文章目录
概述
pandas作为python的第三方库,它所包含的数据结构和数据处理工具的设计使其在python中进行数据清洗和分析非常快捷,pandas经常是和其他数值计算工具,Numpy和Scipy,以及数据可视化工具比如matplotlib一起使用的。pandas支持大部分Numpy语言风格的数组计算。
pandas的 常用的工具数据结构:Series和DataFrame,这两种数据结构为大多数提供了一个有效,易用的基础。
下面我们来介绍一下这两种数据结构:
文章目录
Series
Series是一种一维的数组型对象,包含了一个值序列,包含两部分,一个是数据标签,另一个是值。最简单一个的序列就是由一个数组形成。
Series的生成
import pandas as pd
apple =pd.Series([3,2,4,np.nan,3])
apple
输出的结果:
0 3.0
1 2.0
2 4.0
3 NaN
4 3.0
dtype: float64
这样我们就生成一个Series的数据结构,我们可以分别看一下数据标签,以及数据等的类型
print(type(apple))
print(type(apple.values))
print(type(apple.index))
运行结果是
<class 'pandas.core.series.Series'>
<class 'numpy.ndarray'>
<class 'pandas.core.indexes.range.RangeIndex'>
我们也可以对数据标签进行命名,采用下面的方式,但我们要记住用index命名,而它在后面的数据框对应的是行。
apples =pd.Series([3,2,4,np.nan,3],index=['a','b','c','d','e'])
apples
运行结果是:
a 3.0
b 2.0
c 4.0
d NaN
e 3.0
dtype: float64
有的时候我们可以对不用的值用相同的数据标签,比如:

apples =pd.Series([3,2,4,np.nan,3],index=['a','b','b','d','e'])#重名现象
apples['b']
我们索引b的值,会有两个结果:
b 2.0
b 4.0
dtype: float64
在生成Series,我们还可以通过字典方式生成:
data={
'a':3,'c':4,'d':3,'e':2}
a =pd.Series(data)
a
运行结果是:
a 3
c 4
d 3
e 2
dtype: int64
有的时候我们在生成一个Series数据结构后,我们需要对其进行,看看是否有没有缺失值:
pd.isnull(apple)
得到结果是:
Bob False
Steve False
Jeff False
Mary False
Tony False
dtype: bool
我们还可以用notnull来检查缺失数据:
pd.notnull(apple)
我们得到的运行结果是:
Bob True
Steve True
Jeff True
Mary True
Tony True
dtype: bool
Series的索引和切片
比如生成了一个Series数据结构,但我们只想要它的值或者索引。用上面的Series作为实例:
print(apple.values)
print(apple.index)
结果是:
[ 3. 2. 4. nan 3.]
RangeIndex(start=0, stop=5, step=1)
我们还可以对值进行索引,有两种索引方式一个是通过前面的数据标签进行索引,还有一种就是类似前面列表等索引方式。
apples['a':'d']
运行结果是:
a 3.0
b 2.0
b 4.0
d NaN
dtype: float64
我们采用列表等类似的索引:
apples[0:3]
#位置切片不包括结束位置的数据
运行结果是:
a 3.0
b 2.0
b 4.0
dtype: float64
我们有的时候还可以通过布尔值来索引:
apples[apple>2]
运行结果是:
a 3.0
e 3.0
dtype: float64
我们还可以判断这个Series数据结构中是否有这个数据标签
data={
'a':3,'c':4,'d':3,'e':2}
a =pd.Series(data)
'e' in a
运行结果:
True
我们还可以通过index对其生成的Series进行命名
apple =pd.Series([3,2,4,6,3])
apple.index =['Bob','Steve','Jeff','Mary','Tony']
apple
最后的结果是:
Bob 3
Steve 2
Jeff 4
Mary 6
Tony 3
dtype: int64
DataFrame
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的数值类型(数值、字符串、布尔值等)。DataFrame 既有行索引也有列索引,它可以被视为一个共享相同索引的Series的字典。在DataFrame中,数据被存储在一个以上的二维块。
数据框生成和使用
我们可以用随机函数来生成数据,然后用index对行进行命名,用columns对列进行命名。
#DateFrame数据结构
#由多个Series结构构成二维数据
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))#每一行取名用index,每一列取名用columns
df
运行结果是:

然后我们可以利用head()函数查看前几条数据,默认是五条,这个在数据量比较大的时候是非常实用的。
df.head(2)#显示前两条
运行结果是:
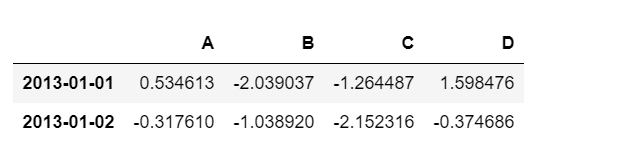
生成一个数据框,我们可以采用列表形式生成:
L =[[1,2,3,],[2,3,4],[3,4,5]]
df_1=pd.DataFrame(L,index=['a','b','c'],columns=['A','B','C'])
df_1
运行结果是:
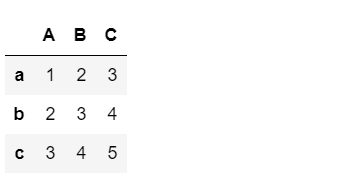
我们还可以通过字典的形式来生成:
data ={
'a':[3,2,1,0],
'b':[2,3,4,5],
'c':[1,2,1,0]
}
df_2 =pd.DataFrame(data)
df_2
运行结果是:

数据框的索引
我们对数据框索引可以采用列表索引类似的方法,还可以通过字典键索引等方法
以上面的数据框为例,我们可以来看看:
df[0:3]
运行结果是:

我们可以对列名进行索引:
df['A']
运行结果是:
2013-01-01 0.534613
2013-01-02 -0.317610
2013-01-03 2.452307
2013-01-04 -0.806402
2013-01-05 -0.511530
2013-01-06 -0.378401
Freq: D, Name: A, dtype: float64
下面我用另外一个实例来让大家更容易理解和利用索引:
data ={
'apple':[2,3,4,5],
'orange':[1,2,4,6],
'bannas':[2,3,4,5]
}
df =pd.DataFrame(data,index =['June','Robert','Lily','David'])
df
运行结果是:

我们分别对行列进行命名,方便后面的索引和切片等操作,我们可以将上面的那些操作对象改为这个数据框,然后看看结果
df['apple']
运行结果是:
June 2
Robert 3
Lily 4
David 5
Name: apple, dtype: int64
其他的大家照着之前的操作试试,我们可以利用query()来进行查询信息
df.query(expr,inplace = False,** kwargs )# 使用布尔表达式查询帧的列
参数:
# expr:str要评估的查询字符串。你可以在环境中引用变量,在它们前面添加一个'@'字符 。@a + b
# inplace=False:是否修改数据或返回副本
# kwargs:dict关键字参数
我们用上面的数据框来试试:
df.query("apple>2")#查询的是行
运行结果是:
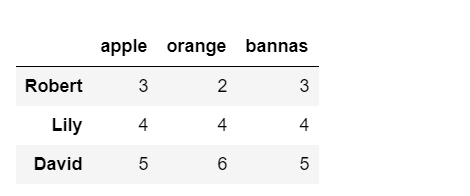
我们还可以利用and和or结合来用:
df.query("apple>2 and orange>2")
运行结果是:

还可以看一个:
df.query("apple>2 or orange>2")
结果是:
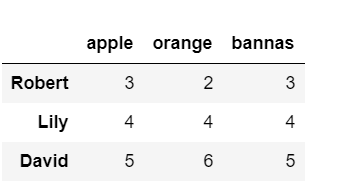
在上面我们讲了一个head()函数,还有一个类似的tail()函数,不过这个是显示后面几条:
df.tail(2)
运行结果是:

loc、iloc索引
1. loc
loc:通过选取行(列)标签索引数据
iloc:通过选取行(列)位置编号索引数据
ix:既可以通过行(列)标签索引数据,也可以通过行(列)位置编号索引数据
我们还是以上面的数据框为例:
#loc全方位取数据,按照名字来取,但是是行在前,后面是列
df.loc['David','apple']
运行结果是:
5
loc可以单独通过选取行标签索引数据,但不能单独通过列来索引数据:
df.loc['David']
运行结果是:
apple 5
orange 6
bannas 5
Name: David, dtype: int64
我们还可以结合布尔值来索引:
b =[True,False,False,True]
df.loc[b,'apple']
运行结果是:
June 2
David 5
Name: apple, dtype: int64
但不能单独通过列来索引就会报错。
2.iloc
iloc只能通过选取行位置编号索引数据,还是以上面为例:
df.iloc[3,0]
运行结果是:
5
选取行位置的时候来索引,我们可以指定多行:
df.iloc[[3,1],0]#前面一个列表就是行,后面一个是列
运行结果是:
David 5
Robert 3
Name: apple, dtype: int64
我们也可以直接选择行:
df.iloc[3]
运行结果是:
apple 5
orange 6
bannas 5
Name: David, dtype: int64
我们还可以通过列表中的冒号来索引:
df.iloc[:,0:2]
运行结果是:

