最近,实验室的老师要做关于对抗样本的PPT,其中需要统计ICLR会议关于对抗样本的文章,因此就学了一点点爬虫~记录一下过程。
1.爬取网址:https://openreview.net/group?id=ICLR.cc/2019/Conference(如果需要其它年份的,直接修改2019为其它年份即可),按F12,如下图:
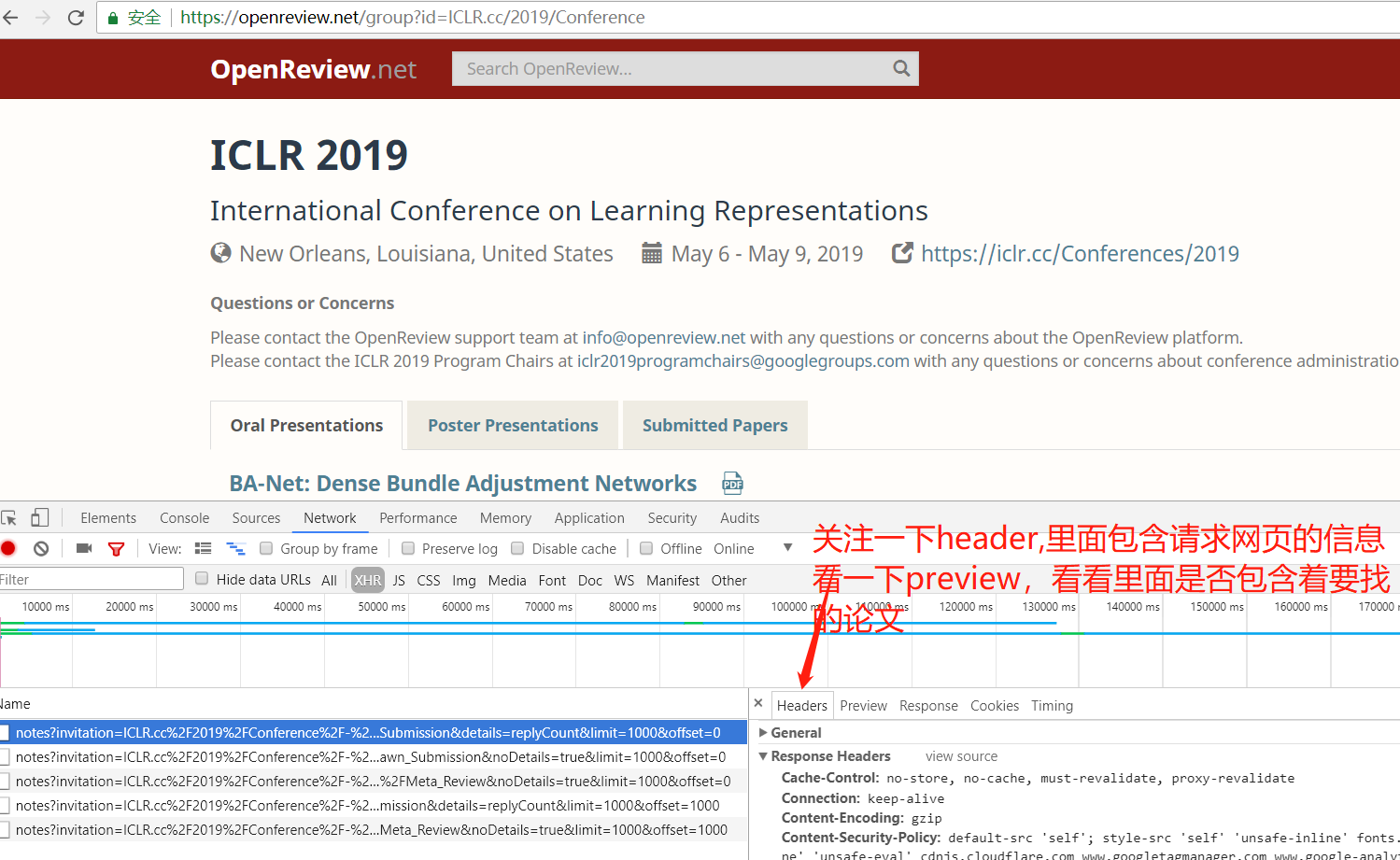
2.点开preview看一下(这个里面包含着1000篇论文),每一篇都包含着论文的作者,标题,以及abstract等等)


