kafka基础知识点总结
https://blog.csdn.net/qq_25445087/article/details/80270790 需要学习.
1.kafka简介
kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。最新版本是1.1.0,用Scala2.12开发的版本需要支持jdk1.8及以上
2.kafka基本原理
基本术语:
broker:一个kafka集群由一个或者多个broker组成,集群的基本组成单位
topic:kafka中用来维护的一类消息
partition:每个topic可以包含多个分区,每一个分区都存在于各个broker中,但是一个分区只能选取一个broker作为主节点(在有多个备份的情况下)
producer:生产并发送消息到topic中
consumer:消费topic中的消息
consumer group:每个consumer属于一个特定的consumer group,对于一个topic中的消息只能被一个consumer group中的一个consumer消费
消息消费有queen和发布-订阅两种模式,kakfa在同一个consumer group下是queen模式,在不同consumer group下是发布-订阅模式
kafka中的数据流向图:
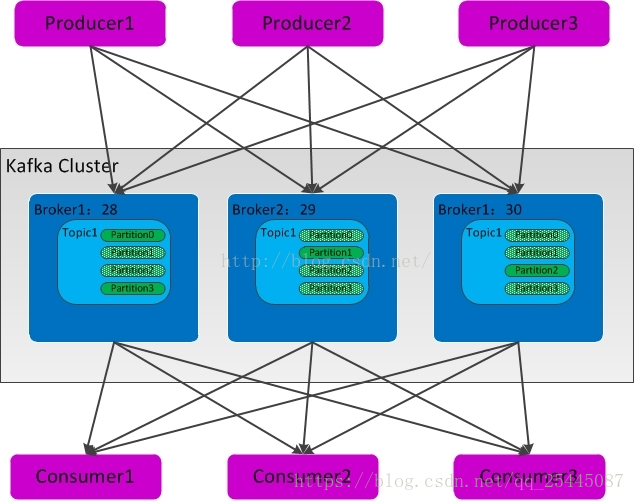
producer生产数据发送到kafka,consumer从kafka消费数据
其中每个topic可以有一个或者多个partition,每个partition就是一个队列,数据在其中是有序且不可变的,新消息被追加到partition的尾部,每条消息都有一个连续的序号叫做offset,kafka通过offset来控制消息的消费,可以防止重复消费
kafka可以将消息保存指定的时间,可以通过配置文件设置,因此kafka中的消息可以被重复消费。
partition
Kafka集群中,一个Topic的多个partitions被分布在多个server上。每个server负责partitions中消息的读写操作。每个partition可以被备份到多台server上,以提高可靠性。
每一个patition中有一个leader和若干个follower。leader处理patition内所有的读写请求,而follower是leader的候补。如果leader挂了,其中一个follower会自动成为新的leader。每一台server作为担任一些partition的leader,同时也担任其他patition的follower,以此达到集群内的负载均衡。
producer
producer发布消息到指定的topic中,producer决定将消息发送到具体的哪一个partition。比如基于”round-robin”方式实现简单的负载均衡或者通过其他的一些算法等.
3.集群部署
1.从官网下载kafka的安装包,地址为:
http://kafka.apache.org/downloads.html
需要先安装jdk
2.如果要安装集群,需要配置kafka和zookeeper,若是安装单机,直接启动即可,启动命令为:
启动zookeeper:
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
启动kafka:
nohup bin/kafka-server-start.sh config/server.properties &
3.集群安装配置,首先修改zookeeper配置文件

集群上每台机器上的配置文件相同
创建myid文件,进入/root/kafka/zookeeper,创建myid文件,将三个服务器上的myid文件分别写入1,2,3,如图:


最后启动每台机器上的zookeeper,都启动成功后,没有报错,zookeeper集群搭建成功
4.配置kafka集群配置文件,修改config/server.properties
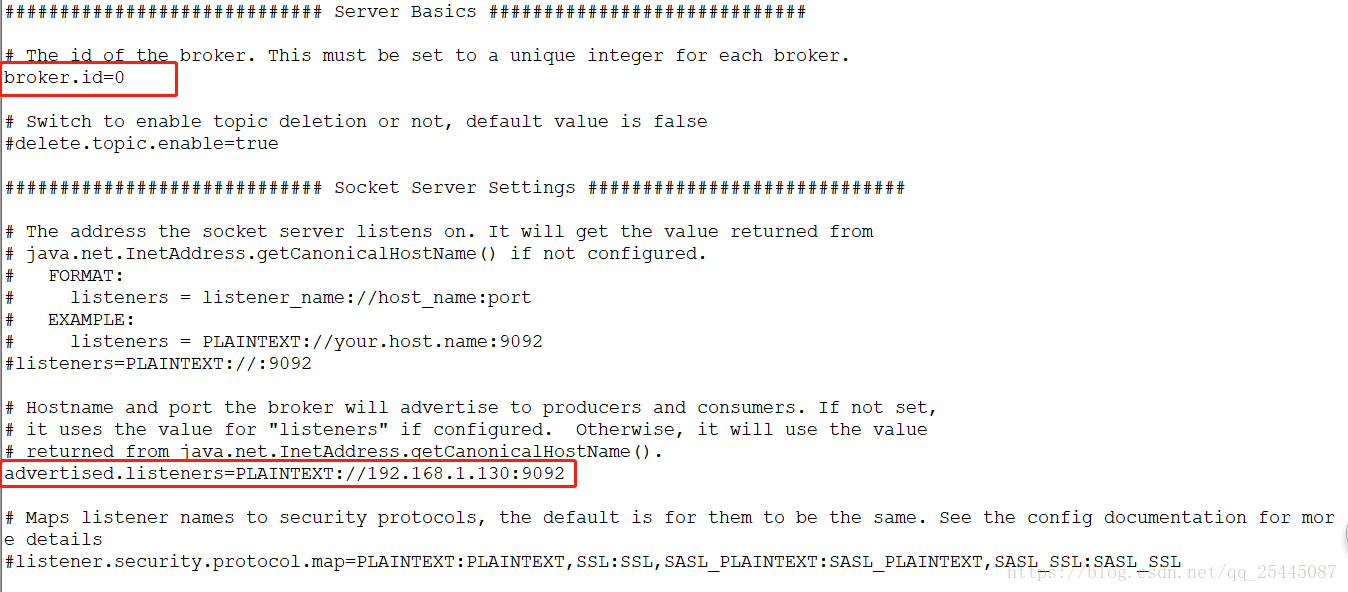

主要修改三个地方,broker.id是每个broker的标识,从零开始,0,1,2,3......
advertised.listeners是kafka的监听地址,可以通过配置hosts文件来识别
zookeeper.connect是zookeeper的连接地址
最后启动kafka,每台启动后不报错表示集群启动成功。
4.常用命令
查看topic:
bin/kafka-topics.sh --zookeeper node01:2181 --list
创建topic:
bin/kafka-topics.sh --zookeeper node01:2181 --create --topic t_cdr --partitions 30 --replication-factor 2
查看指定topic信息;
bin/kafka-topics.sh --zookeeper node01:2181 --describe --topic t_cdr
生产数据:
bin/kafka-console-producer.sh --broker-list node86:9092 --topic t_cdr
消费数据:
bin/kafka-console-consumer.sh --zookeeper node01:2181 --topic t_cdr --from-beginning
修改topic分区数:
bin/kafka-topics.sh --zookeeper node01:2181 --alter --topic t_cdr --partitions 10
删除topic,只会删除zookeeper中的信息,消息文件需要手动删除
bin/kafka-run-class.sh kafka.admin.DeleteTopicCommand --zookeeper node01:2181 --topic t_cdr
查看topic某分区偏移量最大(小)值
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic hive-mdatabase-hostsltable --time -1 --broker-list node86:9092 --partitions 0
查看消费者群组:
./kafka-consumer-groups.sh --bootstrap-server 192.168.1.132:9092 --list
进入zookeeper命令查看kafka相关信息
bin/zookeeper-shell.sh
重启集群某个节点后,重新进行leader的负载均衡:
./kafka-preferred-replica-election.sh --zookeeper id:port
查看某个topic的offset:
./kafka-consumer-offset-checker.sh --group console-consumer-52639 --topic test1 --zookeeper 172.16.140.9:2181