也可以采用布尔值来索引:
b =[True,False,False,True]
df.iloc[b,0:2]
运行结果是:
June 2
David 5
Name: apple, dtype: int64
3.ix
ix既可以通过行标签索引数据,也可以通过行位置编号索引数据
举两个例子可以看看:
df.ix[0]
运行结果是:
apple 2
orange 1
bannas 2
Name: June, dtype: int64
下面我看另外一个例子:
df.ix['David']
运行结果是:
apple 5
orange 6
bannas 5
Name: David, dtype: int64
at与iat
通过标签或行号获取某个数值的具体位置。
at
at通过标签来索引:
df.at['Lily','apple']
运行结果是:
4
iat
iat通过行列位置来索引:
df.iat[3,2]
运行结果是:
5
数据框的增删
数据框的行增加
增加用append,但我们在对数据框进行增加,最好保证两个数据框的格式相同,不然增加得到的可能不是我们想要的结果:
data ={
'apple':[2,3,4,5],
'orange':[1,2,4,6],
'bannas':[2,3,4,5]
}
df =pd.DataFrame(data,index =['June','Robert','Lily','David'])
data1 =[[2,3,3],[4,6,4]]
print(df)
df1 =pd.DataFrame(data1,columns =['apple','orange','bannas'],index =['Bob','Any'])
df4 =df1.append(df)
print(df4)
运行结果是:
apple orange bannas
June 2 1 2
Robert 3 2 3
Lily 4 4 4
David 5 6 5
apple orange bannas
Bob 2 3 3
Any 4 6 4
June 2 1 2
Robert 3 2 3
Lily 4 4 4
David 5 6 5
我们看看,如果增加的如果不是一样的数据框类型或者其他形式:
df2 =pd.DataFrame([2,3,4],[2,4,6])
print(df2)
print(df.append(df2))
运行结果是:
0
2 2
4 3
6 4
apple orange bannas 0
June 2.0 1.0 2.0 NaN
Robert 3.0 2.0 3.0 NaN
Lily 4.0 4.0 4.0 NaN
David 5.0 6.0 5.0 NaN
2 NaN NaN NaN 2.0
4 NaN NaN NaN 3.0
6 NaN NaN NaN 4.0
数据框的行删除
我们可以直接用drop()来进行删除:
df4=df4.drop('Any')
df4
运行结果是:

数据框的列增加
我们采用类似字典增加键值对的方式来增加:
#如何添加列
df4['new_colu']=[3,4,5,6,3,3]
df4
运行结果是:

但在增加的时候我们要保证列的长度一致,不然的话会报错。
数据框列的删除
数据框中的列的删除我们有两种方法,一种是用del ,另一种利用pop函数:
# #如何删除列
# del df4['new_colu']
# df4
#删除列
df4.pop('new_colu')
df4
运行结果是:

行列标签的重命名
有的时候我们采用英文的行列标签名,但希望看到是中文的,我们可以这样做:
df5=df4.rename(columns={
'apple':'苹果'})
df5
运行结果是:

行标签也是类似:
df5=df4.rename(index={
'David':'戴维'})
df5
运行结果是:

提到重命名,我们可以想到Series数据结果的命名:
label =pd.Index(['a','b','c','d'])
p =pd.Series(np.arange(4),index =label)
p
运行结果是:
a 0
b 1
c 2
d 3
dtype: int32
我们可以看看这个:
s1 =p.reindex(['c','d','c'])
s1
运行结果是:
c 2
d 3
c 2
dtype: int32
最后我们看看多级索引
多重索引
我们在用pandas类似groupby来使用多重index时,有时想要对多个level中的某个index对应的行进行操作,就需要在dataframe中找到该index对应的行,在单层index中我们可以方便的使用df.loc[index]来选择,在多重Index中我们可以利用的类似的思路,然而其中也有一些小坑,记录如下。(其实通俗来说就是一个降维的过程)
我们介绍三种转为为多重索引的方式
1.数组形式
##创建多重索引
#使用数组构造
df1 = pd.DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns=[['python','python','math','math','En','En'],['期中','期末','期中','期末','期中','期末']])
df1
运行结果是:

2.元组形式
#使用tuple构造
df3 =pd.DataFrame(np.random.randint(0,150,size=(4,6)),
index = list('东南西北'),
columns =pd.MultiIndex.from_tuples([('python','期中'),('python','期末'),
('math','期中'),('math','期末'),
('En','期中'),('En','期末')]))
df3
运行结果是:

3.使用product构造(推荐)
#使用product构造(推荐)
df4 = pd.DataFrame(np.random.randint(0,150,size=(8,12)),
columns = pd.MultiIndex.from_product([['模拟考','正式考'],
['数学','语文','英语','物理','化学','生物']]),
index = pd.MultiIndex.from_product([['期中','期末'],
['雷军','李斌'],
['测试一','测试二']]))
df4
运行结果是:

Series和DataFrame数据结果的转化
我们可以将Series转为DataFrame,我们看看例子:
s =pd.Series(np.random.randint(0,150,size=6),index=[['a','a','b','b','c','c'],['期中','期末','期中','期末','期中','期末']])
print(s)
#多级索引转为普通索引
s.unstack()
运行结果是:

我们还可以转回去:
s.unstack().stack()
运行结果是:
a 期中 101
期末 41
b 期中 112
期末 4
c 期中 111
期末 54
dtype: int32
关于pandas基础部分的学习,我大致介绍这些,后面我会深入介绍一些以及一些文件读写等操作。