Pandas——Dataframe读取
一、文件读取
pands可以读取各种文件类型的文件如: CSV,txt,Excel,SQL,JSON等。
pd.read_csv(filename):从CSV文件导入数据
pd.read_table(filename):从限定分隔符的文本文件导入数据
pd.read_excel(filename):从Excel文件导入数据
pd.read_sql(query, connection_object):从SQL表/库导入数据
pd.read_json(json_string):从JSON格式的字符串导入数据
文件读取时里面的函数有许多大家可以去pandas给的官方文档中去查看。
一般情况大家只许记住先放文件名接着根据什么分隔最后需要需要自定义列名:
pd.read_csv(‘文件路径’,sep=‘分隔符’,names=[‘是否需要重新定义列名’])
二、区分sep与delimiter
1.sep : str, default ‘,’
指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用 python的语法分析器。并且忽略数据中的逗号。正则表达式例子:’\r\t’
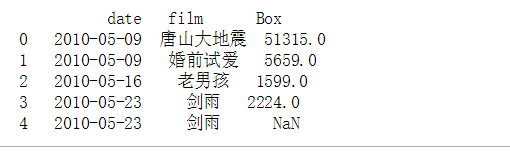
import pandas as pd
df=pd.read_csv('fbr_d_n_b.csv',sep=',',names=['date','film','Box'])
print(df.head(5))
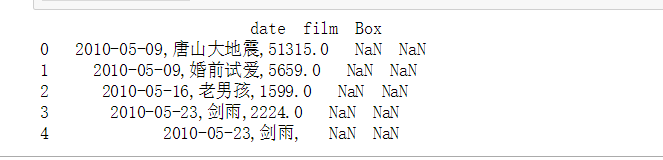
2.delimiter : str, default None
定界符,备选分隔符(如果指定该参数,则sep参数失效)
当两个都出现时以delimiter中的分隔符为准。
import pandas as pd
df=pd.read_csv('fbr_d_n_b.csv',delimiter=';',sep=',',names=['date','film','Box'])
print(df.head(5))
三.如何分段读取大数据文件?
- read_csv()函数的iterator参数等于True时,表示返回一个TextParser以便逐块读取文件;
2.chunkSize表示文件块的大小,用于迭代;
3.TextParser类的get_chunk方法用于读取任意大小的文件块;
4.StopIteration的异常表示在循环对象穷尽所有元素时报错;
5.concat()函数用于将数据做轴向连接:
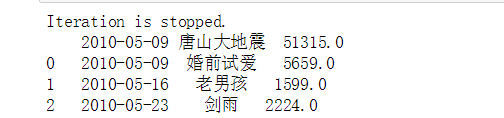
当数据文件过大时,由于计算机内存有限,需要对大文件进行分块读取代码如下:
import pandas as pd
reader=pd.read_csv('fbr_d_n_b.csv',sep=',', iterator=True)
loop = True
chunkSize =1
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped.")
df = pd.concat(chunks, ignore_index=True)
print(df.head(3))