版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xiaxianba/article/details/89450855
OCR技术是光学字符识别的缩写(Optical Character Recognition),是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。可应用于银行票据、大量文字资料、档案卷宗、文案的录入和处理领域。(以上信息来源于百度百科OCR技术)
前几天刚好接到公司两个相关需求需求,一个是资产管理,由于信息化管理的需求,需要识别我们的物料标签;另一个是我们的会员系统,通过图片给的识别码到系统中查找是否存在相应红包、会员信息,从而避免黄牛扰乱我们的红包、会员系统,以前的做法是购买一个外部公司开发的接口(据说是1000元10万次)。基于公司的业务需求,同时也为了实践用技术解决业务上的问题的态度,把实际开发中遇到的问题记录下来,供读者们少走弯路。
一、环境准备
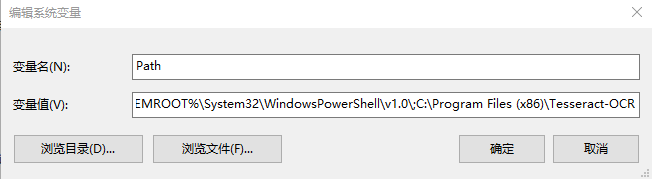
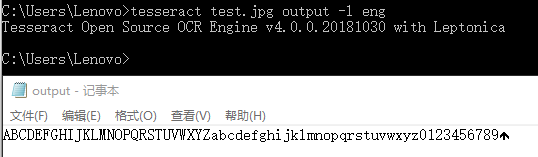
- 首先我们的操作环境是Windows操作系统(Linux系统可以通过libtesseract方式访问),我们采用的OCR识别软件是Tesseract-OCR,下载并安装Tesseract-OCR软件,安装完成之后需要配置环境变量,配置完成之后通过CMD命令行验证是否配置成功,执行
tesseract -v命令查看相应版本,下面是一个CMD控制台下的识别实例。
- 配置中文语言包
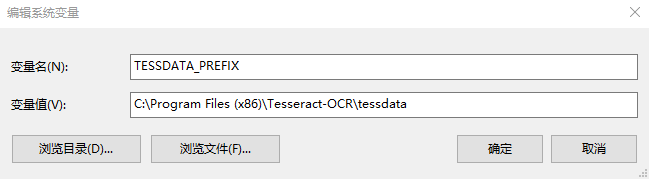
默认情况下Tesseract-OCR是不能识别中文的,需要加载相应的中文语言包,简体中文语言包叫chi_sim.traineddata下载下来之后需要放置到${TESSERACT_HOME}/tessdata目录下,同时把语言包目录路径配置到环境变量当中,新增变量名称为“TESSDATA_PREFIX”。
至此前期的环境准备工作已经完成,读者可以通过CMD命令行的模式使用OCR的基本功能了,接下来是通过Python语言集成进来,毕竟手工操作的效率和扩展性不如程序化实现。
二、Python实现
- 安装依赖包
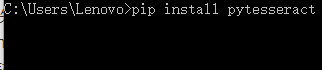
接下来我们主要实现Python与Tesseract-OCR交互实现程序化图片识别功能。首先我们需要安装Python 图片依赖包,本文中Python涉及到的依赖包主要有两个,一个是PIL(Python Imaging Library),另外一个就是与Tesseract-OCR交互的依赖包pytesseract,通过pip install package_name安装相应的包。
- Python项目
编写相应代码获取图片字符,首先是加载依赖包,读取图片,最终把从图片上读取出的字符写入一个文件保存起来,具体代码如下:
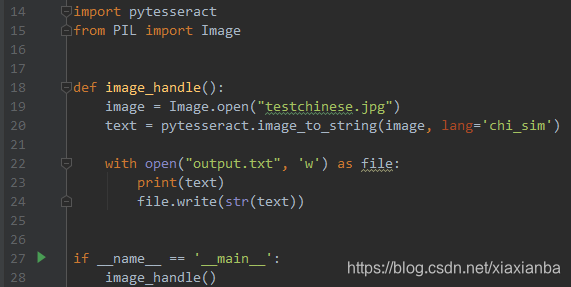
最后的效果如下:


问题及解决:
- 读取中文字符的时候有异常输出,如下
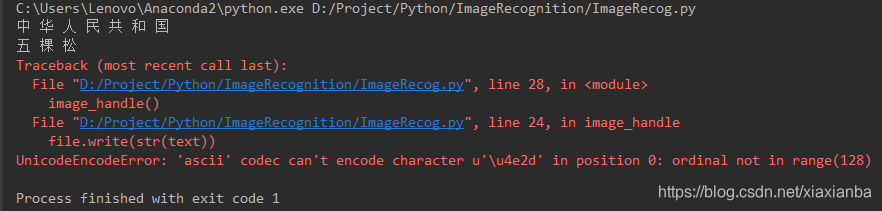
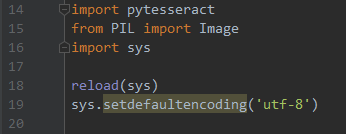
Python程序不能对中文进行编码,执行程序前,需要配置中文的环境,如下:
引用