简介
LSTM是一种时间递归神经网络,是RNN的一个变种,非常适合处理和预测时间序列中间隔和延迟非常长的事件。假设我们去试着预测‘I grew up in France…(很长间隔)…I speak fluent French’最后的单词,当前的信息建议下一个此可能是一种语言的名字,但是要准确预测出‘French’我们就需要前面的离当前位置较远的‘France’作为上下文,当这个间隔比较大的时候RNN就会难以处理,而LSTM则没有这个问题。
一、思路:
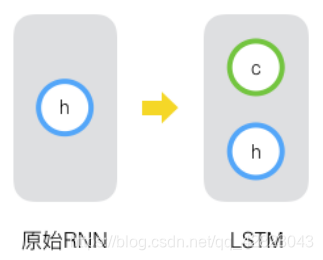
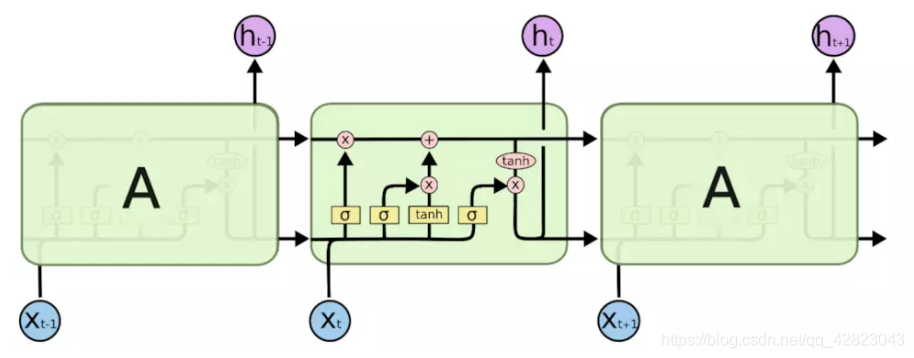
原始 RNN 的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。再增加一个状态,即c,让它来保存长期的状态,称为单元状态(cell state)。
把上图按照时间维度展开:
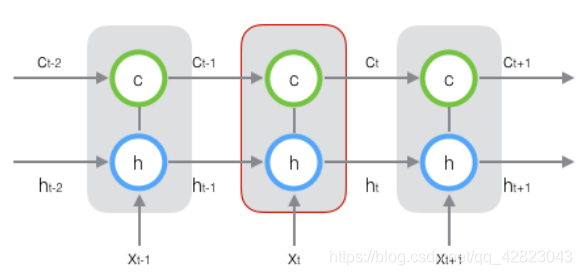
在 t 时刻,LSTM的输入有三个:当前时刻网络的输入值Xt,上一时刻LSTM的输出值ht-1,以及上一时刻的单元状态ct-1。
而它的输出有两个:当前时刻LSTM输出值 ht、和当前时刻的单元状态ct。 ps: x 、h、 c都是向量。
LSTM的关键:就是怎样控制长期状态c ?
在这里,LSTM的思路是使用三个门控开关。
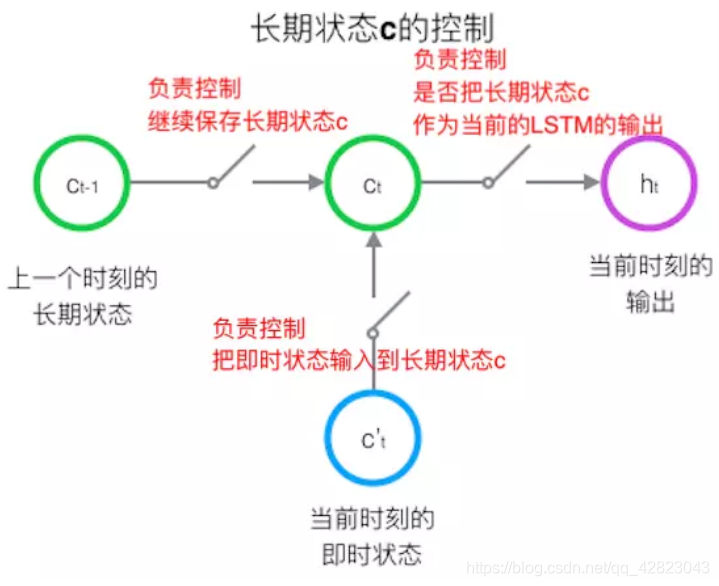
第一个开关,负责控制继续保存长期状态c;
第二个开关,负责控制把即时状态输入到长期状态c;
第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
三个开关的作用如下图所示:
如何在算法中实现这三个开关?
