1 项目介绍
- 新浪微博:新浪微博是一个由新浪网推出,提供微型博客服务类的社交网站。用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片。新浪可以把微博理解为“微型博客”或者“一句话博客”。用户可以将看到的、听到的、想到的事情写成一句话,或发一张图片,通过电脑或者手机随时随地分享给朋友,一起分享、讨论;还可以关注朋友,即时看到朋友们发布的信息。
本项目进行了新浪微博-个人主页的所有微博信息采集。以“新浪微博-个人主页的所有微博信息采集”为例。在实操过程中,可根据自身需求,更换新浪微博的其他内容进行数据采集。
2 页面分析
2.1 需求分析
- 爬取的网址: https://weibo.com/u/5305630013
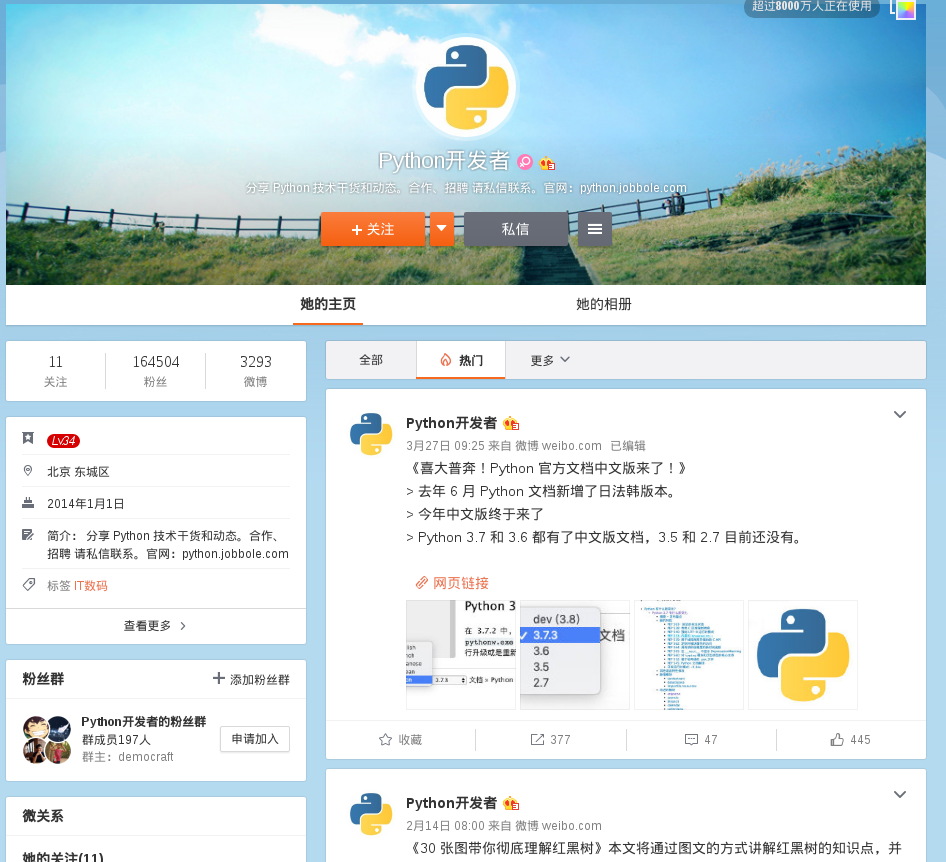
- 获取的博主信息:
- 微博博主名称,博主关注数量,博主粉丝数量,博主地址,博主个人简介,博主个人标签。
- 获取该博主的博客信息:
- 微博名称,微博发布时间,微博发布内容
2.2 找出微博用户的微博内容api
2.2.1 页面元素审查
一般做爬虫爬取网站时,首选的都是m站,其次是wap站,最后考虑PC站,因为PC站的各种验证最多。当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选。一般m站都以m开头后接域名, 我们这次通过m.weibo.cn去分析微博的HTTP请求。
-
首先在PC打开微博主页:Python开发者微博主页
-
接着打开调试页面(F12,或右击检查),先选中右侧手机模式,然后刷新页面,这个时候就出来了m站微博主页:
https://m.weibo.com/p/id, 也有些是m站微博主页为:https://m.weibo.com/u/id; -
注意:
1)当你打开一个页面,再点开network标签时是不会有信息的,我们需要在打开的情况下,刷新一下页面;
2)为了防止页面突然的跳转而丢失信息,一定要勾上preserved单选框。
2.2.2 XHR过滤获取API
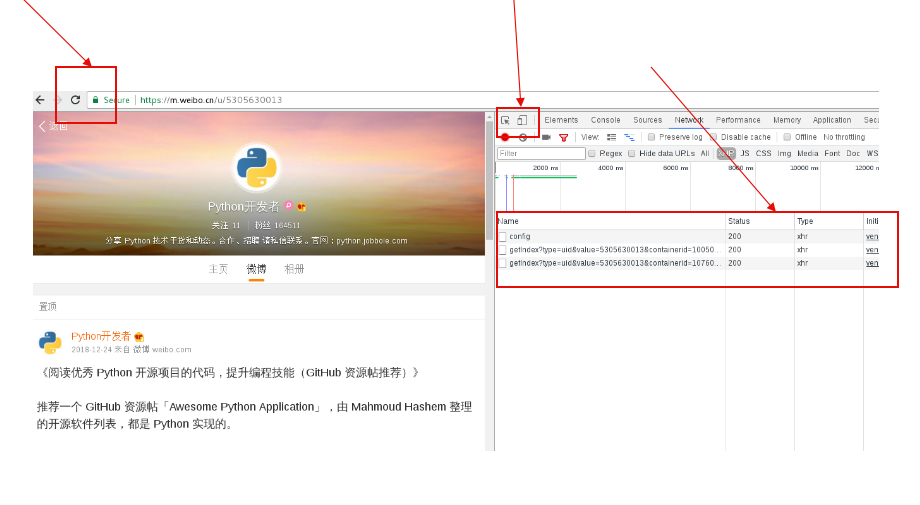
- 选择XHR进行过滤,发现有两个已经发送的api请求。(api请求一般都在XHR中,其他网页请求在Doc)
-
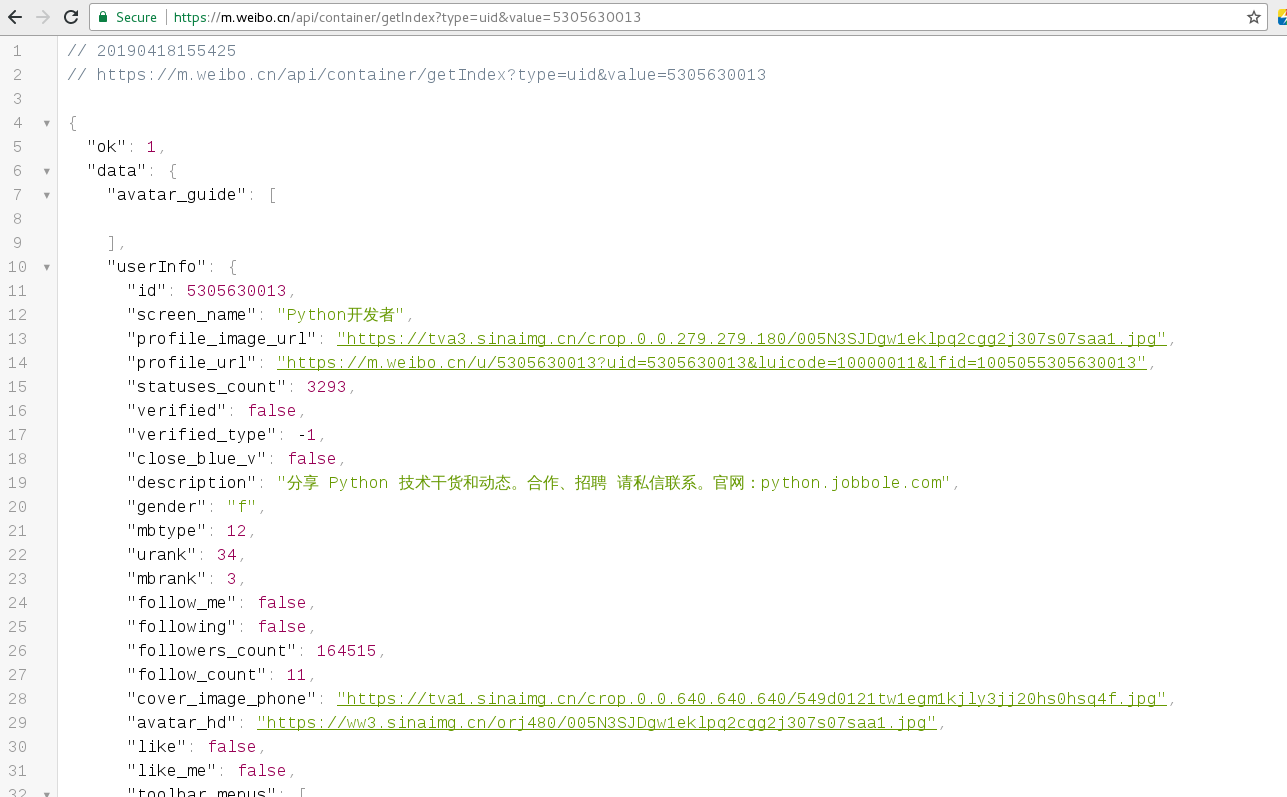
