简介
经过R-CNN和Fast R-CNN的积淀,Ross B. Girshick在2016年提出了新的Faster R-CNN,在结构上,Faster R-CNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
原论文地址:https://arxiv.org/abs/1506.01497
一、整体框架
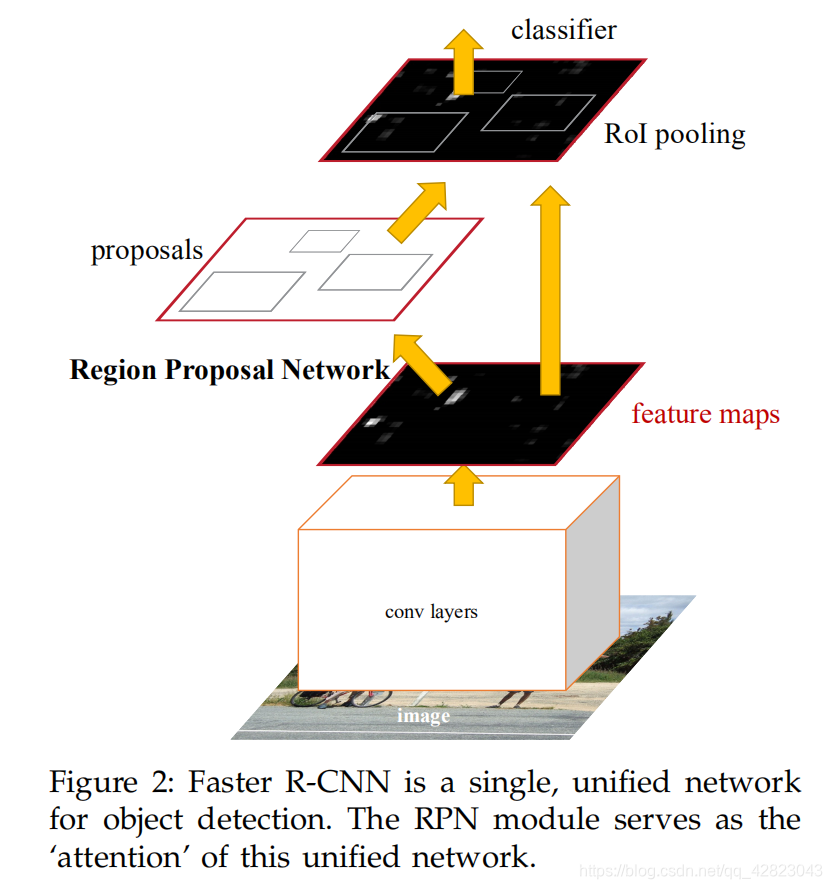
从上图来看,Faster R-CNN其实可以分为4个主要内容:
- Conv layers提取特征图:Faster R-CNN首先使用一组基础的conv+relu+pooling层提取input image的feature maps,该feature maps会用于后续的RPN层和全连接层。
- RPN(Region Proposal Networks): RPN网络主要用于生成region proposals,首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景还是背景,即是物体or不是物体,所以这是一个二分类。同时,另一分支bounding box regression修正anchor box,形成较精确的proposal。
- ROI Pooling:该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位。
- Classifier分类:会将ROI Pooling层形成固定大小的feature map进行全连接操作,利用Softmax进行具体类别的分类,同时,利用L1 Loss完成bounding box regression回归操作获得物体的精确位置。
二、VGG16模型中的Faster R-CNN的网络结构
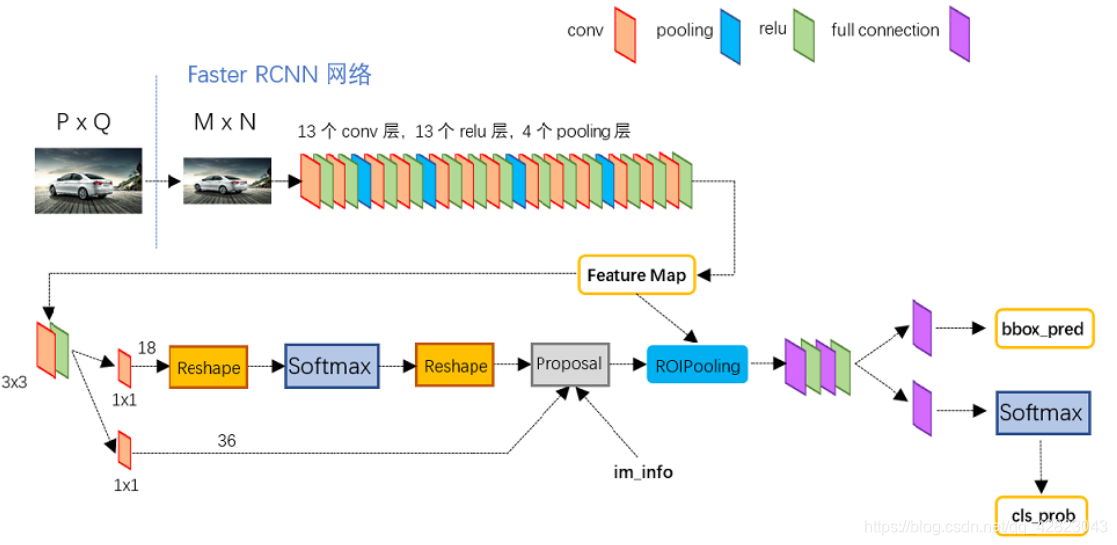
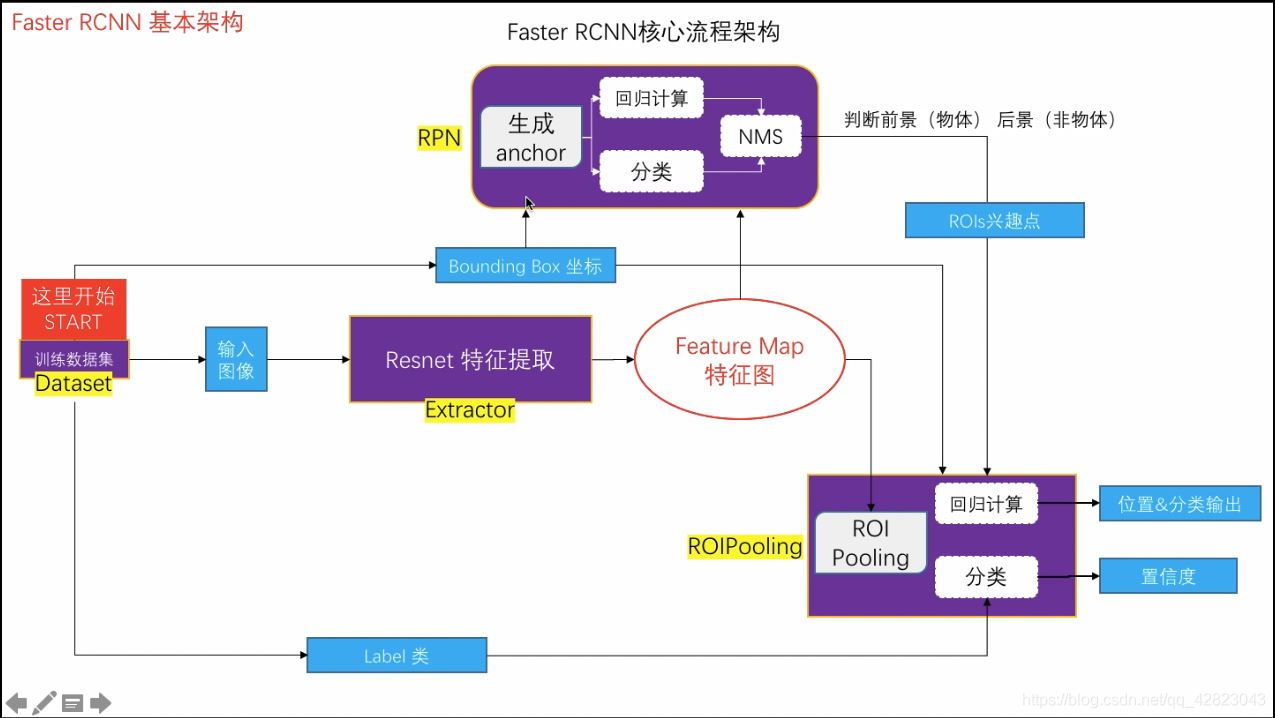
- Conv layers:
Faster R-CNN首先是支持输入任意大小的图片的,比如上图中输入的P*Q,Conv layers部分共有13个conv层,13个relu层,4个pooling层。
所有的conv层都是:kernel_size=3,pad=1,stride=1。conv层不会改变图片大小。
所有的pooling层都是:kernel_size=2,stride=2。pooling层会让输出图片是输入图片的1/2。 - RPN(Region Proposal Networks):
RPN 的用途在于, 判断需要处理的图片区域, 以降低推断时的计算量。RPN 快速有效的扫描图片中每一个位置, 以判断给定区域是否需要进一步处理.。
Feature Map进入RPN后,先经过一个3x3卷积,这样做的目的应该是进一步集中特征信息,接着看到两个1x1卷积(对多通道图像做1x1卷积,其实就是将输入图像于每个通道乘以卷积系数后加在一起,即相当于把原图像中本来各个独立的通道“联通”在了一起)。
RPN网络实际分为2条线,上面一条classification 分支:通过softmax分类anchors获得foreground和background(检测目标是foreground),classification 分支输出一个概率值, 表示 bounding-box 中是否包含 object (classid = 1), 或者是 background (classid = 0), no object。
下面一条regression 分支用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。regression 分支输出预测的边界框bounding-box: (x, y, w, h)。
而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal这里,就完成了相当于目标定位的功能。
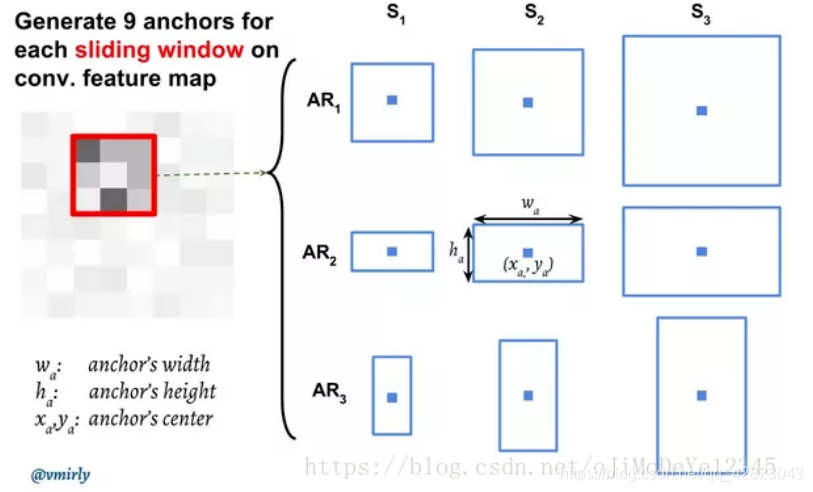
anchor生成:在 feature maps 上进行滑窗操作(sliding window)。对于每个滑窗, 会生成 9 个 anchors, anchors 具有相同的中心,但 anchors 具有 3 种不同的长宽比(aspect ratios) 和 3 种不同的尺度(scales), 计算是相对于原始图片尺寸的。对于每个 anchor, 计算 anchor 与 ground-truth bounding boxes 的重叠部分(overlap) 值P*。
如果 IoU > 0.7, 则 P*=1;
如果 IoU < 0.3, 则 P*=−1; - RoI Pooling:
而RoI Pooling层则负责收集proposal,并计算出proposal feature maps,送入后续网络。
可以看到Rol pooling层有2个输入:原始的feature maps和RPN输出的proposal boxes(大小各不相同)。 - Classification:
Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框。
系列传送门:
目标检测——R-CNN(一)
目标检测——Fast R-CNN(二)
目标检测——Mask R-CNN(四)
目标检测——R-FCN(五)
目标检测——YOLOv3(六)
目标检测——YOLOv4(七)