上前几节我们简单介绍了命名体识别的算法,其实主要的方法就是HMM和CRF了,因为可以转换为标注问题,这里都可以使用HMM和CRF,本节我们将介绍另外一个重要的知识点即词性标注,同样的在宗老师的书里都有详细的讲解,这里就简单的讲解一下,那么我们下面就开始:
Part-of-speech,是重要的基础性工作,为后续的句法分析等进一步工作提供基础。分词,命名实体识别,词性标注并称汉语词法分析“三姐妹”。
词性标注即在给定的句子中判定每个词最合适的词性标记。词性标注的正确与否将会直接影响到后续的句法分析、语义分析,是中文信息处理的基础性课题之一。常用的词性标注模型有 N 元模型、隐马尔科夫模型、最大熵模型、基于决策树的模型等。其中,隐马尔科夫模型是应用较广泛且效果较好的模型之一。这里主要以HMM为主进行讲解即基于隐马尔科夫模型的词性标注方法。
汉语词性标注的困难
作为一种孤立语,汉语的特点是缺乏严格意义上的形态标志和形态变化,汉语词性标注的困难在于:
①汉语缺乏词的形态变化,不能像印欧语那样,直接从词的形态变化上来判别词的类别;
②常用词的兼类现象严重。兼类词使用频度高,兼类现象复杂多样,覆盖面广,又涉及汉语中大部分词类,使得词类歧义排除的任务困难重重;
③研究者本身的主观因素也会造成兼类词处理的困难。据统计,常见的汉语兼类现象具有以下的分布特征:其一,在汉语词汇中,兼类词数量不多,约占总词条数的 5- 11% 。其二,兼类词的使用频率很高,越常用的词,其词性兼类现象越严重。其三,兼类现
象分布不均。如何高效地进行兼类词排歧是目前词性标注面临的主要困难之一。
那什么是词性标注呢?就是在句子中的分词后加上词的性质如名词(n)、动词(v)、等等。下面给出一个矩阵就是上面么的一句话的词性标注,大家来看看,这里大家也可以自己试试,网址入口

基本上就是这样的形式,这里我们就知道了什么是词性了,那么下面我们就开始看看上面的分词的原理,上面的分词原理是基于HMM进行分词的,下面我们就详细来看看他是怎么做的,其实我们应该很熟悉了,这里的分词称为可视状态,现在我们给他们标注词性就是隐藏状态了。求出隐藏状态就可以了,这就是HMM算法呀。
基于HMM的词性标注算法
实现基于HMM的词性标注方法时,模型的参数估计是其中的关键问题。根据前面的介绍,我们可以随机地初始化HMM的所有参数,但是,这将使词性标注问题过于缺乏限制。因此,通常利用词典信息约束模型的参数。假设输出符号表由单词构成(即词序列为HMM的观察序列),如果某个对应的“词汇一词性标记”对没有被包含在词典中,那么,就令该词的生成概率(符号发生概率)为0,否则,该词的生成概率为其可能被标记的所有词性个数的倒数,即
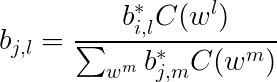
其中,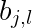
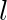
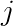
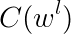
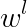

该式中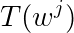
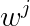
这种方法是1985年由F.Jelinek提出的,我们不妨称它为Jelinek方法。这种方法等同于用最大似然估计来估算概率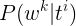
大家具体的请参考宗老师的课本吧,我这里直接介绍HMM的词性标注了:
对于词性标注任务来说,已知的单词序列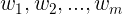
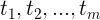
![\large [a_{ij}]](https://img-blog.csdnimg.cn/20181217180340725)
![\large [b_{ik}]](https://img-blog.csdnimg.cn/20181217180340739)
现在假设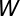
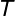

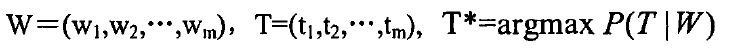
根据贝叶斯定理:
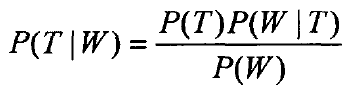
则有:
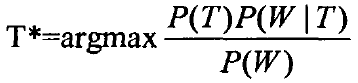
对于一个给定的词序列,其词序列的概率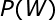
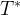
![]()
进行N元语法假设,可以得出:
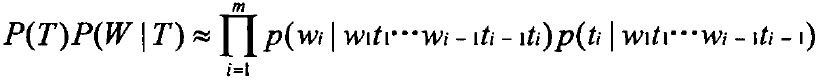
在此,我们利用二元语法模型即一阶隐马尔可夫模型,则有:
![]()
![]()
所以:
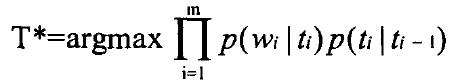
其中,
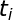
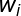
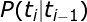
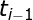
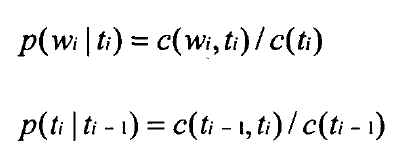
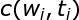
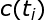
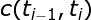

下面是一个词性标注的实例:“人们的要求与愿望”
例子:人民(n,非兼类)的(u,非兼类)要求(n/v,兼类)与(c,非兼类)愿望(n,非兼类)
对兼类词标注的计算数据:

我们在计算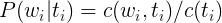
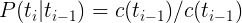
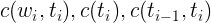
语料库是按照一定原则组织在一起的真实自然语言数据包括书面语和口语集合,土要用于研究自然语言的规律,特别是统计语言学模型的训练以及相关系统的评价和评测。语料库分为生语料库和熟语料库,生语料是指那些没有经过处理的原始文本,而熟语料是经过分词和词性标注之后的语料。因为计算所用数据需要词及其词性信息,所以必须利用熟语料库进行数据统计,如下例子:

通过计算分别求出上面的概率,然后通过维特比算法求出模型即可,这里不再详细叙述,详情请查看宗老师的书相关章节。