Spark 应用程序启动的时候必须依赖SparkContext类,在SparkContext实例化的时候主要的工作是:实例化DAGScheduler job调度器,TaskSchedulerImpl 任务调度器,StandaloneSchedulerBackend通信实体。


实例化StandaloneSchedulerBackend后会将其传给TaskSchedulerImpl 底层任务调度器,
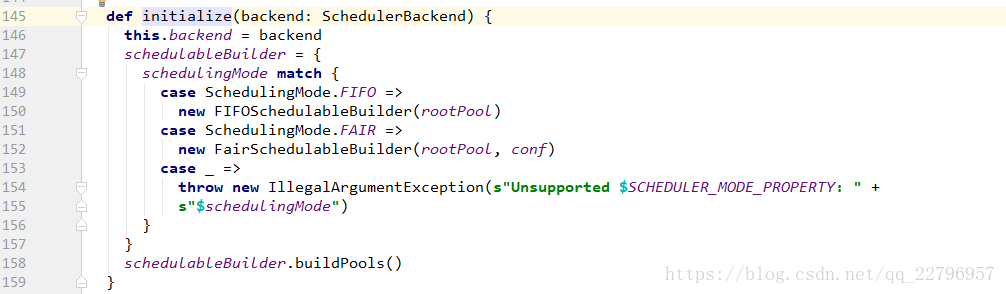
同时会初始化任务的资源池,默认的是FIFO的形式,但是可以配置FAIR的模式,在FAIR模式下更加可以通过rdd.sparkContext.setLocalProperty(“spark.scheduler.pool”,”xx”)为每个任务分配不同的资源池执行任务。
二、TaskSchedulerImpl 的start方法启动,实际上就是StandaloneSchedulerBackend.start();

override def start() { super.start() 启动JVM进程名称 val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts) Application 描述信息 val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command, webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
StandaloneSchedulerBackend的内部通信实体StandaloneAppClient负责接收和发送指令
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
ClientEndpoint的onstart()负责向master发送注册application的消息


会不断的根据设定的时间重试,直到register.get为true的时候停止。

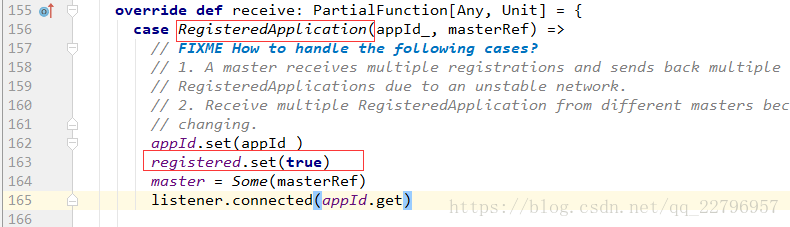
当master接收到RegisterApplication的消息后会向client向自己发送一条RegisteredApplication消息告诉client已经注册成功,然后master开始调度决定在某一个服务器上启动Driver。
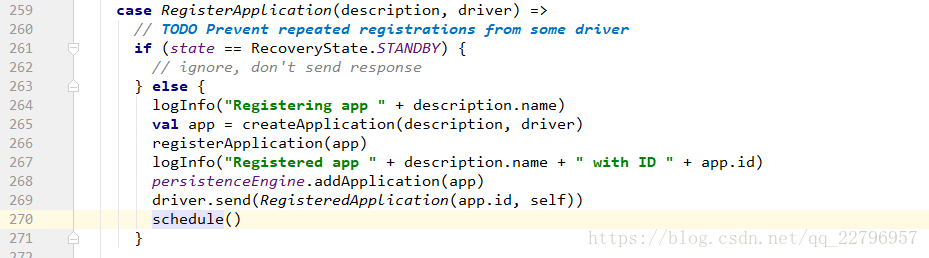
client接收到消息后会设定registered为true,此时停止发送注册application消息给master。
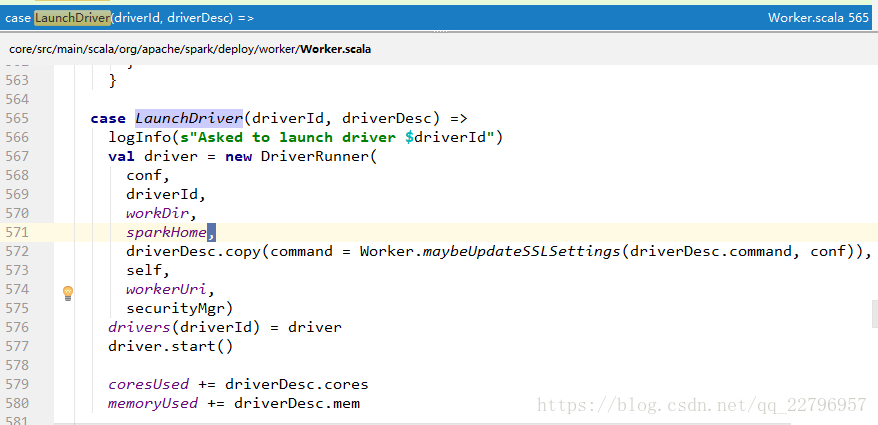
此时master会先对ALIVE的worker打乱排序,选择一个内存和core都满足的worker启动Driver。


