1、LSTM结构图如下:
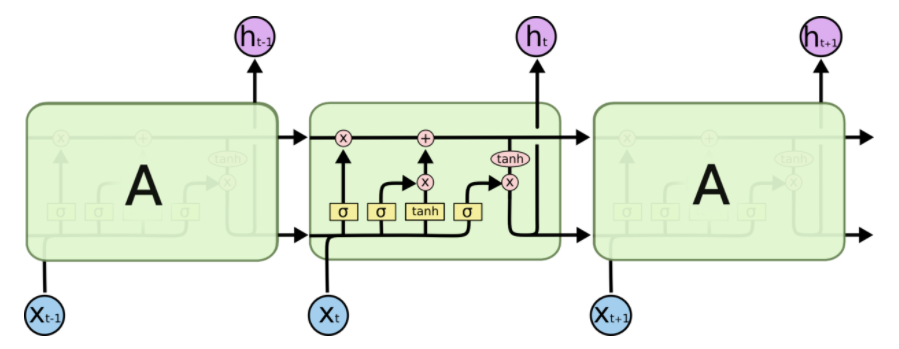
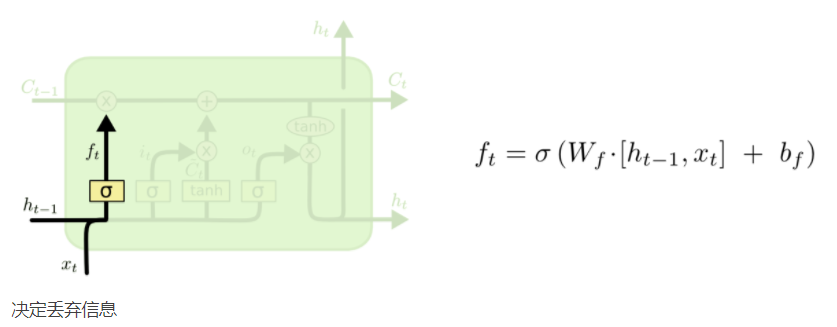
2、分块理解:
① 在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取 h_{t-1} 和 x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态 C_{t-1} 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
② 下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。
第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。
然后,一个 tanh 层创建一个新的候选值向量,{C}_t(C上加波浪线),会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
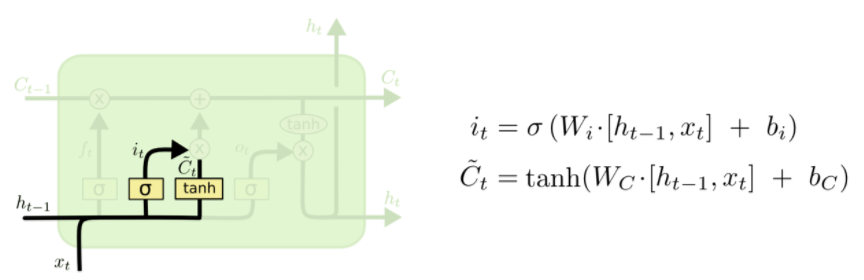
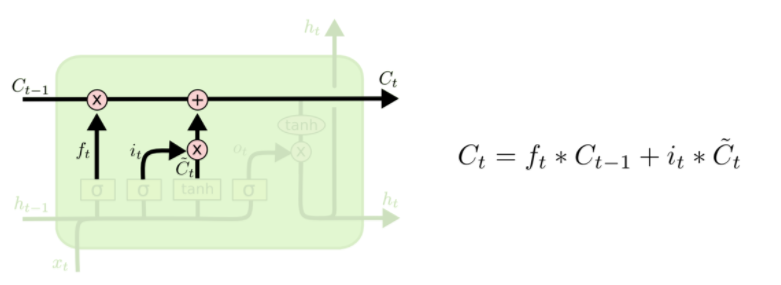
③现在是更新旧细胞状态的时间了,C_{t-1} 更新为 C_t。前面的步骤已经决定了将会做什么,我们现在就是实际去完成。
我们把旧状态与 f_t 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 i_t * \tilde{C}_t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
④ 最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个 代词,可能需要输出与一个 动词 相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
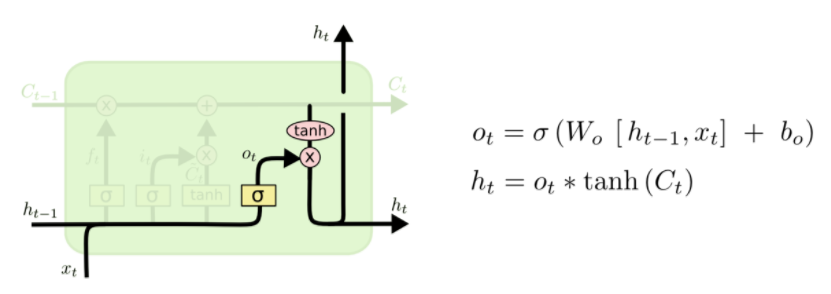
总结:斯坦福大学李飞飞课件中对LSTM的结构表述如下:

跟上述分步骤解析的LSTM思想一样,对应关系自己总结如下:
