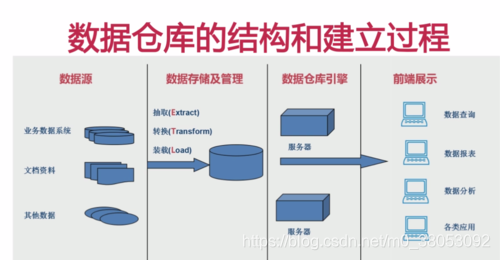
数据仓库:是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用于支持企业或组织的决策分析处理。
-
OLTP应用
联机事务处理,关注的是事物的处理,典型的OLTP应用是银行转账,一般操作频率会比较高; -
OLAP应用
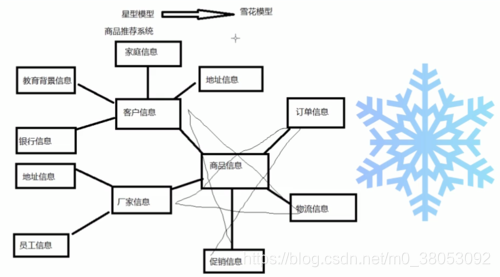
联机分析处理,主要面向的是查询,典型的OLAP应用是商品推荐系统,一般不会做删除和更新,数据一般都是历史数据。 -
数据仓库中的数据模型:星型模型和雪花模型。星型模型是数据仓库最基本的数据模型,雪花模型是在星型模型的基础上发展起来的。
-
hive执行生命周期:
- 编写hql语句
- 解析器进行语法分析
- 编译器生成hql执行计划
- 优化器生成最佳执行计划
- 执行
-
Hive的管理之CLI方式:
- CLI(命令行)方式 (hive命令行交互模型) 清屏 Ctrl + L 或者 !clear;
- 查看数据仓库中的表 show tables;
- 查看数据仓库中内置的函数 show functions;
- 查看表结构 desc 表名;
- 查看HDFS上的文件 dfs -ls 目录;
- 执行操作系统的命令 !命令;
- 执行HQL语句 select * from test1;
- 执行SQL脚本 source 脚本操作系统路径; 如: source /root/my.sql;
- 开启hive的静默模型 hive -S 在启动CLI时,加上-S参数,将进行hive命令行交互模型;
- 不进行hive交互模型运行命令 hive -e ‘命令’; 可以配合-S静默模型,如: hive -S -e ‘命令’
-
Hive的管理之web界面方式
- Web界面方式 启动方式: hive --service hwi &
- 端口号: 9999 通过浏览器来访问: http://<IP地址>:9999/hwi/
- 启动需要安装hive-hwi-*.war 可以从相应的源码中获取,进行 web源码在:
apache-hive-0.13.0-src\hwi\web 将web打包成war文件: jar cvfM0
hive-hwi-0.13.0.war -C web/ . (先要进入hwi目录下)
需要配置hive/conf/hive-site.xml说明在:
https://cwiki.apache.org/confluence/display/Hive/HiveWebInterface
-
hive复杂结构类型
-
复杂数据类型的应用:
数组:create table student (sid int, sname string, grade
array–几个成绩)集合类型:
create table student1 (sid int, sname string, grade
map<string,float>–一个科目的成绩);create talbe student3 (sid int, sname string, grades
array<map<string,float>>–所有科目的成绩);结构类型:结构有点相似与数组,但是数组中的值必须是相同数据类型的,而结构中的数据类型可以不同。
create table student4 (sid int, info
structname:string,age:int,sex:string -
Hive的数据类型之时间数据类型
- 时间类型:
Timestamps:一个与时区无关的,存储的形式是一个UNIX以来偏移量,也就是一个数字(长整型);
Dates:描述了一个特定的日期(年、月、日)以{YYYY-MM-DD} 的格式,不足两位以0补齐。
- 时间类型:
-
hive数据存储特征
- 基于HDFS(Hadoop的数据仓库)
- 没有专门的数据存储格式
- 存储结构主要包括:数据库,文件,表,视图
- 可以直接加载文本文件(.TXT文件等)
- 创建表时,指定Hive数据的列分割符与行分隔符
hive表包含:
-
table 内部表
-
Partiton 分区表
-
External Table 外部表
-
Bucket Table 桶表
-
内部表
:类似于数据库中的Table 在Hive中,每个table都有一个相应的目录存储数据。即hdfs上的目录 所有的table数据都保存在这个目录中。 删除表的时候,元数据和数据都会被删除。
创建内部表:
create table t1(tid,int,tname string,age int);
这个表自动保存 在hdfs的user/hive目录下 ;可以在创建表的时候指定存储位置:
create table t2(tid,int,tname string,age int) location
‘/mytable/hive/t2’;
在创建t1,t2并没有指定列之间的分隔符,默认为制表符 可以在创建表的时候进行指定:
create table t3(tid,int,tname string,age int)row format delimited
fields termiated by ‘,’;(CSV)
表的结构,里面没有任何数据 select * from sample_data;
用已有的表创建 一张新的表
create table t4 as select * from sample_data; select * from t4;
对表进行修改:
alter table t1 add columns(english int); desc t1;
删除表进入回收站:
drop table t1;
-
分区表
作用: 分区表 在数据量特别大的时候,可以根据一定的条件对数据进行分区,这样可以减少扫描的数量,降低查询速度 hive中,表中的partition对应表下的一个目录 可以使用执行计划语句 explain …
.比较创建分区后的不同执行过程:create table partition_table(sid int ,sname string) partitioned
by(gender string) row format delimited fields termimated by ‘,’;insert into table partition_table partition(gender=‘M’) select
sid,sname from t1 where gender =‘M’; insert into table partition_table
partition(gender=‘F’) select sid,sname from t1 where gender =‘F’;执行计划: explain select * from table
-
外部表
外部表(External Table) -指向已经在HDFS中存在的数据,可以创建Partition -它和内部表在元数据的组织上是相同的,而实际数据的存储则又较大的差异 ;外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接。
创建外部表:dfs -put student01.txt /input
dfs -put student02.txt /input
dfs -put student03.txt /input
create external table external_student (sid int, sname string, age int) row format delimited fields terminated by ‘,’ location ‘/input’; --数据源的HDFS文件目录 -
桶表
桶表(Bucket Table) 桶表是对数据进行哈希取值,然后放到不同文件存储。也就是说,桶表中的数据,是通过哈希运算后,将其打散,再存入文件当中,这样做会避免造成热块,从而提高查询速度。
桶表创建–案例:
create table bucket_table (sid int, sname string, age int) clustered by (sname) into 5 buckets; //创建一个桶表,这个桶表是以sname作为哈希运算,运算后的结果放到5个桶中
-
hive视图
视图操作和表一样,Hive中的视图不存储数据,只是虚表。oracle和mysql中有一种物化视图,是存储有实际数据的,能提高查询效率。 视图是一种虚表,是一个逻辑概念,可以跨越多张表 视图建立在已有表的基础上,这些表称为基表,视图可以简化复杂的查询
create view empinfo as select e.empno,e.ename,e.sal,e.sal*12
annlsal,d.dname from emp e,dept d where e.deptno=d.deptno;
