1. 项目描述
保险公司对个人投保时或根据历史数据生成的模型来计算个人保费,那么本次我们就以这个模型的求解过程为例来实践下多元线性回归。
2 数据与简单分析
数据信息如下图所示:
数据集下载

我们已经获取到保险公司部分数据,文件名为insurance.csv,文件内容如下。
我们可以看出数据中共有六个维度:age(年龄),sex(性别),bmi(肥胖指数),children(孩子数量),smoker(是否吸烟),region(居住地)。charges则是当前数据人上年度在保险的额度。
所以我们可以构建一个六维高维空间来求解这个模型。
- 相对于年龄来说, 年龄越大, 购买保险的金额应该越大;
- 相对于性别来说,整体女性的寿命大于男性寿命大约10年, 因此男性的保险额度应该更大。
- 相对于肥胖指数来说, 肥胖指数越小, 身体状况越不好, 购买保险的金额应该越大;
- 相对于孩子的数量来说, 孩子的数量越多, 压力越大, 越劳累, 购买保险的金额应该越大;
- 相对于是否吸烟来说, 吸烟的人寿命远少于不吸烟的寿命, 因此 购买保险的金额应该越大;
- 相对于地区来说, 地区环境越差, 有雾霾, 则越容易生病, 那么购买保险的金额应该越大;
最后说明一下,本章中的数据来源主要是来自某保险公司内部的真实历史数据。
3 项目实践
完成本项目后,您将知道:
- 如何从训练数据中估计统计量。
- 如何从数据估计线性回归系数。
- 如何使用线性回归预测新数据。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 1). 读取csv文件数据;
filename = 'data/insurance.csv'
data = pd.read_csv(filename)
# 2). 清洗数据
reg = LinearRegression()
x = data[['age', 'sex', 'bmi', 'children', 'smoker', 'region']]
y = data['charges']
# 转换数据类型为整形
x = x.apply(pd.to_numeric, errors='corece')
y = y.apply(pd.to_numeric, errors='coerce')
# 填充空值
x.fillna(0, inplace=True)
y.fillna(0, inplace=True)
print(x)
print(y)
# 3). 开始建模
# degree: 多项式的阶数,一般默认是2;
# interaction_only:如果值为true(默认是false),则会产生相互影响的特征集。
# include_bias:是否包含偏差列
poly_features = PolynomialFeatures(degree=2, include_bias=False)
# 降维
X_poly = poly_features.fit_transform(x)
# 4). 用线性回归进行拟合
reg.fit(X_poly, y)
print(reg.coef_)
print(reg.intercept_)
# 5). 预测
y_predict = reg.predict(X_poly)
# 5). 真实的y值绘制:图形绘制显示
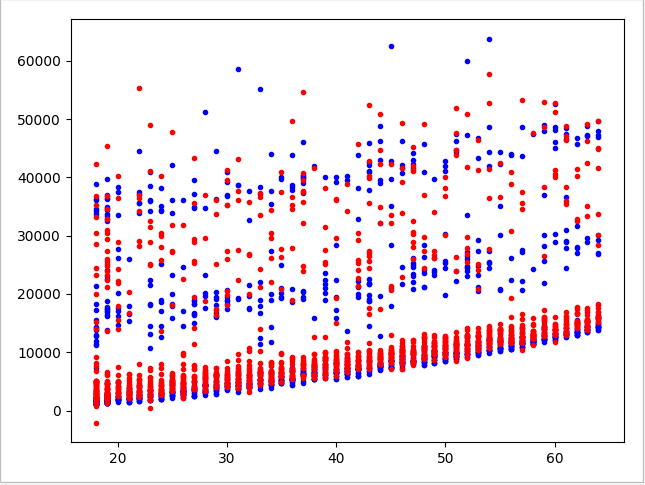
plt.plot(x['age'], y, 'b.')
# 预测的y值绘制
plt.plot(X_poly[:, 0], y_predict, 'r.')
plt.show()
预测值与真实值的图像显示: