版权声明:笔者博客文章主要用来作为学习笔记使用,内容大部分来自于自互联网,并加以归档整理或修改,以方便学习查询使用,只有少许原创,如有侵权,请联系博主删除! https://blog.csdn.net/qq_42642945/article/details/89677855
机器学习的典型例子
根据用户的国际/年龄/薪水来推算用户是否会购买商品
自变量:国际/年龄/薪水
因变量:购买商品
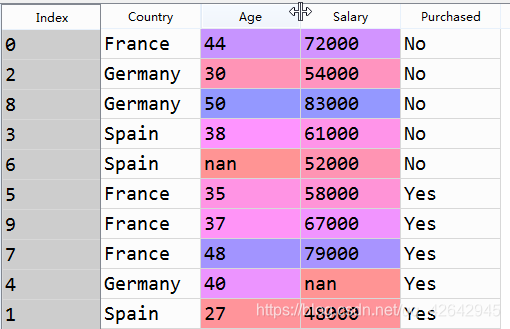
取自变量:
# Data Preprocessing Template
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
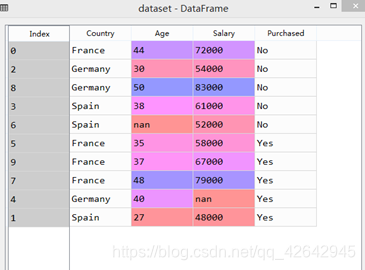
dataset = pd.read_csv('Data.csv')
# dataset导入的数据集
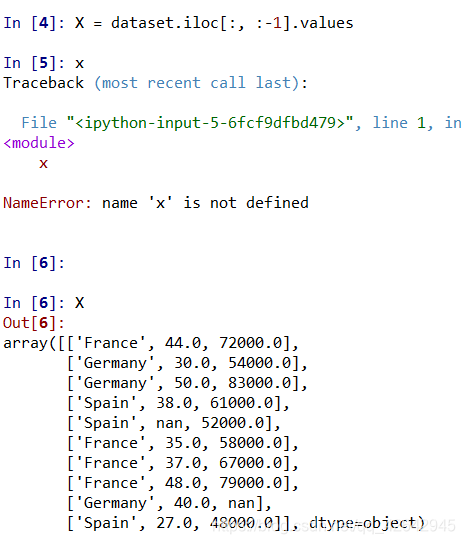
X = dataset.iloc[:, :-1].values
# iloc 数据集里面的某一些行(列)
# [:, :-1] [行数,列数] :表示取所有的行(列)
# :-1 表示我们会取除了最后一列的其余所有的列 也就是Purchased(是否购买)列
# .values 取这些列的值
运行结果
取因变量:
y = dataset.iloc[:, 3].values
#取所有行,取第三列(索引为3)
运行结果

问题:缺失数据
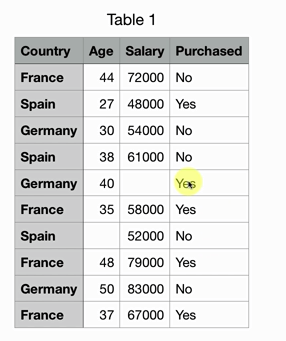
解决方法:取其他行的平均值代替该缺失值
from sklearn.model_selection import train_test_split
ctrl+i 查看帮助
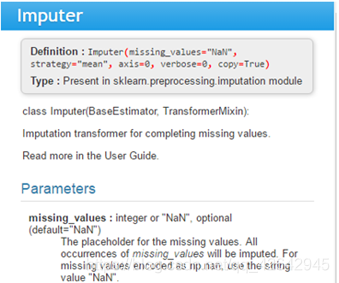
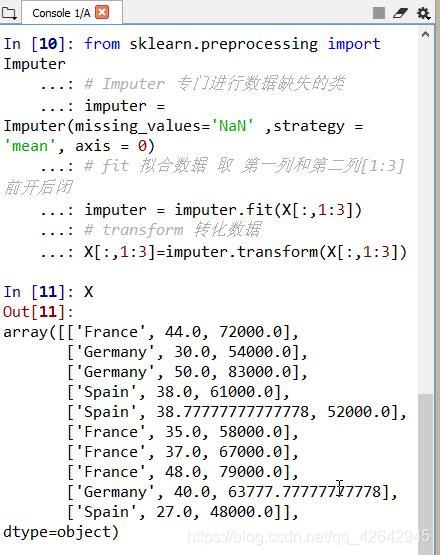
from sklearn.preprocessing import Imputer
# Imputer 专门进行数据缺失的类
imputer = Imputer(missing_values='NaN' ,strategy = 'mean', axis = 0)
# fit 拟合数据 取 第一列和第二列[1:3] 前开后闭
imputer = imputer.fit(X[:,1:3])
# transform 转化数据
X[:,1:3]=imputer.transform(X[:,1:3])
Definition :
Imputer(
missing_values="NaN",
strategy="mean",
axis=0,
verbose=0,
copy=True
)
Parameters 参数