我们查看这两个api返回的数据发现,第一个api返回的是用户数据,第二个api返回的是微博内容数据。
-
根据测试发现真实的url可以删减一部分
参数value的值,我们通过采集多个情况进行分析得出,提门是用户的id号;
参数containerid的值,我们通过采集多个情况进行分析得出,它们获取用户内容的containerid为100505+oid,获取微博内容的containerid为107603+oid。
2.2.3 API返回的JSON数据分析
-
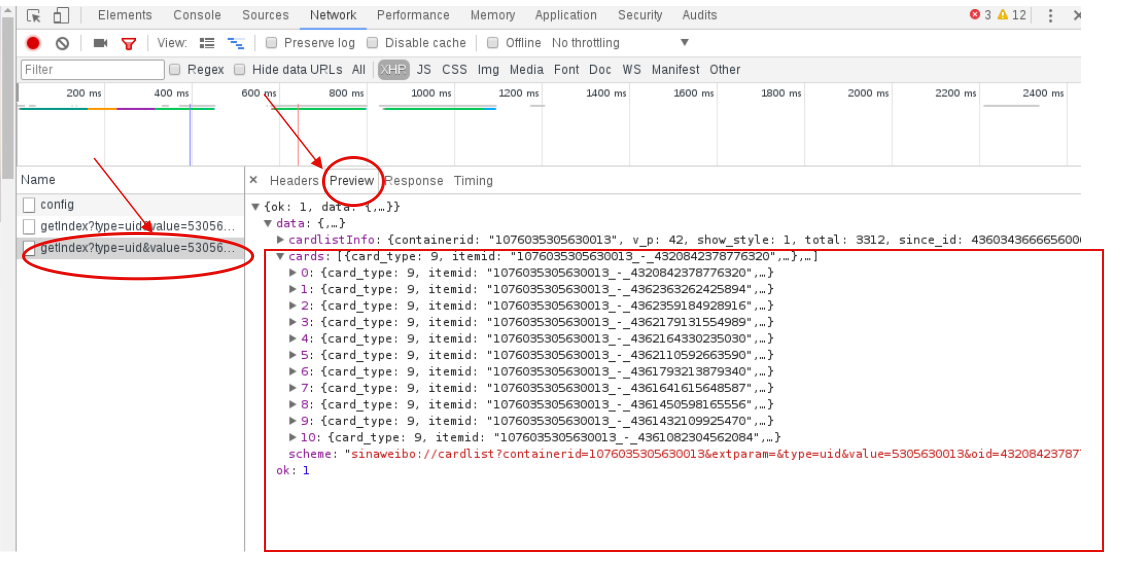
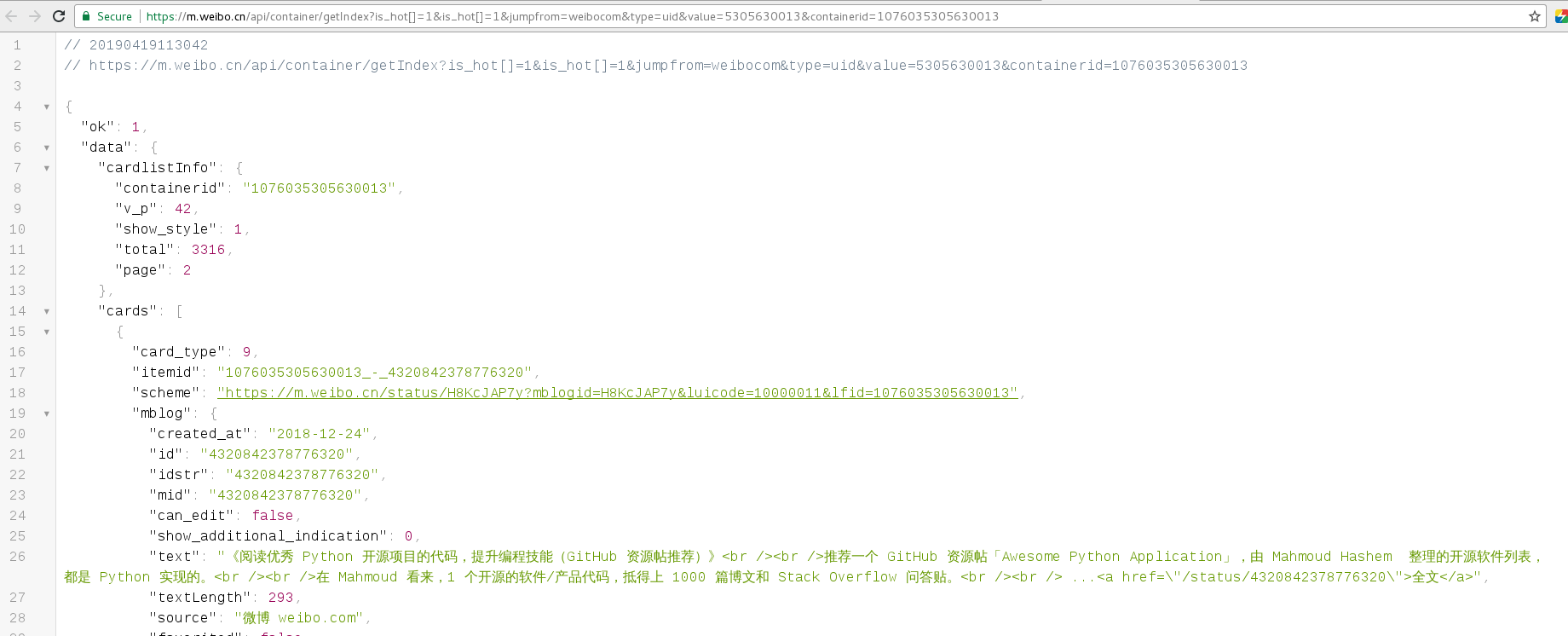
我们在右边选择Preview预览一下json,点击cards中任选一个card,其中的mblog标签下就有我们要的微博内容数据。我们继续观察发现这个json中只有10条数据;
-
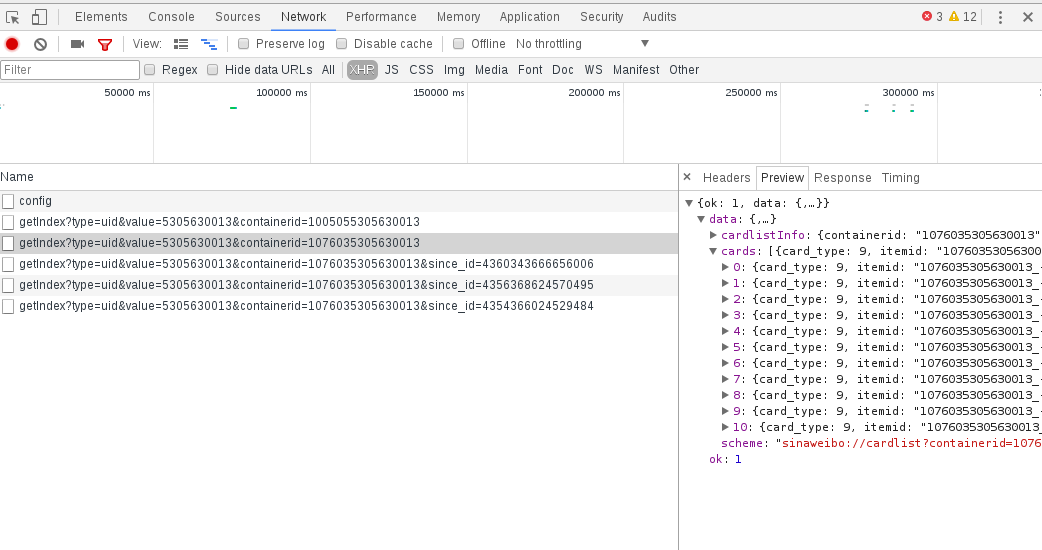
那么我们往下滑动到下一页,继续查看请求的api。我们发现在获取下一页数据时的api加了一个值为2的参数page。继续往下翻页,page变成3、4、5…,由此我们推断这个api获取哪一页的数据由page决定。
2.3 分析返回的json格式的微博内容
-
通过api我们获取到返回的微博内容数据,我们以其中一个card来分析获取到的数据,微博内容数据在mblog中。
-
当然可以在Chrome谷歌浏览器中安装一个
json-viewer插件, 友好的显示json数据, 如下图所示:
3 获取微博内容的代码实现
我们分析完接口之后就可以开始编写爬虫代码。
3.1 获取微博用户信息
def get_user(id):
# 访问博主详情信息的api地址, 返回json格式;
weibo_user_url = "https://m.weibo.cn/api/container/getIndex?type=uid&value={0}&containerid=100505{0}".format(id)
# 获取网页内容;
weibo_user_info = requests.get(weibo_user_url).json()
# 获取用户的信息;
userinfo = weibo_user_info.get("data").get("userInfo")
# 通过命名元组的方式封装微博用户信息, 便于后面调用;
from collections import namedtuple
