数据标量化
如果需要学习的不同的数据标签之间的量纲差距太大,那么需要进行数据标量化操作,有3个主要的优势:
- 可以使梯度下降更快
- 躲避“NaN陷阱”,数据中有些数值可能超过了计算机的表示范围,把这些数据引入计算过程,会降低运算速度,影响计算结果
- 使得模型的权重对每个特征都比较适应。
一般的处理方法为:
数据值减去平均值,然后除以标准差。
处理极端的离群值
如果数据存在较多的极端值,比如下图:
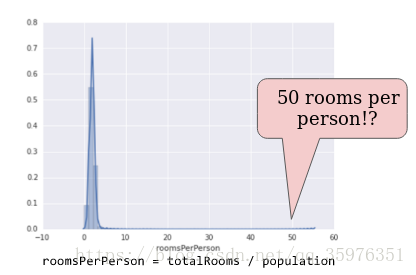
x轴的数据过长,但是数据主要集中在前一部分。
一种处理方式为取对数:

但是,这样做还是会有较长的尾部数据。因此,还需要进行一个截断操作,去掉开头和结尾的区间的数据:

数据分档
下图表示了数据集中,纬度对房价的影响。主要数据集中在34度和38度附近。
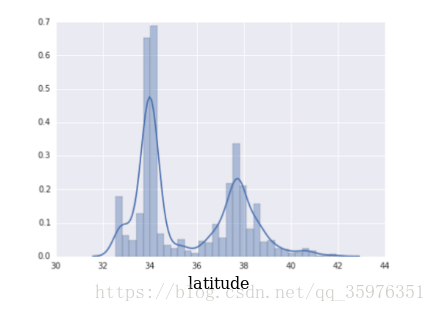
单独使用浮点型数据,对房价的预测不恰当。因为纬度和房价之间不是线性关系。为了更好的描述二者之间的关系,进行数据分档操作:

因此,这个数据集形成了一个11维的向量,如果表示37.4度,可以使用:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]数据清洗
现实世界中的数据不总是可靠的,具体有下面几个因素:
- 缺失的数据。比如人们忘记录入数据了
- 重复的数据。
- 不好的标签。比如在图片分类的时候,由于失误而写错了标签
- 不好的特征值。特征值可能存在不合理的情况。比如活人的年龄出现了500岁。。。
一般来说,需要自己编写程序处理这些数据。为了更好的了解了解数据集,一般使用直方图来观测数据。另外,下面几个数据也可以很好的描述:
- 最大、最小值
- 平均值、中位数
- 方差
一般准则
- 大体知道我们要处理的数据应该是什么样子的
- 确认数据符合我们的预期
- 再次确认训练的数据符合其他的一些资源的数据
代码:
进行了分段和交叉特征。。。
import math
import os
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.INFO)
pd.options.display.max_rows = 10
if not os.path.exists('data.csv'):
california_housing_dataframe = pd.read_csv(
"https://storage.googleapis.com/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.to_csv('data.csv')
else:
california_housing_dataframe = pd.read_csv('data.csv')
# 乱序操作
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index)
)
def preprocess_features(california_housing_dataframe):
selected_features = california_housing_dataframe[
[
'latitude',
'longitude',
'housing_median_age',
'total_rooms',
'population',
'households',
'median_income'
]
]
processed_feature = selected_features.copy()
# 新增特征列
processed_feature['rooms_per_person'] = (
california_housing_dataframe['total_rooms'] /
california_housing_dataframe['population']
)
return processed_feature
def preprocess_targets(california_house_dataframe):
output_targets = pd.DataFrame()
# 控制数据范围
output_targets['median_house_value'] = (
california_house_dataframe['median_house_value'] / 1000.0
)
return output_targets
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
print("Training example summary:")
display.display(training_examples.describe())
print("Validation examples summary:")
display.display(validation_examples.describe())
print("Training targets summary:")
display.display(training_targets.describe())
print("Validation examples summary:")
display.display(validation_targets.describe())
def get_quantitle_based_boundaries(features_values, num_buckets):
boundaries = np.arange(1.0, num_buckets) / num_buckets
quantitles = features_values.quantile(boundaries)
return [quantitles[q] for q in quantitles.keys()]
def construct_feature_columns():
households = tf.feature_column.numeric_column('households')
longitude = tf.feature_column.numeric_column('longitude')
latitude = tf.feature_column.numeric_column('latitude')
housing_median_age = tf.feature_column.numeric_column('housing_median_age')
median_income = tf.feature_column.numeric_column('median_income')
rooms_per_person = tf.feature_column.numeric_column('rooms_per_person')
# 把household分成7个数据段
bucketized_households = tf.feature_column.bucketized_column(
households, boundaries=get_quantitle_based_boundaries(
training_examples['households'], 7
)
)
# 把longitude分成10个数据段
bucketized_longitude = tf.feature_column.bucketized_column(
longitude, boundaries=get_quantitle_based_boundaries(
training_examples['longitude'], 10
)
)
# 把latitude分成10个数据段
bucketized_latitude = tf.feature_column.bucketized_column(
latitude, boundaries=get_quantitle_based_boundaries(
training_examples['latitude'], 10
)
)
# 把housing_median_age分成10个数据段
bucketized_housing_median_age = tf.feature_column.bucketized_column(
housing_median_age, boundaries=get_quantitle_based_boundaries(
training_examples['housing_median_age'], 7
)
)
# 把median_income分成10个数据段
bucketized_median_income = tf.feature_column.bucketized_column(
median_income, boundaries=get_quantitle_based_boundaries(
training_examples['median_income'], 7
)
)
# 把rooms_per_person分成10个数据段
bucketized_rooms_per_person = tf.feature_column.bucketized_column(
rooms_per_person, boundaries=get_quantitle_based_boundaries(
training_examples['rooms_per_person'], 7
)
)
# Make a feature column for the long_x_lat feature cross
long_x_lat = tf.feature_column.crossed_column(
set([bucketized_longitude, bucketized_latitude]), hash_bucket_size=1000
)
feature_columns = set([
bucketized_longitude,
bucketized_latitude,
bucketized_housing_median_age,
bucketized_households,
bucketized_median_income,
bucketized_rooms_per_person,
long_x_lat
])
return feature_columns
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
ds = Dataset.from_tensor_slices((dict(features), targets))
ds = ds.batch(batch_size).repeat(num_epochs)
if shuffle:
ds = ds.shuffle(10000)
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def train_model(learning_rate,
steps,
batch_size,
feature_columns,
training_examples,
training_targets,
validation_examples,
validation_targets,
periods=10):
steps_per_period = steps // periods
my_optimizer = tf.train.FtrlOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 50)
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=feature_columns,
optimizer=my_optimizer,
model_dir='./model'
)
training_input_fn = lambda: my_input_fn(training_examples,
training_targets['median_house_value'],
batch_size=batch_size)
predict_training_input_fn = lambda: my_input_fn(training_examples,
training_targets['median_house_value'],
batch_size=batch_size)
predict_validation_input_fn = lambda: my_input_fn(validation_examples,
validation_targets['median_house_value'],
batch_size=batch_size)
print("Training model...")
print("RMSE (on training data):")
training_rmse = []
validation_rmse = []
for period in range(0, periods):
print('\n------------------', period, '---------------------\n')
linear_regressor.train(
input_fn=training_input_fn,
steps=steps_per_period,
)
# 计算预测值
training_predictions = linear_regressor.predict(predict_training_input_fn)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
validation_prediction = linear_regressor.predict(input_fn=predict_validation_input_fn)
validation_prediction = np.array([item['predictions'][0] for item in validation_prediction])
# 计算最小二乘损失
training_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(training_predictions, training_targets)
)
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(validation_prediction, validation_targets)
)
print("period %02d:%0.2f" % (period, training_root_mean_squared_error))
training_rmse.append(training_root_mean_squared_error)
validation_rmse.append(validation_root_mean_squared_error)
print("Model training ")
plt.ylabel("RMSE")
plt.xlabel("Periods")
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(training_rmse, label="training")
plt.plot(validation_rmse, label="validation")
plt.legend()
return linear_regressor
if __name__ == '__main__':
train_model(
learning_rate=1.0,
steps=500,
batch_size=100,
feature_columns=construct_feature_columns(),
training_examples=training_examples,
training_targets=training_targets,
validation_examples=validation_examples,
validation_targets=validation_targets
)