方法:用 门(gate)
定义:gate 实际上就是一层全连接层,输入是一个向量,输出是一个 0到1 之间的实数向量。
公式为:
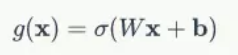
原理:门的输出是 0到1 之间的实数向量,当门输出为 0 时,任何向量与之相乘都会得到 0 向量,这就相当于什么都不能通过;
输出为 1 时,任何向量与之相乘都不会有任何改变,这就相当于什么都可以通过。
二、LSTM 的前向计算:
1.遗忘门的计算:
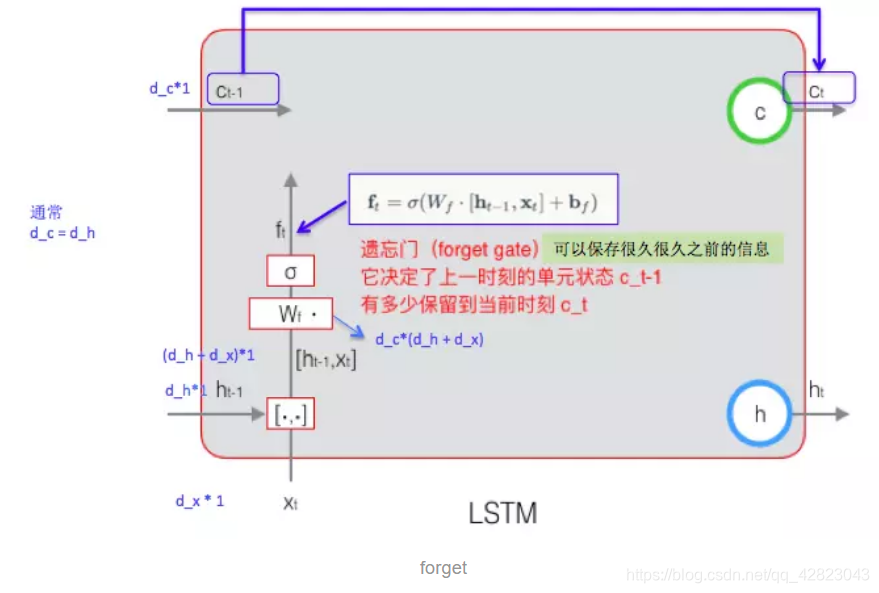
计算公式中:Wf 是遗忘门的权重矩阵,[ht-1, xt] 表示把两个向量连接成一个更长的向量,bf 是遗忘门的偏置项,σ 是 sigmoid 函数。
2.输入门的计算:
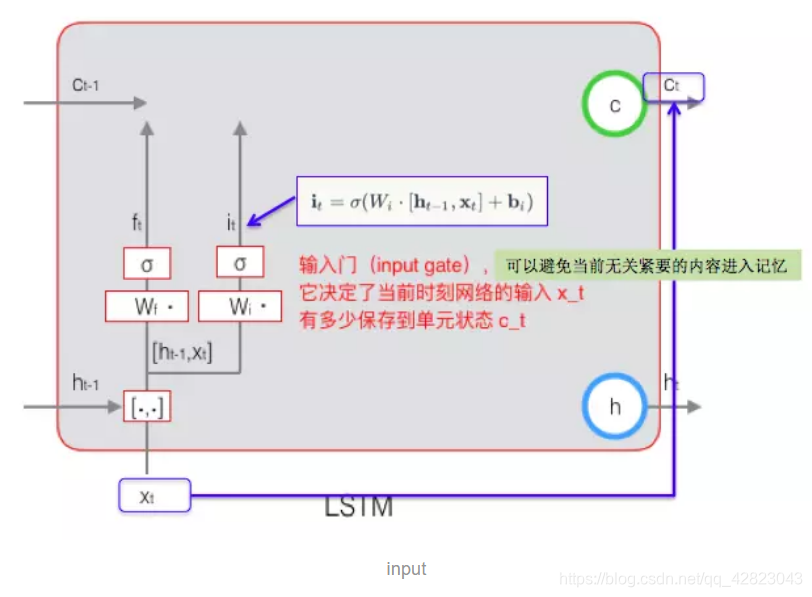

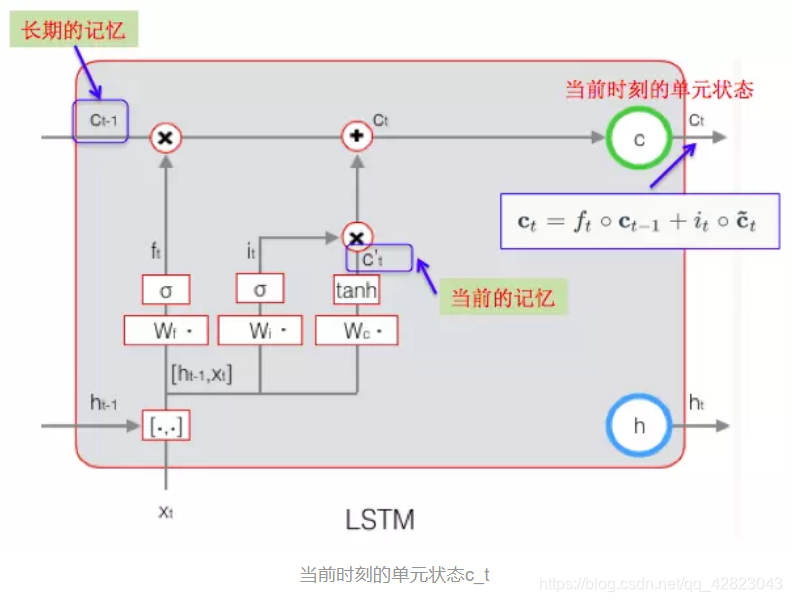
当前时刻的单元状态 ct 的计算:由上一次的单元状态 ct-1 按元素乘以遗忘门 ft,再用当前输入的单元状态 ct 按元素乘以输入门 it,再将两个积加和,这样,就可以把当前的记忆 c’t 和长期的记忆 ct-1 组合在一起,形成了新的单元状态 ct。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免当前无关紧要的内容进入记忆。
3.输出门的计算:
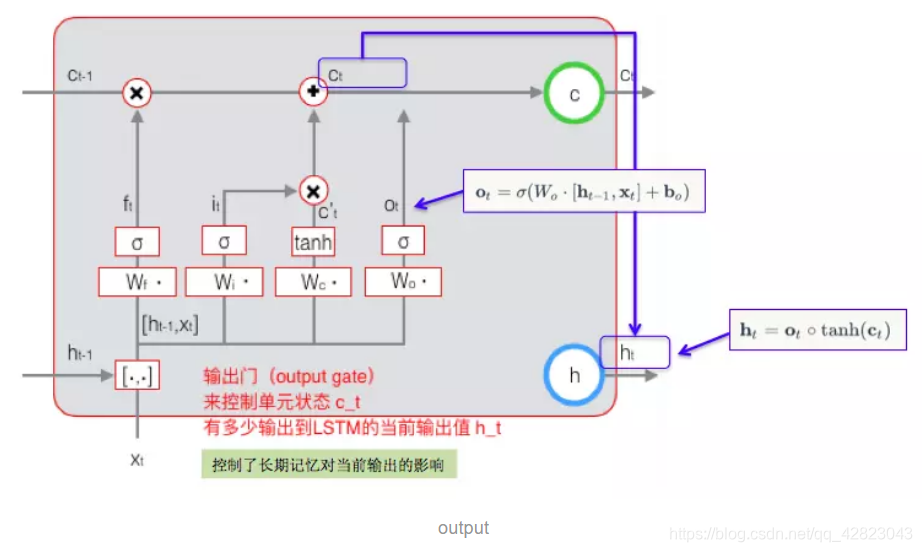
三、LSTM 的反向传播训练算法:
- 前向计算每个神经元的输出值,一共有 5 个变量,计算方法就是前一部分:
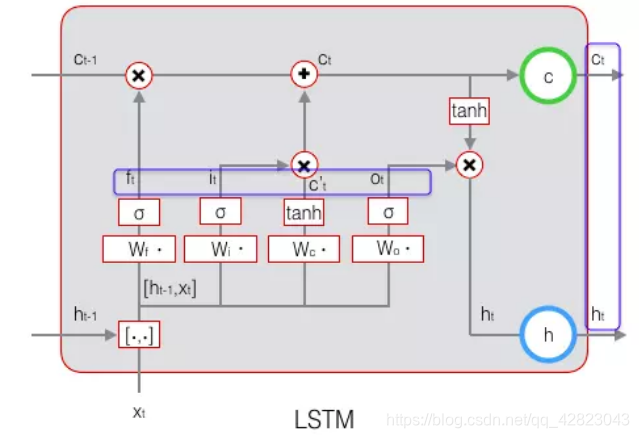
- 反向计算每个神经元的误差项值。与 RNN 一样,LSTM 误差项的反向传播也是包括两个方向:
一个是沿时间的反向传播,即从当前 t 时刻开始,计算每个时刻的误差项;
一个是将误差项向上一层传播。 - 根据相应的误差项,计算每个权重的梯度。
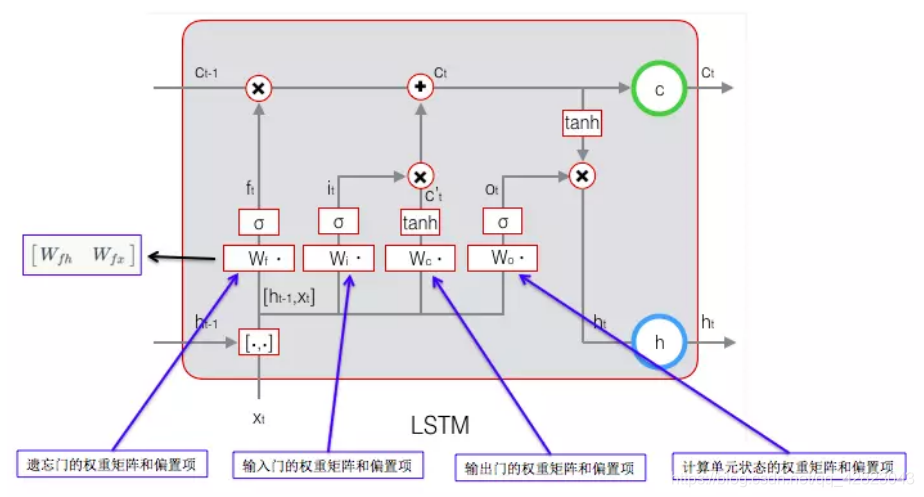
目标是要学习 8 组参数,如下图所示:
结论:
此前,我提到人们通过RNN实现了显着的成果。 基本上所有这些都是使用LSTM实现的。 对于大多数任务而言LSTM很有效。