为什么要使用kd树
k近邻法最简单的实现是线性扫描(穷举搜索),即要计算输入实例与每一个训练实例的距离。计算并存储好以后,再查找K近邻。当训练集很大时,计算非常耗时。
为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。
什么是kd树
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树里,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合适的时候跳过距离远的点。
1989年,另外一种称为Ball Tree的算法,在kd Tree的基础上对性能进一步进行了优化。感兴趣的读者可以搜索Five balltree construction algorithms来了解详细的算法信息。
如何使用kd树
1.建立kd树
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
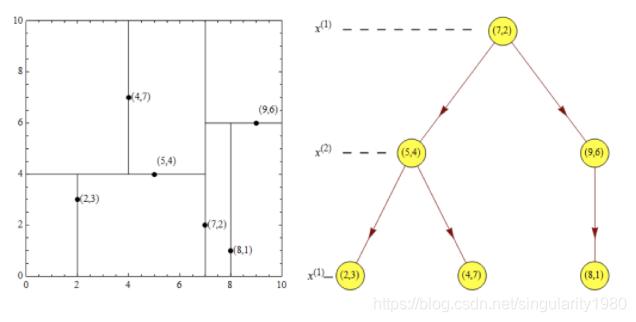
2.最近邻域搜索
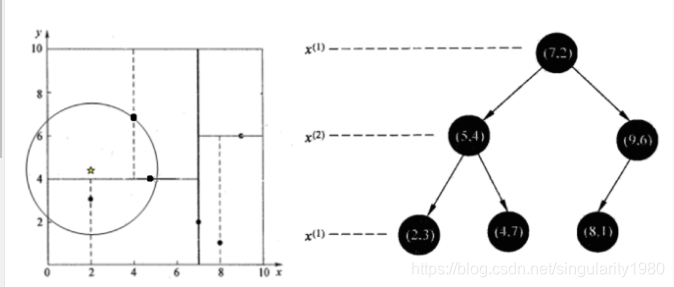
案例:
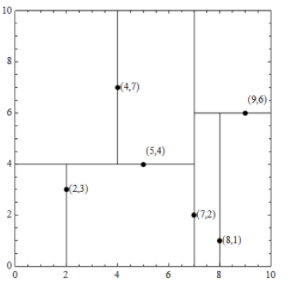
有如下样本:
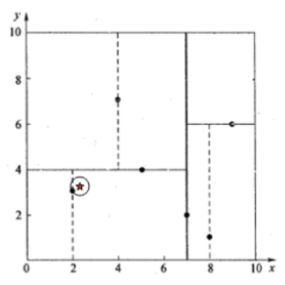
T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
第一步:
按照x轴数据进行排序:2 4 5 7 8 9
按照Y轴数据排序 1 2 3 4 6 7
第二步:
通过对比得出x轴的数据比Y轴的数据更加离散(方差计算)
所以选择从X轴的树中找到一个中间数,可以选择(7.2)也可以选择(5.4),这里选择(7.2)
第三步:
做题:
查找点(2.1,3.1)
查找点(2,4.5)
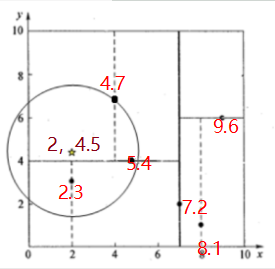
从二叉树找到4.7为最佳结点,以2,4.5为圆心,到4.7的距离为半径,发现5.4和2.3在圈内
或者以4.7为最佳结点,回溯到5.4 发现 5.4里面还有一个2.3所以再测试一下2.3 最后对比,发现还是2.3最近
对比的都是各个结点到2,4.5的半径