import numpy as np
import pandas as pd
s = pd. Series( [ 7 , 'Beijing' , 3.14 , - 12345 , 'Hanxiao' ] )
s[ 1 ]
'Beijing'
s
0 7
1 Beijing
2 3.14
3 -12345
4 Hanxiao
dtype: object
pandas默认用0到n作为Series的index,也可以自定义index(索引)。
s = pd. Series( [ 7 , 'Beijing' , 3.14 , - 12345 , 'Hanxiao' ] , index= [ 'A' , 'B' , 'C' , 'D' , 'E' ] )
s
A 7
B Beijing
C 3.14
D -12345
E Hanxiao
dtype: object
s[ 'A' ]
7
s[ [ 'A' , 'D' , 'B' ] ]
A 7
D -12345
B Beijing
dtype: object
可以用list构建Series,同时可以指定index。也可以用dict来初始化Series。
cities = { 'Beijing' : 55000 , 'Shanghai' : 60000 , 'Shenzhen' : 50000 , 'Hangzhou' : 30000 , 'Guangzhou' : 40000 , 'Suzhou' : None }
cities
{'Beijing': 55000,
'Shanghai': 60000,
'Shenzhen': 50000,
'Hangzhou': 30000,
'Guangzhou': 40000,
'Suzhou': None}
apt = pd. Series( cities, name= 'income' )
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 50000.0
Hangzhou 30000.0
Guangzhou 40000.0
Suzhou NaN
Name: income, dtype: float64
apt[ 'Guangzhou' ]
40000.0
apt[ 4 ]
40000.0
apt[ 1 : ]
Shanghai 60000.0
Shenzhen 50000.0
Hangzhou 30000.0
Guangzhou 40000.0
Suzhou NaN
Name: income, dtype: float64
apt[ : - 1 ]
Beijing 55000.0
Shanghai 60000.0
Shenzhen 50000.0
Hangzhou 30000.0
Guangzhou 40000.0
Name: income, dtype: float64
apt[ [ 3 , 4 , 1 ] ]
Hangzhou 30000.0
Guangzhou 40000.0
Shanghai 60000.0
Name: income, dtype: float64
apt[ [ 'Shanghai' , 'Shenzhen' ] ]
Shanghai 60000.0
Shenzhen 50000.0
Name: income, dtype: float64
3 * apt
Beijing 165000.0
Shanghai 180000.0
Shenzhen 150000.0
Hangzhou 90000.0
Guangzhou 120000.0
Suzhou NaN
Name: income, dtype: float64
apt/ 2.5
Beijing 22000.0
Shanghai 24000.0
Shenzhen 20000.0
Hangzhou 12000.0
Guangzhou 16000.0
Suzhou NaN
Name: income, dtype: float64
apt[ 1 : ] + apt[ : - 1 ]
Beijing NaN
Guangzhou 80000.0
Hangzhou 60000.0
Shanghai 120000.0
Shenzhen 100000.0
Suzhou NaN
Name: income, dtype: float64
'Hangzhou' in apt
True
'Chongqing' in apt
False
print ( apt. get( 'Chongqing' ) )
None
print ( apt. get( 'Guangzhou' ) )
40000.0
apt>= 40000
Beijing True
Shanghai True
Shenzhen True
Hangzhou False
Guangzhou True
Suzhou False
Name: income, dtype: bool
apt[ apt>= 40000 ]
Beijing 55000.0
Shanghai 60000.0
Shenzhen 50000.0
Guangzhou 40000.0
Name: income, dtype: float64
apt. mean( )
47000.0
apt. median( )
50000.0
apt. max ( )
60000.0
apt. min ( )
30000.0
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 50000.0
Hangzhou 30000.0
Guangzhou 40000.0
Suzhou NaN
Name: income, dtype: float64
apt[ 'Shenzhen' ] = 70000
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 70000.0
Hangzhou 30000.0
Guangzhou 40000.0
Suzhou NaN
Name: income, dtype: float64
apt[ apt<= 40000 ] = 45000
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 70000.0
Hangzhou 45000.0
Guangzhou 45000.0
Suzhou NaN
Name: income, dtype: float64
np. log( apt)
Beijing 10.915088
Shanghai 11.002100
Shenzhen 11.156251
Hangzhou 10.714418
Guangzhou 10.714418
Suzhou NaN
Name: income, dtype: float64
cars = pd. Series( { 'Beijing' : 350000 , 'Shanghai' : 400000 , 'Shenzhen' : 300000 , 'Tianjing' : 200000 , 'Guangzhou' : 250000 , 'Chongqing' : 150000 } )