User = namedtuple('User', 'name follow_count followers_count profile_url description')
user = User(name=userinfo['screen_name'], follow_count=userinfo['follow_count'],
followers_count=userinfo['followers_count'],
profile_url=userinfo['profile_url'], description=userinfo['description'])
# 返回封装的用户信息;
return user
if __name__ == '__main__':
# 定义要爬取的微博大V的微博ID
id = "5305630013"
user = get_user(id)
print("""
微博用户信息
微博名: {0}
关注数:{1}
粉丝数:{2}
微博描述:{3}
""".format(user.name, user.follow_count, user.followers_count, user.description))
- 执行效果

3.2 获取微博内容
- 此处有个问题还没有解决?
- Ajax下拉刷新数据, 获取第2页的信息, 默认的网址是通过since_id来处理的, 但是这个参数对应的值没有找到规律;
- 后来发现, 最早的page参数也可以生效, 因此就先用老方法解决了;
def get_content(id, page=1):
"""爬取某一页的博客信息"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
}
params = {
"type": "uid",
"value": id,
"containerid": "107603" + str(id),
"page": page
}
# 访问博主详情信息的api地址, 返回json格式;
url = "https://m.weibo.cn/api/container/getIndex"
# 获取网页内容;
weibo_content_info = requests.get(url, params=params, headers=headers).json()