3.再看看header,它可以告诉我们爬取网页的头部信息:

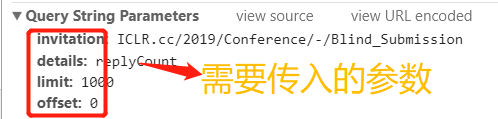
基本上从头部信息可以获取到,invitatio表示论文的投稿信息(现在这个就是表示盲审阶段的论文),offset表示偏移,论文数量一共1419篇,需要爬取offset为0和offset为1000得两个网页。
4.编写代码
4.1. get_data.py


1 import json 2 import requests 3 from requests.exceptions import RequestException 4 from urllib.parse import urlencode 5 6 def get_page_index(invitation,offset): 7 data={ 8 'invitation': invitation,#复制过来的时候要把空格去掉 9 'details': 'replyCount', 10 'limit': '1000', 11 'offset': offset, 12 } 13 url='https://openreview.net/notes?'+urlencode(data) 14 15 try: 16 response=requests.get(url) 17 if response.status_code==200: 18 return response.text 19 return None 20 except RequestException: 21 print("请求索引页出错") 22 def parse_page_index(html): 23 data = json.loads(html) 24 if data and 'notes' in data: 25 for item in data['notes']: 26 yield item 27 def save_data(data,path): 28 # python列表转json数组并写入文件 29 with open(path,'w') as f: 30 json.dump(data,f) 31 print("存储成功") 32 def main(name_path,key_path,invitation): 33 34 #收集论文名称 35 names=[] 36 key_words=[] 37 for offset in [0,1000]: 38 try: 39 html=get_page_index(invitation,offset) 40 for index, item in enumerate(parse_page_index(html)): 41 try: 42 print("offset:{0} index:{1}".format(offset, index)) 43 names.append(item['content']['title']) 44 key_words.extend(item['content']['keywords']) 45 except Exception as e: 46 print("error!") 47 except Exception as e: 48 break 49 50 51 save_data(names,name_path) 52 save_data(key_words,key_path) 53 # 'ICLR.cc/2018/Conference/-/Blind_Submission' 54 if __name__ == '__main__': 55 main(name_path='./data/2016title.json',key_path='./data/2016key_words.json', 56 invitation='ICLR.cc/2016/conference/-/submission')
4.2 make_cloud.py
1 import json 2 from wordcloud import WordCloud 3 import matplotlib.pyplot as plt 4 def plot_word_cloud(): 5 with open('./data/2018key_words.json','r') as f: 6 data=json.load(f) 7 mytext="" 8 for item in data: 9 mytext+=(" "+item) 10 print("yes") 11 wordcloud = WordCloud().generate(mytext) 12 plt.imshow(wordcloud, interpolation='bilinear') 13 plt.axis("off") 14 # plt.savefig('3.png', dpi=200) # 指定分辨率保存 15 plt.show() 16 17 def count_adversary(): 18 with open('./data/2017title.json','r') as f: 19 data=json.load(f) 20 print(len(set(data))) 21 cnt=0 22 for item in data: 23 if "adversarial" in item or "example" in item or "defense" in item or 'attack' in item\ 24 or "Adversarial" in item or "Example" in item or "Defense" in item or 'Attack' in item\ 25 or "Vulnerability" in item or "Robust" in item: 26 if "Generative Adversarial Networks" in item: 27 # print("**********{0}".format(item)) 28 pass 29 else: 30 print(item) 31 cnt+=1 32 print(cnt) 33 34 count_adversary()
5.生成词云效果如下:
