Introduction
您使用哪种算法进行对象检测任务? 为了在最短的时间内构建最精确的模型,我尝试了其中的一些。 这个跨越多个黑客马拉松和现实世界数据集的旅程通常总是让我进入R-CNN系列算法。
对我来说这是一个令人难以置信的有用框架,这就是为什么我决定以一系列文章的形式写下我的学习内容。 本系列背后的目的是展示不同类型的R-CNN算法的有用性。 第一部分得到了我们社区的绝对积极回应,我很高兴提出第二部分!

在本文中,我们将首先简要总结我们在第1部分中学到的内容,然后深入探讨R-CNN系列中最快成员的实现 - 更快的R-CNN。 如果您需要首先刷新对象检测概念,我强烈建议您阅读本文:基本对象检测算法的逐步介绍(第1部分)。
我们将在这里开发一个非常有趣的数据集,让我们一起潜入!
Table of Contents
- 用于物体检测的不同R-CNN算法的简要概述
- 理解问题陈述
- 设置系统
- 数据探索
- 实施更快的R-CNN
目标检测的不同R-CNN算法简述
让我们快速总结一下我们在第一篇文章中看到的R-CNN系列(R-CNN,快速R-CNN和更快的R-CNN)中的不同算法。 当我们预测先前看不见的图像(新数据)中出现的边界框时,这将有助于为我们的实施部分奠定基础。
R-CNN使用选择性搜索从给定图像中提取一组区域,然后检查这些框中是否包含任何对象。 我们首先提取这些区域,并且对于每个区域,CNN用于提取特定特征。 最后,这些功能随后用于检测对象。 不幸的是,由于该过程中涉及的这些多个步骤,R-CNN变得相当慢。

另一方面,快速R-CNN将整个图像传递给ConvNet,后者生成感兴趣的区域(而不是从图像中传递提取的区域)。 此外,它不使用三种不同的模型(如我们在R-CNN中所见),而是使用单个模型从区域中提取特征,将它们分类到不同的类中,并返回边界框。
所有这些步骤都是同时完成的,因此与R-CNN相比,它的执行速度更快。 然而,快速R-CNN在应用于大型数据集时速度不够快,因为它还使用选择性搜索来提取区域。
更快的R-CNN通过用区域提议网络(RPN)替换它来解决选择性搜索的问题。 我们首先使用ConvNet从输入图像中提取特征图,然后通过返回对象提议的RPN传递这些图。 最后,对这些地图进行分类并预测边界框。

我在下面总结了更快的R-CNN算法检测图像中对象的步骤:
- 获取输入图像并将其传递给ConvNet,后者返回图像的特征图
- 在这些要素图上应用区域提议网络(RPN)并获取对象提议
- 应用ROI池层将所有提案降低到相同的大小
- 最后,将这些提议传递给完全连接的图层,以便对图像的边界框进行预测
比表格格式更好地比较这些不同算法的方法有哪些? 所以你走吧!

现在我们已经掌握了这个主题,现在是时候从理论跳到我们文章的实际部分了。 让我们使用一个非常酷(而且非常有用)的数据集来实现更快的R-CNN,这些数据集具有潜在的真实应用程序!
理解问题陈述
我们将致力于医疗保健相关数据集,目的是解决血细胞检测问题。 我们的任务是通过显微图像读数检测每张图像中的所有红细胞(RBC),白细胞(WBC)和血小板。 以下是我们最终预测应如下所示的示例:

选择该数据集的原因是我们血液中的红细胞,白细胞和血小板的密度提供了大量关于免疫系统和血红蛋白的信息。这可以帮助我们潜在地识别一个人是否健康,如果在他们的血液中发现任何差异,可以迅速采取行动来诊断。
通过显微镜手动查看样品是一个繁琐的过程。这就是深度学习模型发挥如此重要作用的地方。他们可以以惊人的精确度从显微图像中分类和检测血细胞。
我们的挑战的全血细胞检测数据集可以从这里下载。我已经为本文的范围稍微修改了一些数据:
- 边界框已从给定的.xml格式转换为.csv格式
- 我还通过随机选择拆分图像,在整个数据集上创建了训练和测试集拆分
请注意,我们将使用流行的Keras框架和Python中的TensorFlow后端来训练和构建我们的模型。
设置系统
在我们实际进入模型构建阶段之前,我们需要确保已安装正确的库和框架。运行此项目需要以下库:
- Pandas
- matplotlib
- tensorflow
- keras - 2.0.3
- numpy
- opencv-python
- sklearn
- h5py
如果您安装了Anaconda和Jupyter笔记本电脑,大多数上述库都已存在于您的机器上。此外,我建议从此链接下载requirements.txt文件并使用它来安装剩余的库。在终端中键入以下命令来执行此操作:
pip install -r requirement.txt
好的,我们的系统现已设置好,我们可以继续处理数据了!
数据探索
首先探索我们拥有的数据总是一个好主意(坦率地说,这是一个强制性的步骤)。这有助于我们不仅挖掘出隐藏的模式,而且还可以获得对我们正在使用的内容的宝贵整体洞察力。我从整个数据集中创建的三个文件是:
- 1 train_images:我们将用于训练模型的图像。我们有这个文件夹中每个类的类和实际边界框。
- 2个test_images:此文件夹中的图像将用于使用训练模型进行预测。这个集合缺少这些类的类和边界框。
- 3 train.csv:包含每个图像的名称,类和边界框坐标。一个图像可以有多行,因为单个图像可以有多个对象。
让我们读一下.csv文件(如果您想尝试,可以从原始数据集创建自己的.csv文件)并打印出前几行。我们需要先为此导入以下库:
# importing required libraries
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib import patches
# read the csv file using read_csv function of pandas
train = pd.read_csv(‘train.csv’)
train.head()
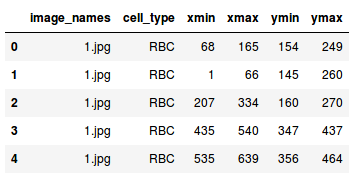
列车档案中有6列。 让我们理解每列代表的内容:
- image_names:包含图像的名称
- cell_type:表示单元的类型
- xmin:图像左下角的x坐标
- xmax:图像右上角的x坐标
- ymin:图像左下角的y坐标
- ymax:图像右上角的y坐标
现在让我们打印一张图片来想象我们正在使用的内容:
# reading single image using imread function of matplotlib
image = plt.imread('images/1.jpg')
plt.imshow(image)

这就是血细胞图像的样子。 这里,蓝色部分代表WBC,略带红色的部分代表RBC。 让我们来看看我们的训练集中有多少图像和不同类型的类。
# Number of unique training images
train['image_names'].nunique()
所以,我们有254个训练图像。
# Number of classes
train['cell_type'].value_counts()

我们有三种不同类型的细胞,即RBC,WBC和血小板。 最后,让我们看看具有检测到的对象的图像将如何:
fig = plt.figure()
#add axes to the image
ax = fig.add_axes([0,0,1,1])
# read and plot the image
image = plt.imread('images/1.jpg')
plt.imshow(image)
# iterating over the image for different objects
for _,row in train[train.image_names == "1.jpg"].iterrows():
xmin = row.xmin
xmax = row.xmax
ymin = row.ymin
ymax = row.ymax
width = xmax - xmin
height = ymax - ymin
# assign different color to different classes of objects
if row.cell_type == 'RBC':
edgecolor = 'r'
ax.annotate('RBC', xy=(xmax-40,ymin+20))
elif row.cell_type == 'WBC':
edgecolor = 'b'
ax.annotate('WBC', xy=(xmax-40,ymin+20))
elif row.cell_type == 'Platelets':
edgecolor = 'g'
ax.annotate('Platelets', xy=(xmax-40,ymin+20))
# add bounding boxes to the image
rect = patches.Rectangle((xmin,ymin), width, height, edgecolor = edgecolor, facecolor = 'none')
ax.add_patch(rect)

这就是训练示例的样子。 我们有不同的类及其相应的边界框。 现在让我们在这些图像上训练我们的模型。 我们将使用keras_frcnn库来训练我们的模型以及获得测试图像的预测。
实现更快的R-CNN
为了实现更快的R-CNN算法,我们将遵循this Github repository中提到的步骤。 因此,作为第一步,请确保克隆此存储库。 打开一个新的终端窗口并键入以下内容以执行此操作:
git clone https://github.com/kbardool/keras-frcnn.git
将train_images和test_images文件夹以及train.csv文件移动到克隆的存储库。 为了在新数据集上训练模型,输入的格式应为:
filepath,x1,y1,x2,y2,class_name
其中,
- filepath是训练图像的路径
- x1是边界框的xmin坐标
- y1是边界框的ymin坐标
- x2是边界框的xmax坐标
- y2是边界框的ymax坐标
- class_name是该边界框中类的名称
我们需要将.csv格式转换为.txt文件,该文件具有与上述相同的格式。 创建一个新的数据帧,按照格式将所有值填入该数据帧,然后将其另存为.txt文件。
data = pd.DataFrame()
data['format'] = train['image_names']
# as the images are in train_images folder, add train_images before the image name
for i in range(data.shape[0]):
data['format'][i] = 'train_images/' + data['format'][i]
# add xmin, ymin, xmax, ymax and class as per the format required
for i in range(data.shape[0]):
data['format'][i] = data['format'][i] + ',' + str(train['xmin'][i]) + ',' + str(train['ymin'][i]) + ',' + str(train['xmax'][i]) + ',' + str(train['ymax'][i]) + ',' + train['cell_type'][i]
data.to_csv('annotate.txt', header=None, index=None, sep=' ')
下一步是什么?
训练我们的模型! 我们将使用train_frcnn.py文件来训练模型。
cd keras-frcnn
python train_frcnn.py -o simple -p annotate.txt
由于数据的大小,需要一段时间来训练模型。如果可能,您可以使用GPU来加快培训阶段。您还可以尝试减少时期数作为备用选项。要更改纪元数,请转到克隆存储库中的train_frcnn.py文件,并相应地更改num_epochs参数。
每次模型看到改进时,该特定历元的权重将保存在与“model_frcnn.hdf5”相同的目录中。当我们对测试集进行预测时,将使用这些权重。
根据机器的配置,可能需要花费大量时间来训练模型并获得重量。我建议使用我训练模型后大约500个时期的重量。您可以从此处下载这些权重。确保将这些权重保存在克隆的存储库中。
所以我们的模型已经过训练并且设置了权重。这是预测时间! Keras_frcnn对新图像进行预测并将其保存在新文件夹中。我们只需在test_frcnn.py文件中进行两处更改即可保存图像:
- 1从此文件的最后一行删除注释:
cv2.imwrite(“./ results_imgs / {}。png’.format(IDX),IMG) - 2在此文件的倒数第二行和第三行添加注释:
#cv2.imshow(‘img’,img)
#cv2.waitKey(0)
让我们为新图像做出预测:
python test_frcnn.py -p test_images
最后,包含检测到的对象的图像将保存在“results_imgs”文件夹中。 以下是我在实施更快的R-CNN后得到的预测的几个例子:




End Notes
R-CNN算法确实是用于对象检测任务的游戏改变者。 近年来,计算机视觉应用程序的数量突然出现飙升,而R-CNN是其中大多数应用程序的核心。
Keras_frcnn被证明是一个优秀的对象检测库,在本系列的下一篇文章中,我们将专注于更高级的技术,如YOLO,SSD等。
如果您对我们所涵盖的内容有任何疑问或建议,请随时在下面的评论部分发布,我们很乐意与您联系!