# 微博主页内容,每页的全部微博内容
content_infos = weibo_content_info.get('data').get('cards')
# 命名元组
from collections import namedtuple
Content = namedtuple('Content', "create_time text")
contents = []
for content in content_infos:
content = content.get('mblog')
created_time = content.get('created_at')
text = content.get('text')
contents.append(Content(create_time=created_time, text=text))
return contents
if __name__ == '__main__':
id = "5305630013"
contents = []
for page in range(100):
page_content = get_content(id, page)
print("****************爬取第%s页, 共%s条数据******************************" % (page + 1, len(page_content)))
for content in page_content:
print('- ', content.text)
contents.extend(page_content)
- 效果显示:

5 代码封装与重构
import requests
import os
class WeiboSpider(object):
def __init__(self, id, ):
"""提供微博用户的id号"""
self.id = id
# 访问博主详情信息的api地址, 返回json格式;
self.url = "https://m.weibo.cn/api/container/getIndex"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
}
self.savedir = '/tmp/weiboFile/%s' %(id)
if not os.path.exists(self.savedir):
os.makedirs(self.savedir)
def get_user_info(self):
"""获取的博主信息:微博博主名称,博主关注数量,博主粉丝数量,博主地址,博主个人简介,博主个人标签。"""
# 访问博主详情信息的api地址, 返回json格式;
params = {
"type": "uid",
"value": id,
"containerid": "100505" + str(id)
}
try:
# 获取网页内容;
weibo_user_info = requests.get(self.url, params=params, headers=self.headers).json()
except:
print("网页爬取错误")
else:
# 获取用户的信息;
userinfo = weibo_user_info.get("data").get("userInfo")
# 通过命名元组的方式封装微博用户信息, 便于后面调用;
from collections import namedtuple
User = namedtuple('User', 'name follow_count followers_count profile_url description')
user = User(name=userinfo['screen_name'], follow_count=userinfo['follow_count'],
followers_count=userinfo['followers_count'],
profile_url=userinfo['profile_url'], description=userinfo['description'])
# 返回封装的用户信息;
return user
def get_content(self, page=1):
"""
爬取某一页的博客信息,
将每页的图片保存到一个目录中
"""
params = {
"type": "uid",
"value": id,
"containerid": "107603" + str(id),
"page": page
}
try:
# 获取网页内容;
weibo_content_info = requests.get(self.url, params=params, headers=self.headers).json()
except:
print("网页爬取错误")
else:
# 微博主页内容,每页的全部微博内容
content_infos = weibo_content_info.get('data').get('cards')
# 命名元组
from collections import namedtuple
Content = namedtuple('Content', "create_time text")
contents = []
for content in content_infos:
content = content.get('mblog')
created_time = content.get('created_at')
text = content.get('text')
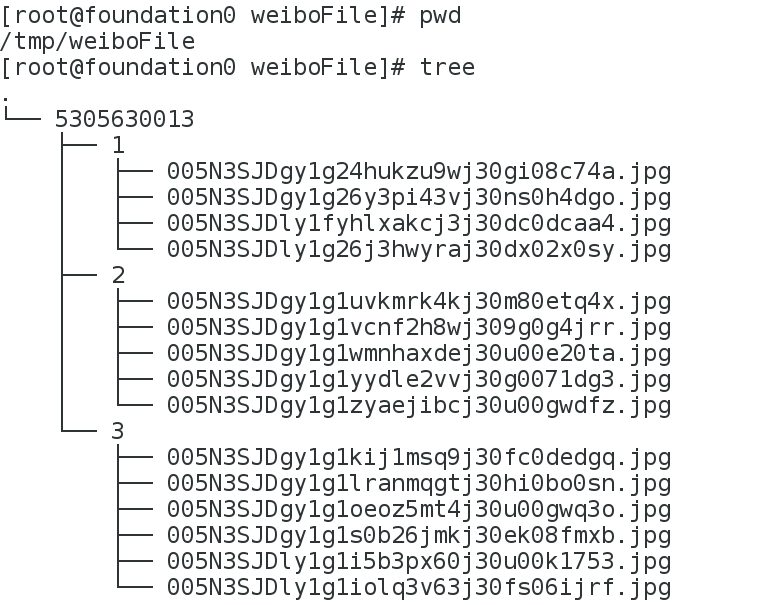
img = content.get('original_pic', None)
if img:
img_dir = os.path.join(self.savedir, str(page))
if not os.path.exists(img_dir):
os.makedirs(img_dir)
filename = os.path.join(self.savedir, str(page), img.split('/')[-1])
with open(filename, 'wb') as f:
f.write(requests.get(img).content)
print('图片下载成功....')
contents.append(Content(create_time=created_time, text=text))
return contents
if __name__ == '__main__':
id = "5305630013"
wb = WeiboSpider(id)
user = wb.get_user_info()
pages = int(input("请输入爬取博客的页数:"))
for page in range(pages):
contents = wb.get_content(page + 1)
for content in contents:
print(content.create_time, content.text)
效果展示

拓展
- 这个项目也可以使用urllib模块实现, 只是requests是基于urllib封装的模块, 使用更加友好.当然也可以使用Scrapy爬虫框架.
参考资料: