NLP笔记 --- 词性标注
为什么要词性标注
在做文本分析,情感分析,说白了就是分析句子的成分,那么我们就需要知道句子每个词语的词性,比如Mary had a little lamb
Mary是名词(N), had是动词(V),a是冠词(Dt),little是形容词(Ad), lamb是名词(N),这些标签成为词性,接下来我们会通过一些模型来进行词性标注,最主要的模型就是HMM(隐马尔可夫模型)
1.查表法
现在我们想要标注Mary saw Will,我们现在有以下句子
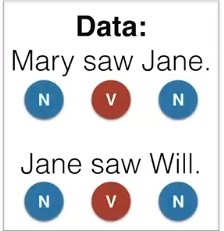
于是我们创建一个表格,行为单词的词性,列为每个单词在样本中词性的次数,如下表格
| . | N(名称) | V(动词) |
|---|---|---|
| Mary | 1 | 0 |
| saw | 0 | 2 |
| Jane | 2 | 0 |
| Will | 1 | 0 |
在表格中,我们可以看到,我们要分析的句子为Mary saw Will,句子中的Mary 表备注为了名词, saw被标注为了动词,Will被标注为了名词,因此我们可以下结论了,我们的句子为N,V,N的结构
2.双字母组
现在我们要标注的句子是Mary will see Will。我们的样本中有如下句子
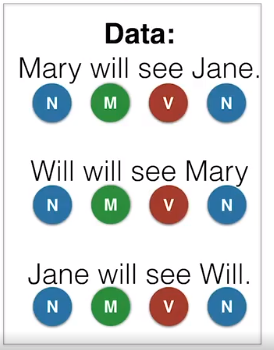
我们还用上面的查表法来创建表格
| . | N(名称) | V(动词) | M(情态动词) |
|---|---|---|---|
| Mary | 2 | 0 | 0 |
| see | 0 | 3 | 0 |
| Jane | 2 | 0 | 0 |
| Will | 2 | 0 | 3 |
根据查表,我们可以判断 Mary为名词,will 我们可以取次数最多的情态动词, see我们可以标注为动词,但是 Will呢?如果标注为次数最多的情态动词的话,但其本质为名词,这就出现问题了,这怎么办呢,这个时候我们就得考虑语境了,我们结合其上一个单词的意思,结合语境来分析句子,得到如下的表格
| . | N–M | M–V | V–N |
|---|---|---|---|
| mary–will | 1 | 0 | 0 |
| will–see | 0 | 3 | 0 |
| see–jane | 0 | 0 | 1 |
| see–mary | 2 | 0 | 3 |
| jane–will | 2 | 0 | 3 |
| will–will | 2 | 0 | 3 |
| see–will | 2 | 0 | 3 |
接下来,我们想将Mary标记为名词,那接下来will呢,因为句子中,will在Mary后面,构成了mary-will词组,根据查表,得到mary-will为N-M组合,我们可以判定这个will为情态动词,一次类推,see为动词,最后的构成了see-will词组,在表中为V-M组合,可以判定这个Will为名词,这样,我们的任务完成了,其词性为 N-M-V-M
当然,不仅可以使用双词性标注,还可以使用三词性标注,等等,这行被称为 lngram
3.隐形马尔可夫模型
我们接下来介绍一下隐马尔可夫模型,假设我们要标记的句子为 Jane will spot Will 的方式是如下表格
| N | M | V | N |
|---|---|---|---|
| Jane | will | spot | Will |
并且我们还要计算该标记的概率,首先我们需要计算的是名词后面是情态动词,情态动词后面是动词,动词后面是名词的概率分别是多少,这个概率必须很高,因为这样这个标记才有可能发生,这些概率称之为转移概率。接下来我们还要计算另外一个概率,就是在名词状体下为Jane的概率为多少,在情态动词的情况下为will的概率为多少,在动词情况下为spot的概率为多少,在名词情况下为Will的概率为多少,这个概率也必须很高,这样这个标记才有可能发生,这些概率称之为发射概率,课程字幕里翻译为发射概率,我个人的觉得应该理解为映射概率更贴切一下,为了不创造新名词,就沿用翻译字幕里的概念
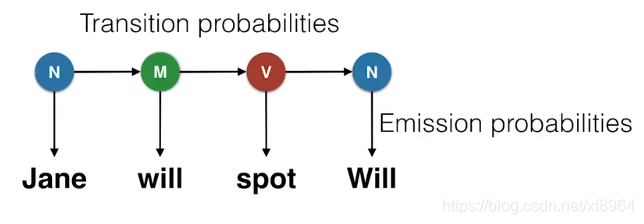
发射概率
然后我们根据一些样本来构成表格,来计算发射概率 ,
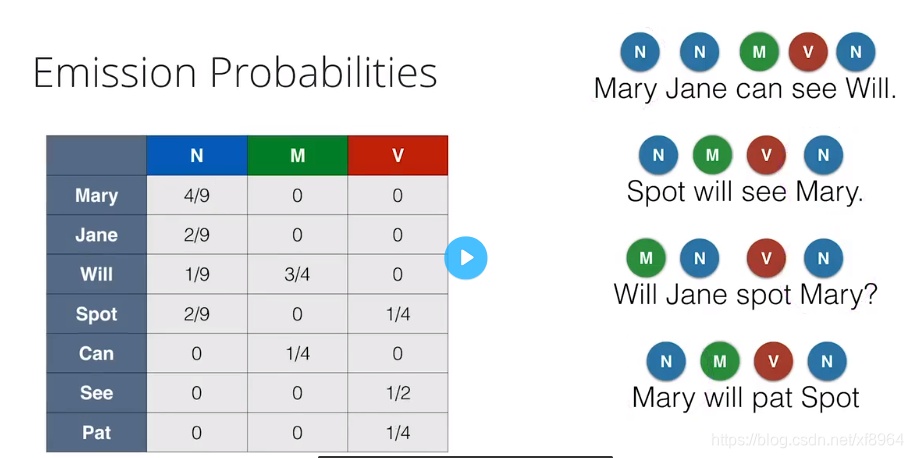
如图,右边是我们的文本样本,左边是单词的标注,我们那Marry来解释一下,4是Marry作为名词出现的次数,在所有样本中,Marry作为名词出现了4次,9是在所有样本中名词出现的总次数为9,Marry为4次,Jane为2次,Will为1次,Spot为2次,于是,我们就获得了在名词状态下为Marry的发射概率为4/9,我们用一下格式来可视化呈现发射概率
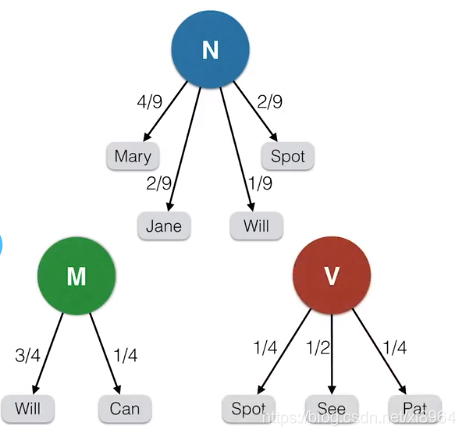
转移概率
接下来,我们计算转移概率,就是在某个词性在另一个词性后面的概率,为了方便,我们在每个句子的开头都加上<S>作为开始,在句子的结尾添加<E>作为结束,并且这些标志也当作词性,我们做出如下表格
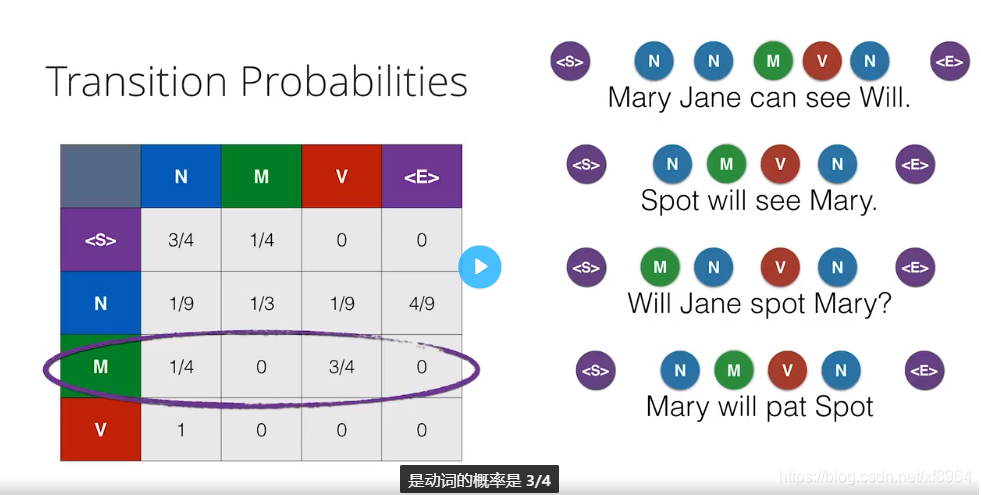
我们来解释一下左边表格的含义,我们拿 M-V 组合来示例说明 3表示情态动词后面出现过3次动词,4表示情态动词后面出现词性的总次数,情态从此后面出现过1次名词,3次动词,所以是4,我们用马尔可夫模型来表示如下(词性状态图)
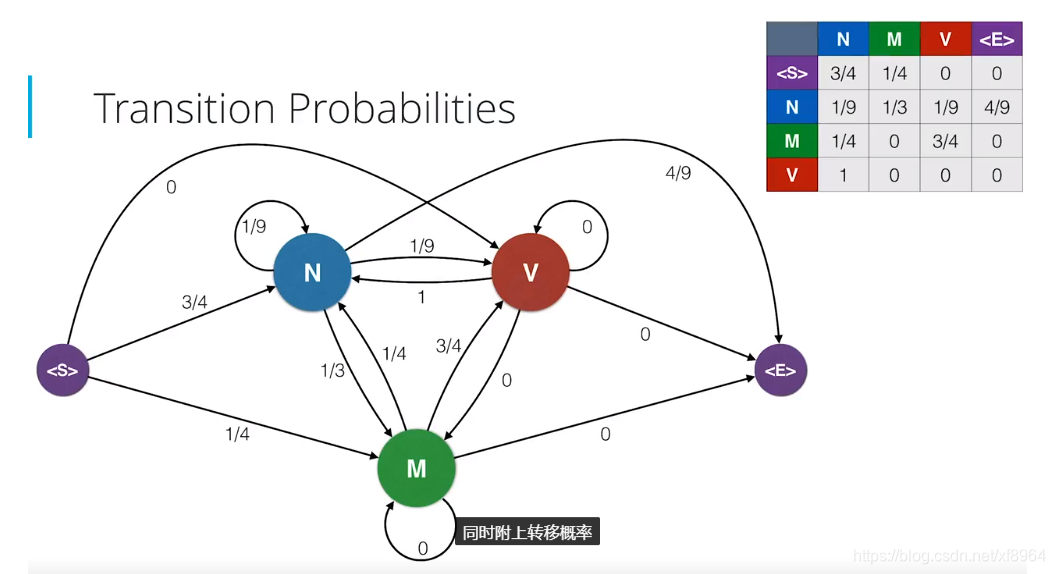
然后我们将发射概率和转移概率结合到一起就构成了隐马尔可夫模型,我们有单词,即观察结果,称之为观察结果,是因为它们是我们在阅读句子时候观察到的事物,词性称之为隐藏状态,因为它们是未知信息,我们需要根据单词进行推理。在隐形状态之间存在转移概率,在隐形状态和观察结果之间存在发射概率,这就是隐马尔可夫模型
使用隐马尔可夫生成一个句子
我们从开始状态开始,在这个隐藏状态下,根据某种概率,在各个隐藏状态下移动,假设移动了名词状态,在名词状态下有几个观察状态,那么根据发射概率,假设选择了Jane,我们记下结果,然后继续在隐藏状态之间移动,假设移动到了情态动词,那么在情态动词下有两个观察结果,我们根据发射概率,假设选择了Will,记录下结果,然后继续在隐藏状态下移动,支持移动到了动词,选择spot,然后移动到名词状态,选择Will,,最后移动到了<E>状态,表示结束。那么我们就选了句子为Jane will spot Will。接下来我们展示一些如何计算这个句子的生成概率。再从头开始,在<S>状态下选择名词的转移概率为3/4,我们记下状态,然后在该状态下我们选择Jane的发射概率为2/9,以此类推,我们得到了下图中的算式
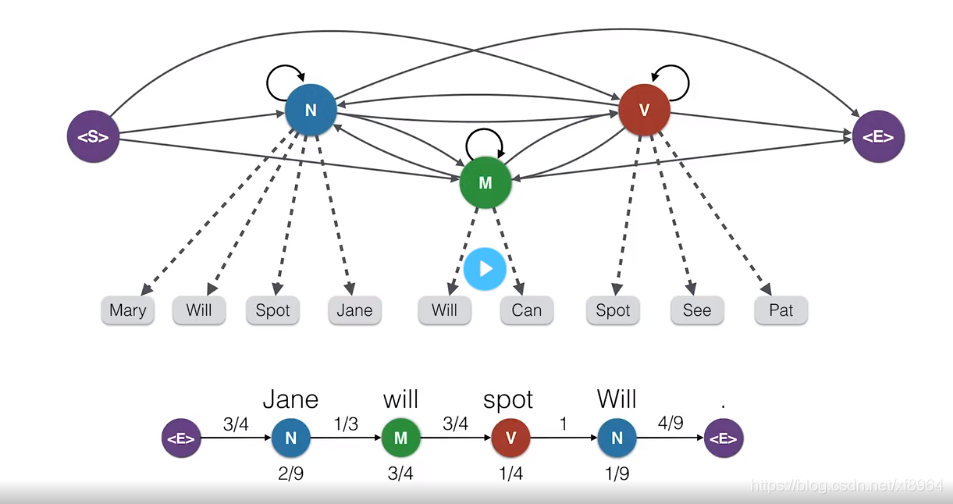
我们将其相乘,得到生成这个句子的概率为0.0003858,这个概率看起来很小,但是考虑到我们可以生成大量长度不等的句子,这个概率已经很大了,我们再来看一下生成同一个句子的不同路径,如下图
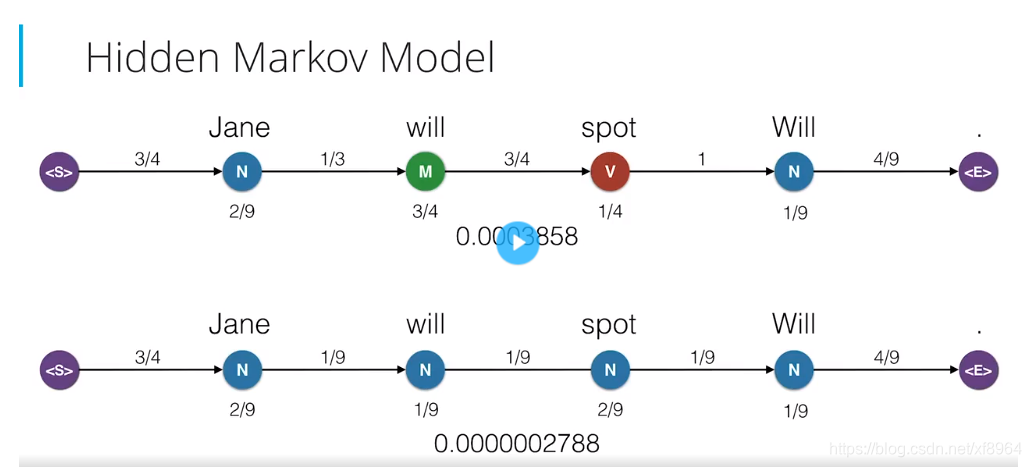
率非常小,因为这样得到的句子是不正确的,我们可以忽略掉这个路径,我们要成所有可以生成这个句子的路径中选组概率最大的组合,这称之为最大似然率,他是很多算法和人工智能的核心
4.优化路径
加入现在我们的句子Jane will spot Will中每个单词都有三种词性的可能,N, M, V那么组成这个句子的词性组合有多种呢?是3×3×3×3=81中,这里只有是个单词就这么多组合,那假如单词量大了,这个将会指数增加,不适合我们的模型,我们需要一种智能的方法,现在我们先来看看最还是的81中组合
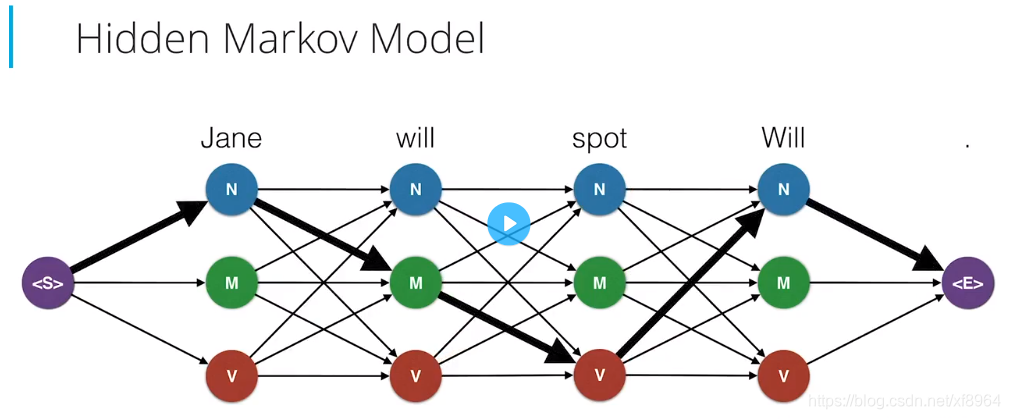
每种链接方式就代表了一种组合,其中加粗的路径表示我们正确的组合方式,我们获取路径中每个元素的顶点和边缘,通过发射和转移概率表格中的概率值,并相乘,得到概率最大的路径,如下图
现在我们将所有可能的组合连接,并标注上发射概率,会得到如下图,
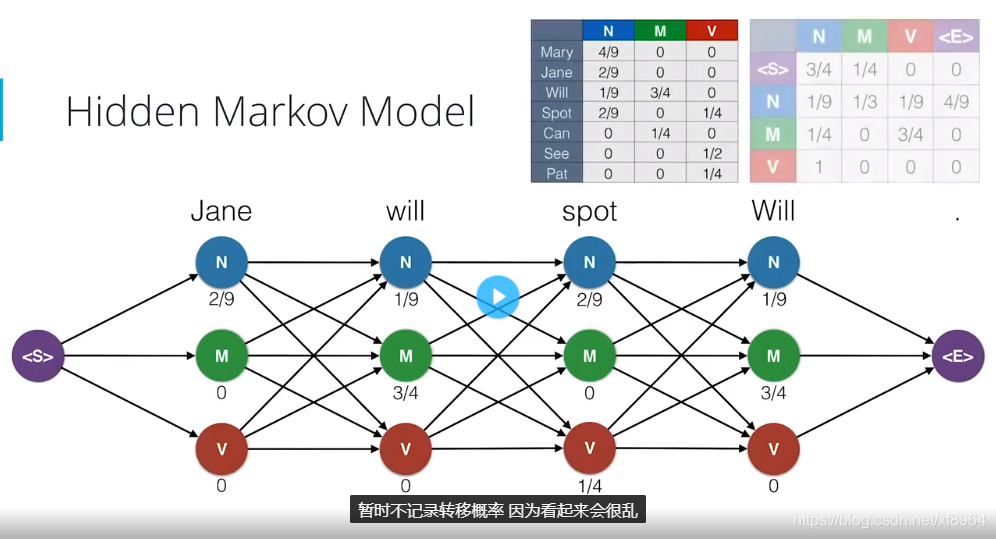
我们可以看到,有的路径的概率为0,那么就说明这个组合的概率为0,这样我们就可以删除概率为零的组合连接,并把不能到达状态<E>的路径去掉,这样就得到了很简化的组合路径,如下图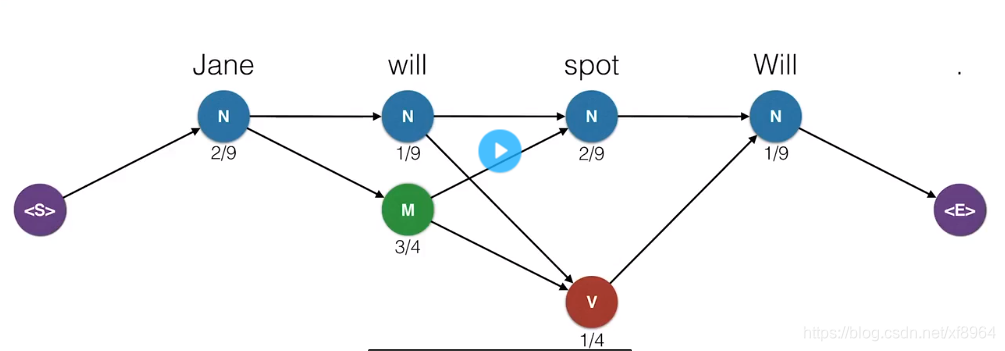
现在就只剩下4中组合了,接下来我们将转移概率也标注上,这样就可以计算组合的概率的,这个时候我们就可以得到概率最高的路径了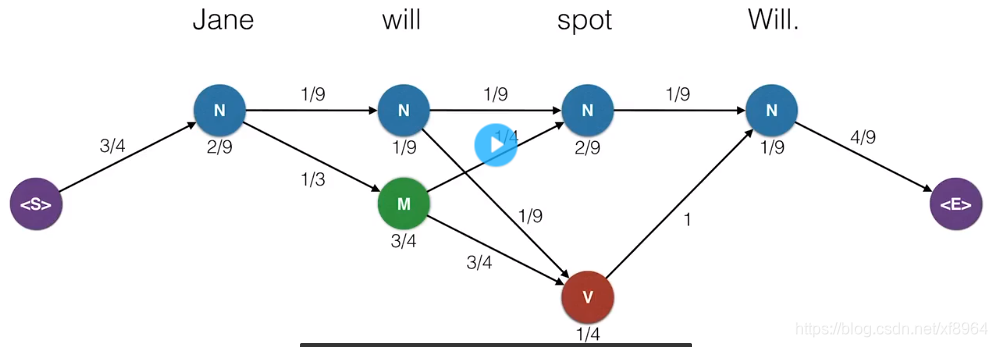
如下图,可以知道概率最高的组合,就是我们想要的词性分析结果
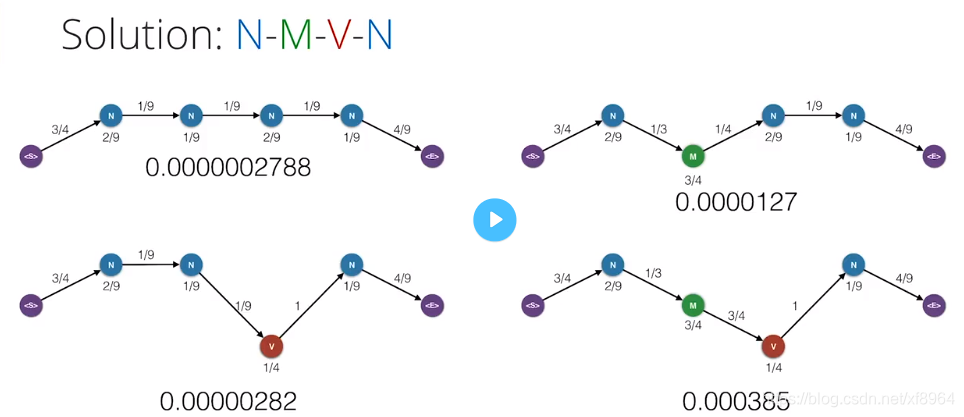
5.维特比算法推导
我们先保留所有转移概率不为0的路径连接
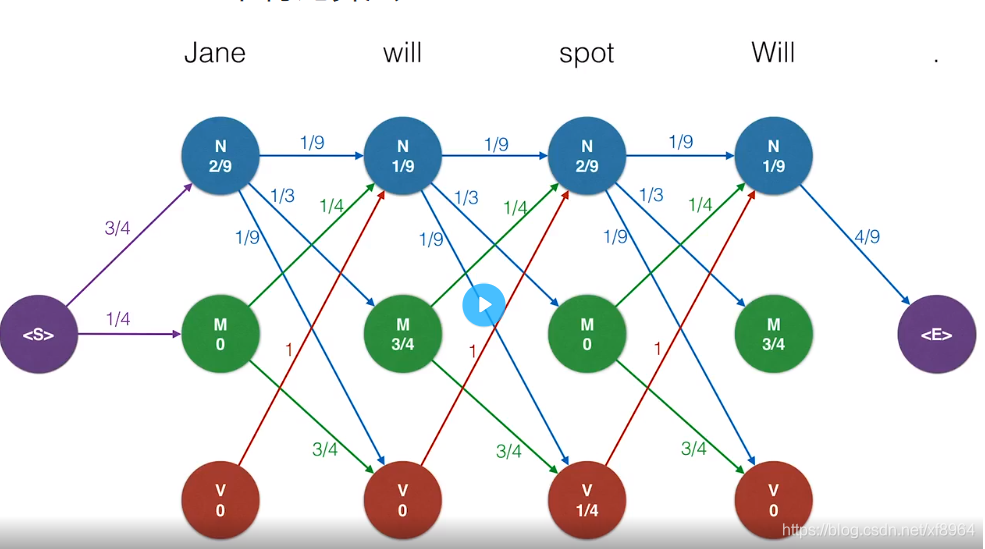
对于上表中每个点分析,并生成上方单词的所有路径中概率最高的路径,如下图中will点分析,保留概率最大的路径,删除其他较小的概率的路径
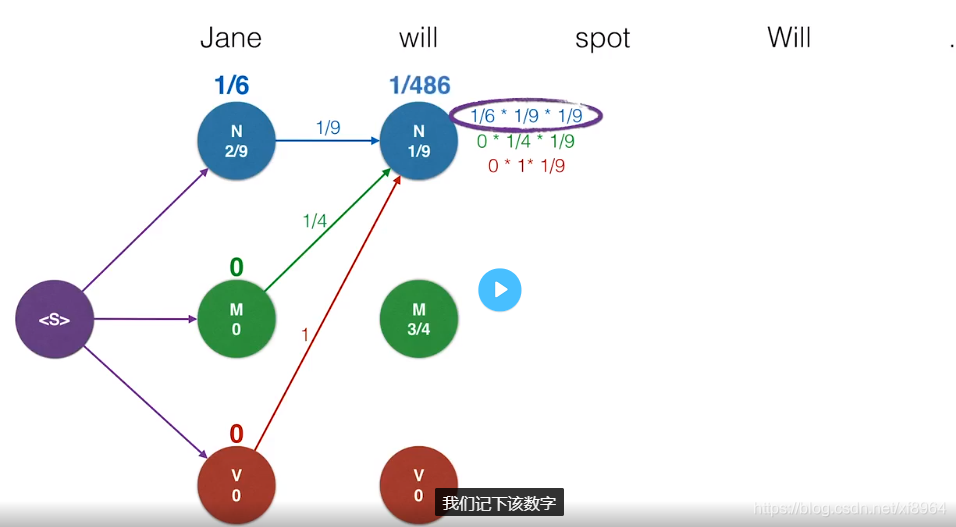
以此类推,我们就得到了最佳的路径
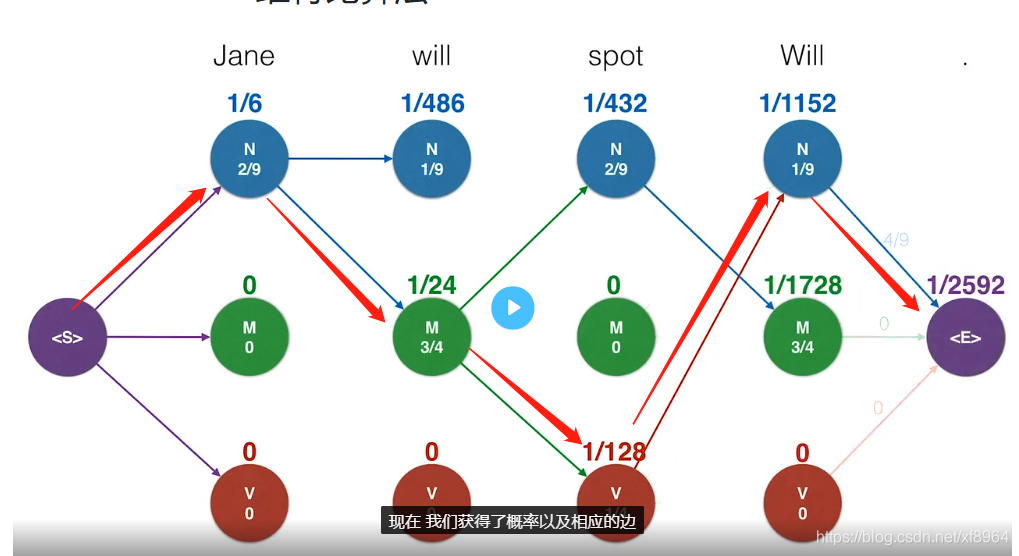
这个方法大大减少了分析量