cars
Beijing 350000
Shanghai 400000
Shenzhen 300000
Tianjing 200000
Guangzhou 250000
Chongqing 150000
dtype: int64
expense = cars + 10 * apt
expense
Beijing 900000.0
Chongqing NaN
Guangzhou 700000.0
Hangzhou NaN
Shanghai 1000000.0
Shenzhen 1000000.0
Suzhou NaN
Tianjing NaN
dtype: float64
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 70000.0
Hangzhou 45000.0
Guangzhou 45000.0
Suzhou NaN
Name: income, dtype: float64
apt. notnull( )
Beijing True
Shanghai True
Shenzhen True
Hangzhou True
Guangzhou True
Suzhou False
Name: income, dtype: bool
apt. isnull( )
Beijing False
Shanghai False
Shenzhen False
Hangzhou False
Guangzhou False
Suzhou True
Name: income, dtype: bool
expense
Beijing 900000.0
Chongqing 900000.0
Guangzhou 700000.0
Hangzhou 900000.0
Shanghai 1000000.0
Shenzhen 1000000.0
Suzhou 900000.0
Tianjing 900000.0
dtype: float64
expense[ expense. isnull( ) ] = expense. mean( )
expense
Beijing 900000.0
Chongqing 900000.0
Guangzhou 700000.0
Hangzhou 900000.0
Shanghai 1000000.0
Shenzhen 1000000.0
Suzhou 900000.0
Tianjing 900000.0
dtype: float64
二位数组
data = { 'City' : [ 'Beijing' , 'Shanghai' , 'Guangzhou' , 'Shenzhen' , 'Hanghzhou' , 'Chongqing' ] ,
'year' : [ 2017 , 2018 , 2017 , 2018 , 2017 , 2017 ] ,
'popu' : [ 2100 , 2300 , 1000 , 700 , 500 , 500 ]
}
pd. DataFrame( data)
City
year
popu
0
Beijing
2017
2100
1
Shanghai
2018
2300
2
Guangzhou
2017
1000
3
Shenzhen
2018
700
4
Hanghzhou
2017
500
5
Chongqing
2017
500
pd. DataFrame( data, columns= [ 'year' , 'City' , 'popu' ] )
year
City
popu
0
2017
Beijing
2100
1
2018
Shanghai
2300
2
2017
Guangzhou
1000
3
2018
Shenzhen
700
4
2017
Hanghzhou
500
5
2017
Chongqing
500
pd. DataFrame( data, columns= [ 'year' , 'City' , 'popu' ] , index= [ 'one' , 'two' , 'three' , 'four' , 'five' , 'six' ] )
year
City
popu
one
2017
Beijing
2100
two
2018
Shanghai
2300
three
2017
Guangzhou
1000
four
2018
Shenzhen
700
five
2017
Hanghzhou
500
six
2017
Chongqing
500
apt
Beijing 55000.0
Shanghai 60000.0
Shenzhen 70000.0
Hangzhou 45000.0
Guangzhou 45000.0
Suzhou NaN
Name: income, dtype: float64
cars
Beijing 350000
Shanghai 400000
Shenzhen 300000
Tianjing 200000
Guangzhou 250000
Chongqing 150000
dtype: int64
df = pd. DataFrame( { 'apt' : apt, 'cars' : cars} )
df
apt
cars
Beijing
55000.0
350000.0
Chongqing
NaN
150000.0
Guangzhou
45000.0
250000.0
Hangzhou
45000.0
NaN
Shanghai
60000.0
400000.0
Shenzhen
70000.0
300000.0
Suzhou
NaN
NaN
Tianjing
NaN
200000.0
df[ 'apt' ]
Beijing 55000.0
Chongqing NaN
Guangzhou 45000.0
Hangzhou 45000.0
Shanghai 60000.0
Shenzhen 70000.0
Suzhou NaN
Tianjing NaN
Name: apt, dtype: float64
type ( df[ 'apt' ] )
pandas.core.series.Series
df[ [ 'apt' ] ]
apt
Beijing
55000.0
Chongqing
NaN
Guangzhou
45000.0
Hangzhou
45000.0
Shanghai
60000.0
Shenzhen
70000.0
Suzhou
NaN
Tianjing
NaN
type ( df[ [ 'apt' ] ] )
pandas.core.frame.DataFrame
df
apt
cars
Beijing
55000.0
350000.0
Chongqing
NaN
150000.0
Guangzhou
45000.0
250000.0
Hangzhou
45000.0
NaN
Shanghai
60000.0
400000.0
Shenzhen
70000.0
300000.0
Suzhou
NaN
NaN
Tianjing
NaN
200000.0
df[ 'bonus' ] = 40000
df
apt
cars
bonus
Beijing
55000.0
350000.0
40000
Chongqing
NaN
150000.0
40000
Guangzhou
45000.0
250000.0
40000
Hangzhou
45000.0
NaN
40000
Shanghai
60000.0
400000.0
40000
Shenzhen
70000.0
300000.0
40000
Suzhou
NaN
NaN
40000
Tianjing
NaN
200000.0
40000
df[ 'expense' ] = df[ 'apt' ] + df[ 'bonus' ]
df
apt
cars
bonus
expense
Beijing
55000.0
350000.0
40000
95000.0
Chongqing
NaN
150000.0
40000
NaN
Guangzhou
45000.0
250000.0
40000
85000.0
Hangzhou
45000.0
NaN
40000
85000.0
Shanghai
60000.0
400000.0
40000
100000.0
Shenzhen
70000.0
300000.0
40000
110000.0
Suzhou
NaN
NaN
40000
NaN
Tianjing
NaN
200000.0
40000
NaN
df. index
Index(['Beijing', 'Chongqing', 'Guangzhou', 'Hangzhou', 'Shanghai', 'Shenzhen',
'Suzhou', 'Tianjing'],
dtype='object')
df. loc[ 'Beijing' ]
apt 55000.0
cars 350000.0
bonus 40000.0
expense 95000.0
Name: Beijing, dtype: float64
type ( df. loc[ 'Beijing' ] )
pandas.core.series.Series
df. loc[ [ 'Beijing' , 'Shanghai' , 'Guangzhou' ] ]
apt
cars
bonus
expense
Beijing
55000.0
350000.0
40000
95000.0
Shanghai
60000.0
400000.0
40000
100000.0
Guangzhou
45000.0
250000.0
40000
85000.0
df
apt
cars
bonus
expense
Beijing
55000.0
350000.0
40000
95000.0
Chongqing
NaN
150000.0
40000
NaN
Guangzhou
45000.0
250000.0
40000
85000.0
Hangzhou
45000.0
NaN
40000
85000.0
Shanghai
60000.0
400000.0
40000
100000.0
Shenzhen
70000.0
300000.0
40000
110000.0
Suzhou
NaN
NaN
40000
NaN
Tianjing
NaN
200000.0
40000
NaN
df. loc[ 'Beijing' : 'Suzhou' , [ 'apt' , 'bonus' ] ]
apt
bonus
Beijing
55000.0
40000
Chongqing
NaN
40000
Guangzhou
45000.0
40000
Hangzhou
45000.0
40000
Shanghai
60000.0
40000
Shenzhen
70000.0
40000
Suzhou
NaN
40000
df. loc[ 'Beijing' : 'Suzhou' , 'apt' : 'bonus' ]
apt
cars
bonus
Beijing
55000.0
350000.0
40000
Chongqing
NaN
150000.0
40000
Guangzhou
45000.0
250000.0
40000
Hangzhou
45000.0
NaN
40000
Shanghai
60000.0
400000.0
40000
Shenzhen
70000.0
300000.0
40000
Suzhou
NaN
NaN
40000
df. loc[ [ 'Beijing' , 'Suzhou' ] , [ 'apt' , 'bonus' ] ]
apt
bonus
Beijing
55000.0
40000
Suzhou
NaN
40000
df. loc[ 'Beijing' , 'bonus' ] = 50000
df
apt
cars
bonus
expense
Beijing
55000.0
350000.0
50000
95000.0
Chongqing
NaN
150000.0
40000
NaN
Guangzhou
45000.0
250000.0
40000
85000.0
Hangzhou
45000.0
NaN
40000
85000.0
Shanghai
60000.0
400000.0
40000
100000.0
Shenzhen
70000.0
300000.0
40000
110000.0
Suzhou
NaN
NaN
40000
NaN
Tianjing
NaN
200000.0
40000
NaN
df. loc[ : , 'expense' ] = 100000
df
apt
cars
bonus
expense
Beijing
55000.0
350000.0
50000
100000
Chongqing
NaN
150000.0
40000
100000
Guangzhou
45000.0
250000.0
40000
100000
Hangzhou
45000.0
NaN
40000
100000
Shanghai
60000.0
400000.0
40000
100000
Shenzhen
70000.0
300000.0
40000
100000
Suzhou
NaN
NaN
40000
100000
Tianjing
NaN
200000.0
40000
100000
df. shape
(8, 4)
df. info( )
<class 'pandas.core.frame.DataFrame'>
Index: 8 entries, Beijing to Tianjing
Data columns (total 4 columns):
apt 5 non-null float64
cars 6 non-null float64
bonus 8 non-null int64
expense 8 non-null int64
dtypes: float64(2), int64(2)
memory usage: 640.0+ bytes
df. T
Beijing
Chongqing
Guangzhou
Hangzhou
Shanghai
Shenzhen
Suzhou
Tianjing
apt
55000.0
NaN
45000.0
45000.0
60000.0
70000.0
NaN
NaN
cars
350000.0
150000.0
250000.0
NaN
400000.0
300000.0
NaN
200000.0
bonus
50000.0
40000.0
40000.0
40000.0
40000.0
40000.0
40000.0
40000.0
expense
100000.0
100000.0
100000.0
100000.0
100000.0
100000.0
100000.0
100000.0
df
apt
cars
bonus
expense
Beijing
55000.0
350000.0
50000
100000
Chongqing
NaN
150000.0
40000
100000
Guangzhou
45000.0
250000.0
40000
100000
Hangzhou
45000.0
NaN
40000
100000
Shanghai
60000.0
400000.0
40000
100000
Shenzhen
70000.0
300000.0
40000
100000
Suzhou
NaN
NaN
40000
100000
Tianjing
NaN
200000.0
40000
100000
df. describe( )
apt
cars
bonus
expense
count
5.000000
6.000000
8.000000
8.0
mean
55000.000000
275000.000000
41250.000000
100000.0
std
10606.601718
93541.434669
3535.533906
0.0
min
45000.000000
150000.000000
40000.000000
100000.0
25%
45000.000000
212500.000000
40000.000000
100000.0
50%
55000.000000
275000.000000
40000.000000
100000.0
75%
60000.000000
337500.000000
40000.000000
100000.0
max
70000.000000
400000.000000
50000.000000
100000.0
df[ 'cars' ]
Beijing 350000.0
Chongqing 150000.0
Guangzhou 250000.0
Hangzhou NaN
Shanghai 400000.0
Shenzhen 300000.0
Suzhou NaN
Tianjing 200000.0
Name: cars, dtype: float64
df[ 'cars' ] < 310000
Beijing False
Chongqing True
Guangzhou True
Hangzhou False
Shanghai False
Shenzhen True
Suzhou False
Tianjing True
Name: cars, dtype: bool
df. loc[ : , 'color' ] = [ '红' , '黄' , '紫' , '蓝' , '红' , '绿' , '棕' , '红' ]
df
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Chongqing
NaN
150000.0
40000
100000
黄
Guangzhou
45000.0
250000.0
40000
100000
紫
Hangzhou
45000.0
NaN
40000
100000
蓝
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Suzhou
NaN
NaN
40000
100000
棕
Tianjing
NaN
200000.0
40000
100000
红
df[ 'color' ] . isin( [ '红' , '绿' ] )
Beijing True
Chongqing False
Guangzhou False
Hangzhou False
Shanghai True
Shenzhen True
Suzhou False
Tianjing True
Name: color, dtype: bool
df[ df[ 'color' ] . isin( [ '红' , '绿' ] ) ]
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Tianjing
NaN
200000.0
40000
100000
红
df. fillna( value= 50000 )
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Chongqing
50000.0
150000.0
40000
100000
黄
Guangzhou
45000.0
250000.0
40000
100000
紫
Hangzhou
45000.0
50000.0
40000
100000
蓝
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Suzhou
50000.0
50000.0
40000
100000
棕
Tianjing
50000.0
200000.0
40000
100000
红
df
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Chongqing
NaN
150000.0
40000
100000
黄
Guangzhou
45000.0
250000.0
40000
100000
紫
Hangzhou
45000.0
NaN
40000
100000
蓝
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Suzhou
NaN
NaN
40000
100000
棕
Tianjing
NaN
200000.0
40000
100000
红
df. fillna( method= 'ffill' )
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Chongqing
55000.0
150000.0
40000
100000
黄
Guangzhou
45000.0
250000.0
40000
100000
紫
Hangzhou
45000.0
250000.0
40000
100000
蓝
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Suzhou
70000.0
300000.0
40000
100000
棕
Tianjing
70000.0
200000.0
40000
100000
红
df. fillna( method= 'bfill' )
apt
cars
bonus
expense
color
Beijing
55000.0
350000.0
50000
100000
红
Chongqing
45000.0
150000.0
40000
100000
黄
Guangzhou
45000.0
250000.0
40000
100000
紫
Hangzhou
45000.0
400000.0
40000
100000
蓝
Shanghai
60000.0
400000.0
40000
100000
红
Shenzhen
70000.0
300000.0
40000
100000
绿
Suzhou
NaN
200000.0
40000
100000
棕
Tianjing
NaN
200000.0
40000
100000
红
stock = pd. read_csv( 'stock_px.csv' )
stock. head( )
DATE
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
0
1990-2-1 0:00
4.98
7.86
2.87
16.79
4.27
0.51
6.04
328.79
6.12
1
1990-2-2 0:00
5.04
8.00
2.87
16.89
4.37
0.51
6.09
330.92
6.24
2
1990-2-5 0:00
5.07
8.18
2.87
17.32
4.34
0.51
6.05
331.85
6.25
3
1990-2-6 0:00
5.01
8.12
2.88
17.56
4.32
0.51
6.15
329.66
6.23
4
1990-2-7 0:00
5.04
7.77
2.91
17.93
4.38
0.51
6.17
333.75
6.33
stock = pd. read_csv( 'stock_px.csv' , index_col= 0 , parse_dates= [ 'DATE' ] )
stock. head( 6 )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
DATE
1990-02-01
4.98
7.86
2.87
16.79
4.27
0.51
6.04
328.79
6.12
1990-02-02
5.04
8.00
2.87
16.89
4.37
0.51
6.09
330.92
6.24
1990-02-05
5.07
8.18
2.87
17.32
4.34
0.51
6.05
331.85
6.25
1990-02-06
5.01
8.12
2.88
17.56
4.32
0.51
6.15
329.66
6.23
1990-02-07
5.04
7.77
2.91
17.93
4.38
0.51
6.17
333.75
6.33
1990-02-08
5.04
7.71
2.92
17.86
4.46
0.51
6.22
332.96
6.35
stock. info( )
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 5472 entries, 1990-02-01 to 2011-10-14
Data columns (total 9 columns):
AA 5472 non-null float64
AAPL 5472 non-null float64
GE 5472 non-null float64
IBM 5472 non-null float64
JNJ 5472 non-null float64
MSFT 5472 non-null float64
PEP 5471 non-null float64
SPX 5472 non-null float64
XOM 5472 non-null float64
dtypes: float64(9)
memory usage: 427.5 KB
stock. describe( )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
count
5472.000000
5472.000000
5472.000000
5472.000000
5472.000000
5472.000000
5471.000000
5472.000000
5472.000000
mean
17.440285
57.119313
17.933194
66.637730
34.225340
17.046345
34.284204
945.035216
35.225919
std
9.647999
88.670423
10.647635
41.689481
19.726666
11.000988
18.383894
369.494672
23.967647
min
4.200000
3.230000
2.400000
8.400000
4.200000
0.510000
5.870000
295.460000
5.940000
25%
8.077500
8.760000
6.280000
20.577500
12.160000
4.240000
15.480000
547.217500
11.910000
50%
14.885000
11.990000
18.150000
74.115000
37.570000
20.910000
33.750000
1058.305000
30.280000
75%
26.340000
68.017500
27.300000
95.657500
52.675000
25.310000
49.530000
1253.395000
55.300000
max
43.620000
422.000000
42.780000
190.530000
67.320000
46.810000
71.250000
1565.150000
87.480000
stock. tail( )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
DATE
2011-10-10
10.09
388.81
16.14
186.62
64.43
26.94
61.87
1194.89
76.28
2011-10-11
10.30
400.29
16.14
185.00
63.96
27.00
60.95
1195.54
76.27
2011-10-12
10.05
402.19
16.40
186.12
64.33
26.96
62.70
1207.25
77.16
2011-10-13
10.10
408.43
16.22
186.82
64.23
27.18
62.36
1203.66
76.37
2011-10-14
10.26
422.00
16.60
190.53
64.72
27.27
62.24
1224.58
78.11
stock. index
DatetimeIndex(['1990-02-01', '1990-02-02', '1990-02-05', '1990-02-06',
'1990-02-07', '1990-02-08', '1990-02-09', '1990-02-12',
'1990-02-13', '1990-02-14',
...
'2011-10-03', '2011-10-04', '2011-10-05', '2011-10-06',
'2011-10-07', '2011-10-10', '2011-10-11', '2011-10-12',
'2011-10-13', '2011-10-14'],
dtype='datetime64[ns]', name='DATE', length=5472, freq=None)
stock. loc[ : , 'dow' ] = stock. index. dayofweek
stock. head( )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
dow
DATE
1990-02-01
4.98
7.86
2.87
16.79
4.27
0.51
6.04
328.79
6.12
3
1990-02-02
5.04
8.00
2.87
16.89
4.37
0.51
6.09
330.92
6.24
4
1990-02-05
5.07
8.18
2.87
17.32
4.34
0.51
6.05
331.85
6.25
0
1990-02-06
5.01
8.12
2.88
17.56
4.32
0.51
6.15
329.66
6.23
1
1990-02-07
5.04
7.77
2.91
17.93
4.38
0.51
6.17
333.75
6.33
2
stock. loc[ : , 'doy' ] = stock. index. dayofyear
stock. head( )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
dow
doy
DATE
1990-02-01
4.98
7.86
2.87
16.79
4.27
0.51
6.04
328.79
6.12
3
32
1990-02-02
5.04
8.00
2.87
16.89
4.37
0.51
6.09
330.92
6.24
4
33
1990-02-05
5.07
8.18
2.87
17.32
4.34
0.51
6.05
331.85
6.25
0
36
1990-02-06
5.01
8.12
2.88
17.56
4.32
0.51
6.15
329.66
6.23
1
37
1990-02-07
5.04
7.77
2.91
17.93
4.38
0.51
6.17
333.75
6.33
2
38
% matplotlib inline
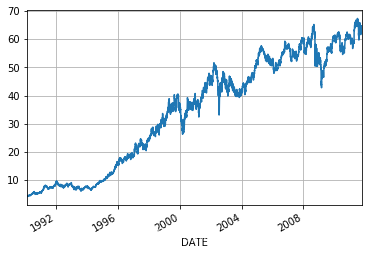
stock[ 'JNJ' ] . plot( )
<matplotlib.axes._subplots.AxesSubplot at 0x19bfb184788>
stock[ 'JNJ' ] . plot( grid= True )
<matplotlib.axes._subplots.AxesSubplot at 0x19bfc4b9188>
sto = stock[ ( stock. index >= '2009-01-01' ) & ( stock. index <= '2009-1-31' ) ]
sto[ 'JNJ' ] . plot( kind= 'bar' )
<matplotlib.axes._subplots.AxesSubplot at 0x19bfc7eaa48>
stock[ ( stock. index >= '2009-01-01' ) & ( stock. index < '2009-1-31' ) ] . describe( )
AA
AAPL
GE
IBM
JNJ
MSFT
PEP
SPX
XOM
dow
doy
count
20.000000
20.000000
20.000000
20.00000
20.00000
20.000000
20.000000
20.000000
20.000000
20.00000
20.000000
mean
9.187000
88.775000
12.947500
83.65950
52.89300
17.768000
47.889500
865.575500
73.170500
2.20000
16.650000
std
1.364208
4.377831
1.532359
3.34427
1.16083
1.135261
1.694649
38.874233
1.590811
1.43637
8.851256
min
7.450000
78.200000
10.860000
77.87000
50.94000
16.060000
46.150000
805.220000
70.230000
0.00000
2.000000
25%
8.057500
87.115000
11.747500
80.96000
52.15000
16.582500
46.490000
839.322500
71.930000
1.00000
8.750000
50%
8.805000
89.885000
12.525000
83.19000
52.89000
18.140000
47.345000
847.915000
73.100000
2.00000
15.500000
75%
10.360000
91.432500
14.475000
86.87250
53.71750
18.545000
48.457500
894.425000
73.997500
3.25000
23.750000
max
11.600000
94.580000
15.420000
90.06000
55.20000
19.500000
51.420000
934.700000
76.350000
4.00000
30.000000
sto. to_csv( 'sto.csv' )
sto. to_csv( 'n_sto.csv' , index= False )