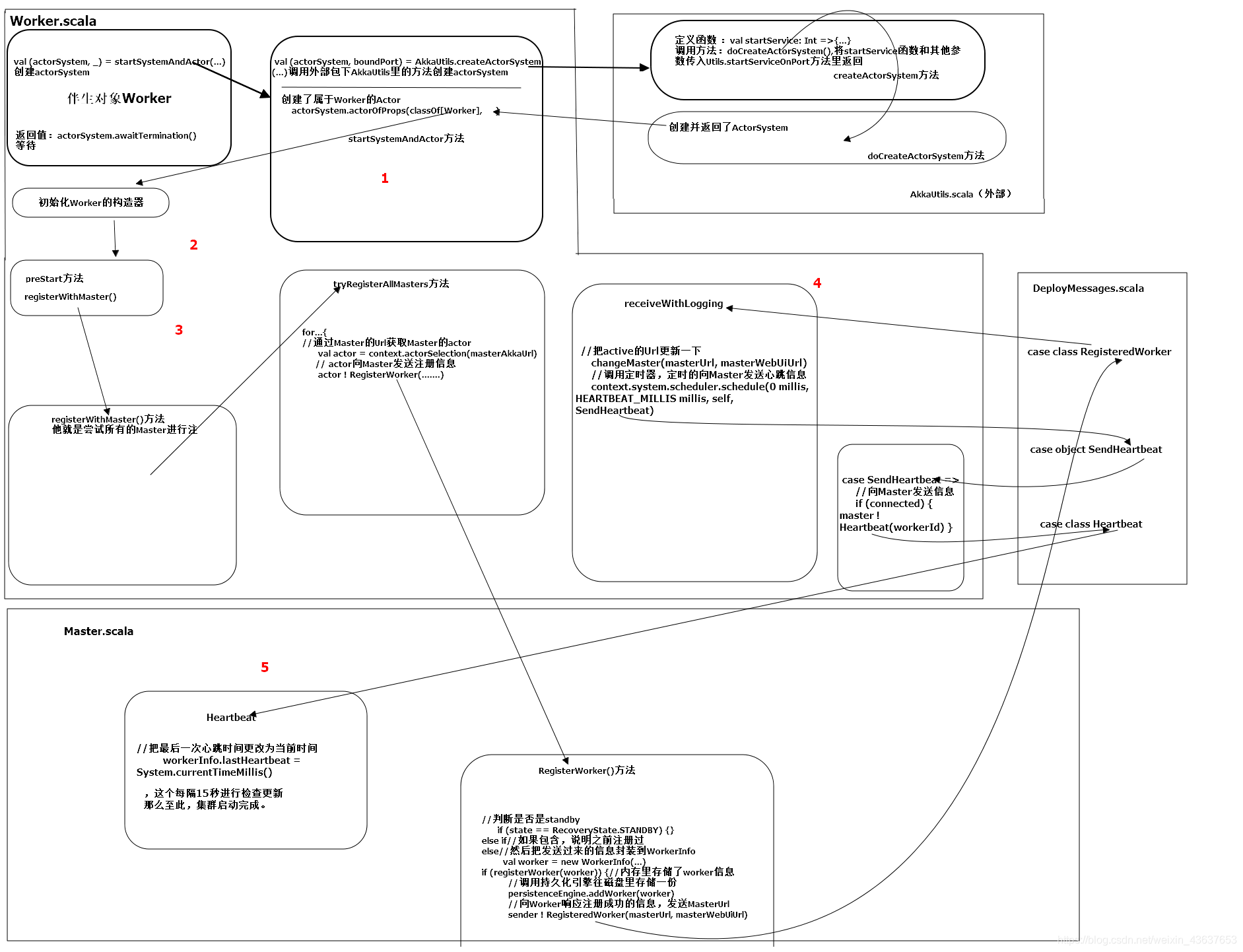
详解:
在启动之时,Master和Worker是同时启动,我们进入到Worker这个类中来进行分析
同样,我们找到他的伴生对象里的main方法

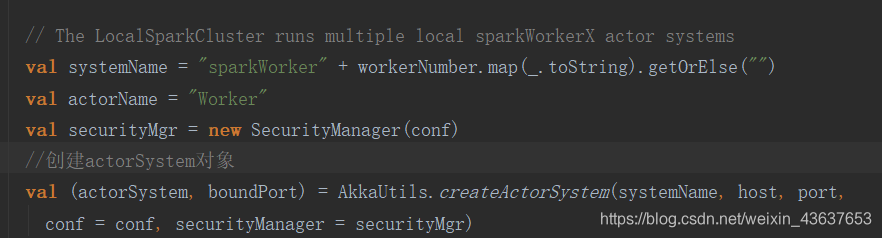
与Master里相似,开始初始化了一些用于启动actor的参数,接下来封装到args里将其传到startSystemAndActor的方法里,这个startSystemAndActor方法就在下面,可以看到它里面同样调用了AkkaUtils工具包,并调用了createActorSystem方法,来创建这个actorSystem
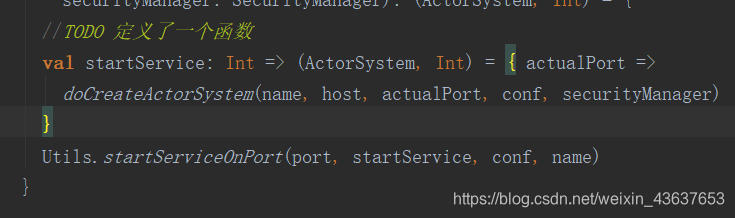
那么这个createActorSystem方法呢,,它里面定义了一个函数,和调用了startServiceOnPort这个方法,这个函数是传给了startServiceOnPort方法

通过startServiceOnPort方法,我们拿到actorSyatem这个对象
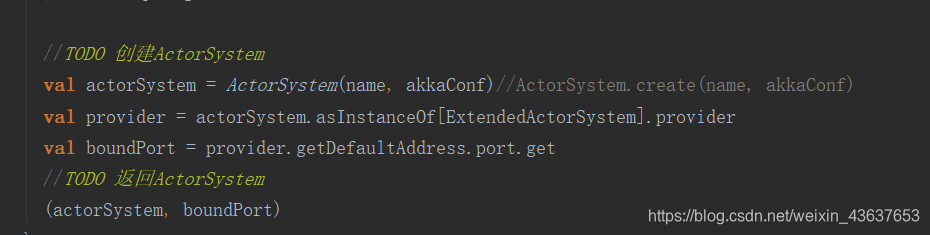
然后回退到开始创建actorSyatem对象的那,这时候我们就有了这个actorSyatem这个对象,往下看,会发现,它同样调用了这个actorOf这个方法,然后创建了属于Worker的Actor

用反射的方式,new一个Worker,一旦new了这个worker,那么它里面的主构造器就开始初始化了,一直往下执行到preStart方法

这个preStart生命周期方法里,它有一个registerWithMaster方法,这个方法用来向Master来进行注册的,怎么注册的呢?我们点进去看:

它里面用了一个模式匹配,这里面最主要的是tryRegisterAllMasters方法,他就是尝试所有的Master进行注册
如果尝试没有成功,下面有个尝试的时间的阈值registrationRetryTimer,那么这里面有个ReregisterWithMaster方法,其实这个ReregisterWithMaster方法和tryRegisterAllMasters方法里面是一样的,我们先进ReregisterWithMaster方法里看看:
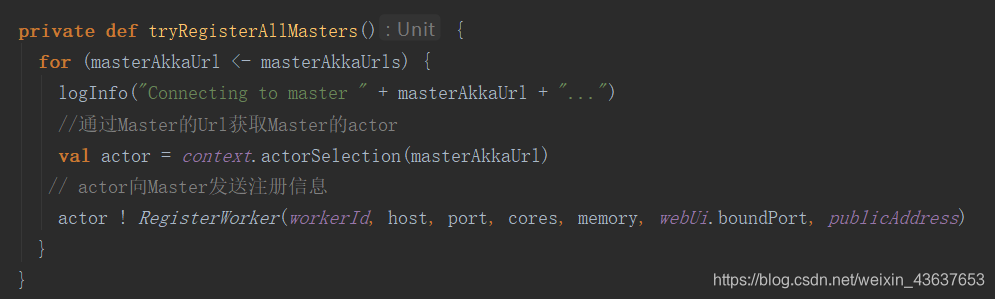
这里面有个for循环,将master的Url遍历出来,然后通过Master的Url获取Master的actor,接下来,actor向Master发送注册信息。就是通过一个!的方式异步发送信息,点进去RegisterWorker里:
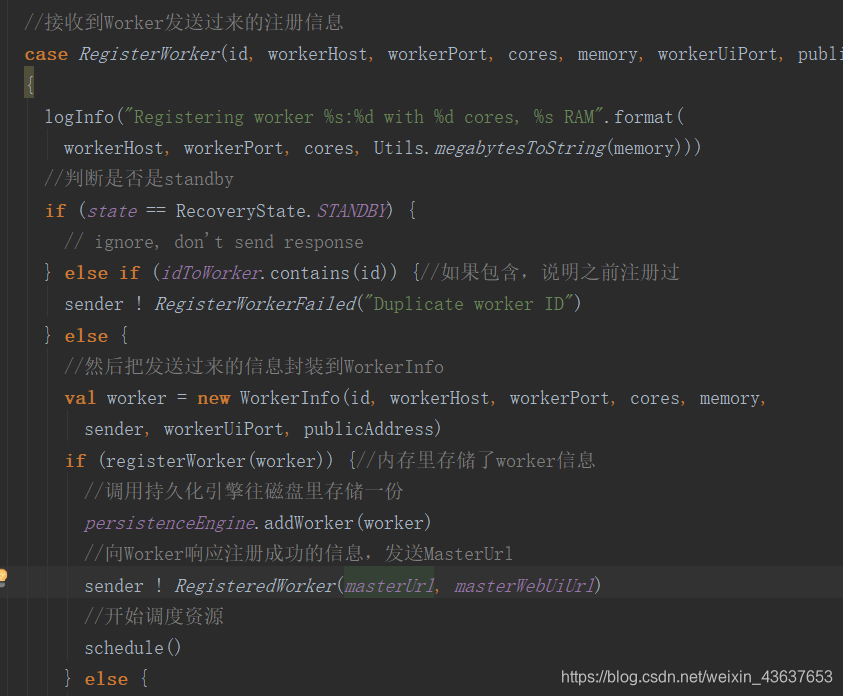
这里我们接收到Worker发送过来的注册信息,然后判断是否是standby,如果是standby模式,则说明都不做,//idToWorker就是所有注册过的id,然后将传进来的id与之比较 //看是否包含这个id,如果包含,说明之前注册过,如果注册过,则不需要再注册,也不需要做任何。else 然后把发送过来的信息封装到WorkerInfo赋给worker,下一步判断,将封装的WorkerInfo信息传给registerWorker方法里进行一些过滤处理,保证里面是一些有效的worker。再往下,判断内存里存储了wrker信息,然后调用持久化引擎往磁盘里存储一份,目的是为了防止
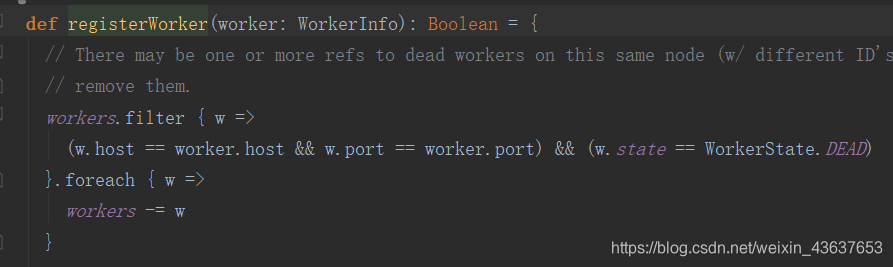
丢失。可以点开这个addWorker方法,这里是用persist,里面封装有worker的id和worker的信息。
然后,向Worker响应注册成功的信息,并发送MasterUrl,并且开始调度资源。
-我们点进去RegisteredWorker方法,到receiveWithLogging里
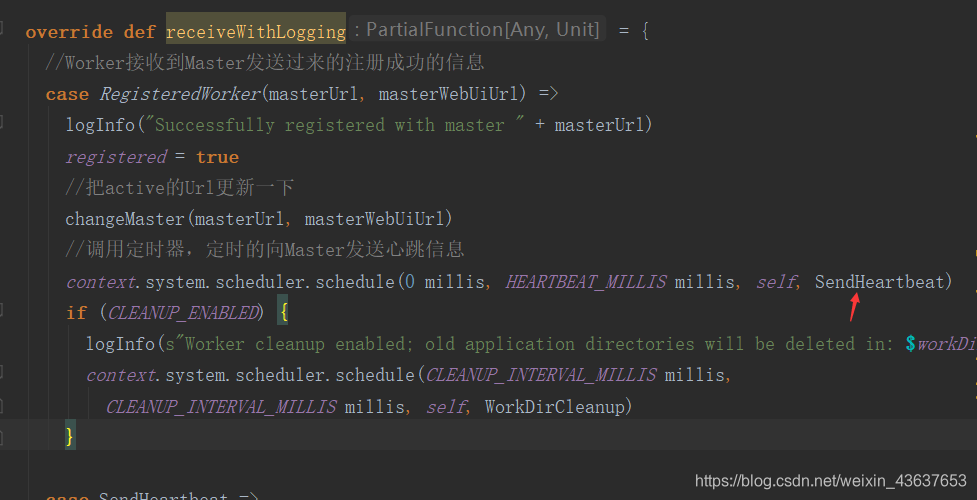
receiveWithLogging里Worker接收到Master发送过来的注册成功的信息,实际上就是发送Url。“changeMaster(masterUrl, masterWebUiUrl)”就是把active的Url更新一下,然后又调用了一个定时器,定时的向Master发送心跳信息,从0 millis开始到15秒(60/4),也就是说,没15秒发送一次心跳,那么发送心跳的逻辑,就是在SendHeartbeat里,里面是判断connected,connected的默认值为false。其实发送信息,就是往master传了一个workerId

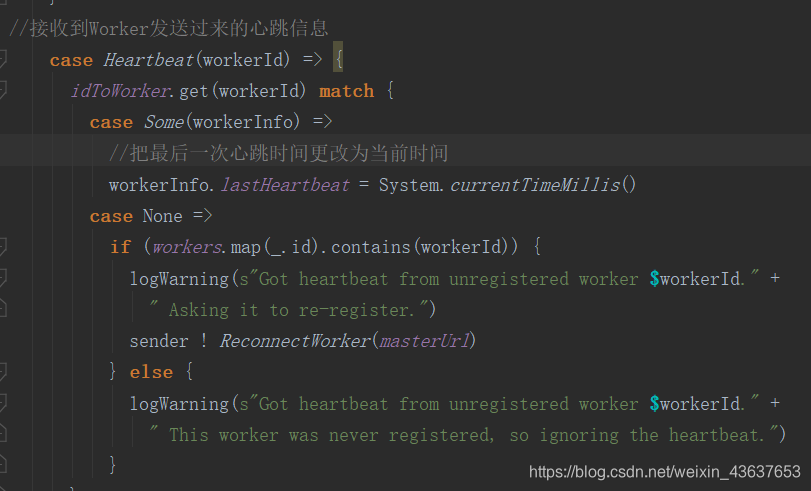
那么Master接收到Worker发送过来的信息后,通过ge方法将workerid进行模式匹配,在some里,拿到workerInfo信息,把最后一次心跳时间更改为系统当前时间,至此,这是一次心跳时间,这个每隔15秒进行检查更新,保证时间最新,一旦长时间未做响应,那么就是这两个节点网络断开了或者worker死掉了,这样就会被那个检查超时的定时器监测到,并进行删除这个信息。
那么至此,集群启动完成。