如果是一维数据,我们可以用二叉查找树来进行存储,但是如果是多维的数据,用传统的二叉查找树就不能够满足我们的要求了,因此后来才发展出了满足多维数据的Kd-Tree数据结构。
在构造1维BST树时,一个1维数据依据其与树的根结点和中间结点进行大小比較的结果来决定是划分到左子树还是右子树。同理。我们也能够依照这种方式,将一个K维数据与Kd-tree的根结点和中间结点进行比較。仅仅只是不是对K维数据进行总体的比較,而是选择某一个维度Di。然后比較两个K维数在该维度Di上的大小关系。即每次选择一个维度Di来对K维数据进行划分,相当于用一个垂直于该维度Di的超平面将K维数据空间一分为二。平面一边的全部K维数据在Di维度上的值小于平面还有一边的全部K维数据相应维度上的值。也就是说。我们每选择一个维度进行如上的划分,就会将K维数据空间划分为两个部分。假设我们继续分别对这两个子K维空间进行如上的划分。又会得到新的子空间,对新的子空间又继续划分,反复以上过程直到每一个子空间都不能再划分为止。以上就是构造Kd-Tree的过程,上述过程中涉及到两个重要的问题:1)每次对子空间的划分时。如何确定在哪个维度上进行划分;2)在某个维度上进行划分时,如何确保在这一维度上的划分得到的两个子集合的数量尽量相等。即左子树和右子树中的结点个数尽量相等。
例:
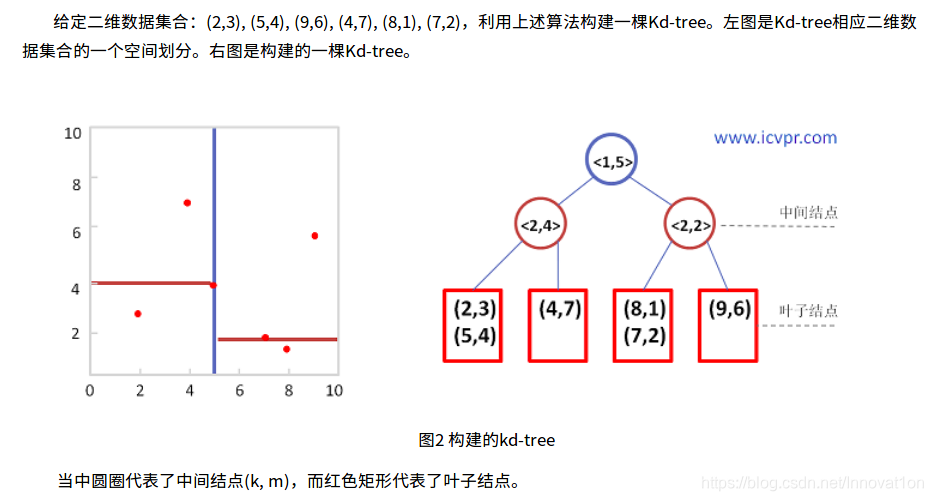
注意这里k指数据的维度,m是当前维度上的中值数据
Kd-Tree与一维二叉查找树之间的差别:
二叉查找树:数据存放在树中的每一个结点(根结点、中间结点、叶子结点)中;
Kd-Tree:数据仅仅存放在叶子结点,而根结点和中间结点存放一些空间划分信息(比如划分维度、划分值);
这里有疑问,到底只是叶子节点有样本还是中间节点也可以有样本分类?????
李航书里给出来的图:

构建好一棵Kd-Tree后,以下给出利用Kd-Tree进行近期邻查找的算法:
(1)将查询数据Q从根结点開始,依照Q与各个结点的比較结果向下訪问Kd-Tree,直至达到叶子结点。
当中Q与结点的比較指的是将Q相应于结点中的k维度上的值与m进行比較,若Q(k) < m,则訪问左子树。否则訪问右子树。达到叶子结点时,计算Q与叶子结点上保存的数据之间的距离。记录下最小距离相应的数据点。记为当前“近期邻点”Pcur和最小距离Dcur。
(2)进行回溯(Backtracking)操作,该操作是为了找到离Q更近的“近期邻点”。
即推断未被訪问过的分支里是否还有离Q更近的点。它们之间的距离小于Dcur。
假设Q与其父结点下的未被訪问过的分支之间的距离小于Dcur,则觉得该分支中存在离P更近的数据,进入该结点,进行(1)步骤一样的查找过程,假设找到更近的数据点,则更新为当前的“近期邻点”Pcur,并更新Dcur。
假设Q与其父结点下的未被訪问过的分支之间的距离大于Dcur,则说明该分支内不存在与Q更近的点。
回溯的推断过程是从下往上,中间节点进行距离比较进行的,直到回溯到根结点时已经不存在与P更近的分支为止。
**在介绍Kd-Tree之前,首先介绍下它的父系结构——BST。二叉查找树,是一种具有如下性质的二叉树:
若它的左子树不为空,则它的左子树节点上的值皆小于它的根节点。
若它的右子树不为空,则它的右子树节点上的值皆大于它的根节点。
它的左右子树也分别是二叉查找树。
构造BST很简单:
在现有的数据中选定一个数据作为根节点的存储数值。(要求尽可能保证左右子树的集合的数量相等,优化查找速度)
将其它数据按照左小右大的规则往深层递归,直到叶节点,然后开辟新的叶节点,并存储当前值。
新的数据按照上一条进行存储。
**
Kd-tree的构造是在BST的基础上升级:
选定数据X1的Y1维数值a1做为根节点比对值,对所有的数值在Y1维进行一层BST排列。相当于根据Y1维数值a1对数据集进行分割。
选定数据X2的Y2维数值a2做为根节点比对值,对所有的数值在Y2维进行一层BST排列。也即将数据集在Y2维上又做了一层BST。
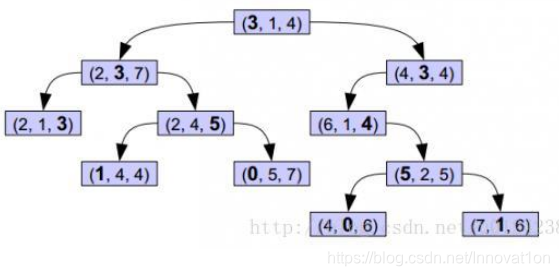
这里可见第一行从第一维开始划分得到第二维
这样依次按第一维,第二维,第三维,第一维循环划分下来,把所有数据都划分一个遍!!!
那么问题是:
如何决定每次根据哪个维度对子空间进行划分呢?
如何选定根节点的比对数值呢?
第一个问题:
直观的来看,我们一般会选择轮流来。先根据第一维,然后是第二维,然后第三……,那么到底轮流来行不行呢,这就要回到最开始我们为什么要研究选择哪一维进行划分的问题。我们研究Kd-Tree是为了优化在一堆数据中高频查找的速度,用树的形式,也是为了尽快的缩小检索范围,所以这个“比对维”就很关键,通常来说,更为分散的维度,我们就更容易的将其分开,是以这里我们通过求方差,用方差最大的维度来进行划分——这也就是最大方差法(max invarince)。
第二个问题:
选择何值未比对值,目的也是为了要加快检索速度。一般来说我们在构造一个二叉树的时候,当然是希望它是一棵尽量平衡的树,即左右子树中的结点个数相差不大。所以这里用当前维度的中值是比较合理的。
Kd-Tree和BST的区别:
BST的每个节点存储的是值,而Kd-Tree的根节点和中间节点存储的是对某个维度的划分信息,只有叶节点里才是存储的值。
在计算机视觉领域应用Kd-Tree较多的是在特征点匹配的时候,例如SIFT特征点匹配的时候,需要两两比对特征描述子的128位特征描述向量,选取汉明距离最小的做为最佳匹配点,这个时候因为要将多个特征描述向量进行大量的查找比对,Kd-Tree就能够发挥它的大作用了。当然Kd-Tree的相关知识还有最近邻查找以及怎样在回溯查找的时间复杂度和查找准确度中取舍等等,留待以后再记录。