missing_values : integer or “NaN”, optional (default=“NaN”)
缺失的数据
strategy : string, optional (default=“mean”)
策略
The imputation strategy.
If “mean”, then replace missing values using the mean along the axis.
取平均值,代替缺失值
If “median”, then replace missing values using the median along the axis.
取中位数,代替缺失值
If “most_frequent”, then replace missing using the most frequent value along the axis.
取最常出现的值,代替缺失值
axis : integer, optional (default=0)
The axis along which to impute.
If axis=0, then impute along columns.
axis=0 取列的平均值
If axis=1, then impute along rows.
axis=0 取行的平均值
数据分类
#分类数据
from sklearn.preprocessing import LabelEncoder
#LabelEncoder(标签编码器) 将不同组的名称转化为数字
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
#fit_transform拟合_转化数据
运行结果:


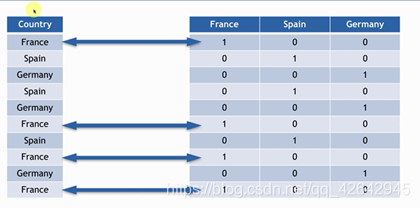
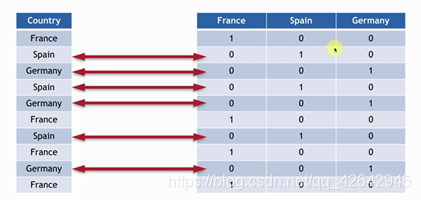
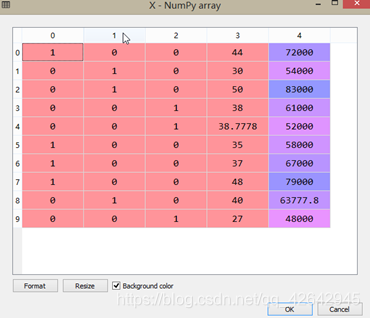
采用虚拟编码:
#分类数据
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
#LabelEncoder(标签编码器) 将不同组的名称转化为数字
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])
#fit_transform拟合_转化数据
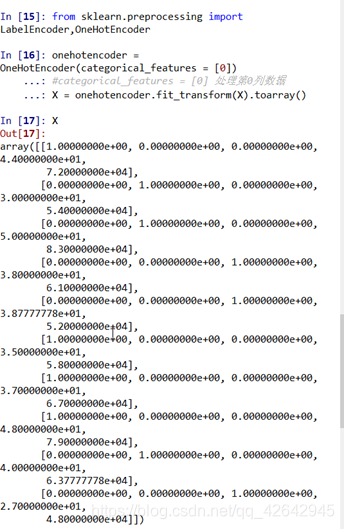
onehotencoder = OneHotEncoder(categorical_features = [0])
#categorical_features = [0] 处理第0列数据
X = onehotencoder.fit_transform(X).toarray()
处理结果
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