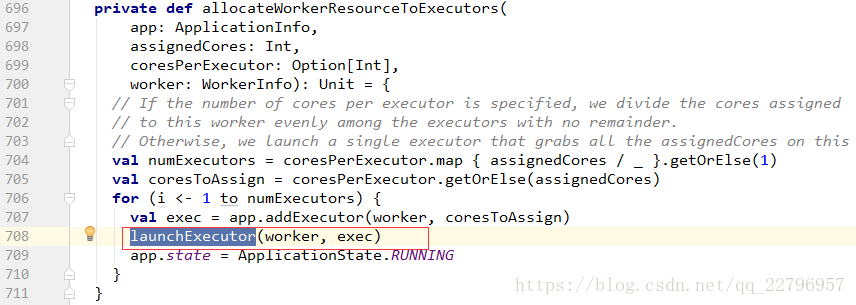
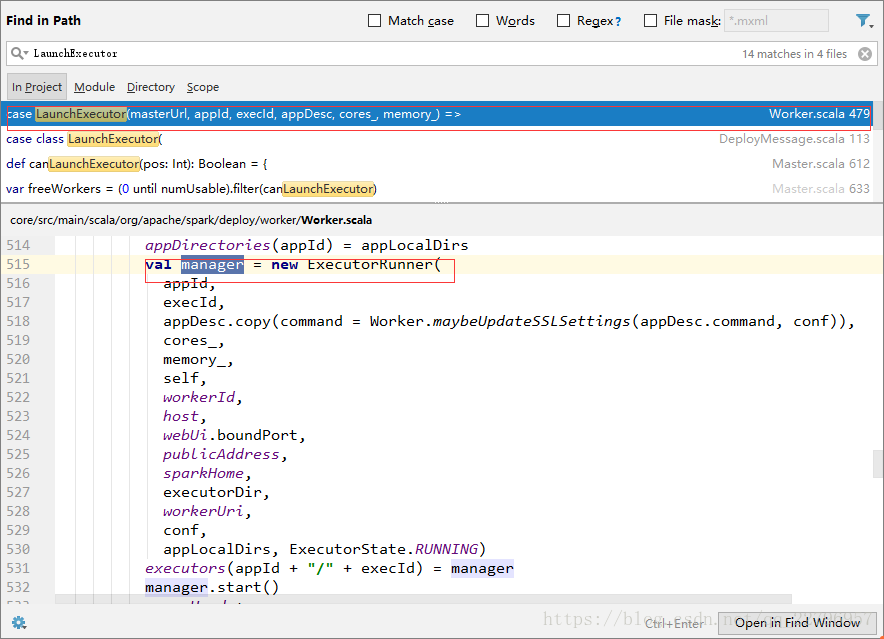
startExecutorsOnWorkers是master开始在worker上启动Executor的动作,其实根据配置策略是有两种模式来启动:
1、对于满足要求的服务器,先最大化的分配Executor,直到没有资源才对另一个服务器分配。
2、对于满足的要求的服务器,先轮训的分配Executor,公平的分配。