RDD:弹性分布式数据集,是一种特殊集合,支持多来源,有容错机制,可以被缓存,支持并行操作,一个RDD代表多个分区里的数据集。
RDD有两种算子:
1.Transformation(转换):属于延迟Lazy计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住数据集的逻辑操作;
2.Action(执行):触发Spark作业运行,真正触发转换算子的计算;
RDD中算子的运行过程:
输入:
在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
运行:
在Spark数据输入形成RDD后便可以通过变换算子,如filter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业,。如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
输出:
程序运行结束,数据会输出Spark运行时的空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala Int型数据)
常见的Transformation(转换)算子:
- map(func):返回一个新的分布式数据集,由每个原元素经过func函数转换组成,one to one的操作;
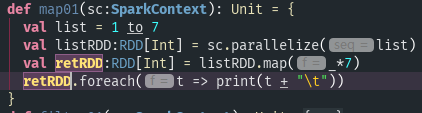
运行结果

- filter(func):返回一个新的数据集,由经过func函数后返回值为true的元素组成;
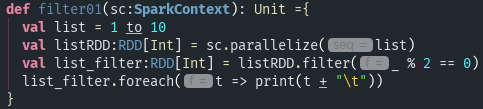
运行结果

- flatMap(func):类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此func函数返回值是一个Seq,而不是单个元素),one to many的操作;
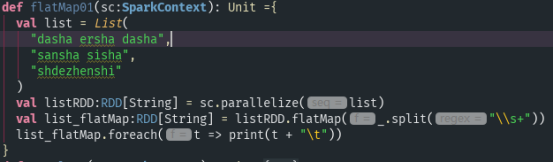
运行结果

- sample(withReplacement,fraction,seed):根据给定的随机种子seed,随机抽样成数量为frac的数据;
三个参数:
withReplacement:抽样是否有放回
fraction:抽样比例
seed:随机数生成器
Spark中的这个sample抽样算子是不准确的
sample进程用在查看RDD中key的分布情况,一个最经典的应用案例就在处理Spark的数据倾斜

运行结果
- union(otherDataset):返回一个新的数据集,有原数据集和参数联合而成
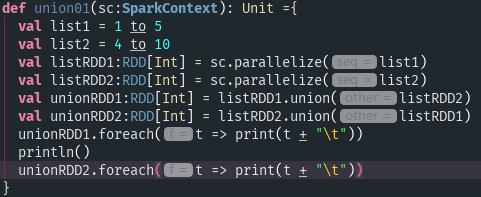
运行结果

- groupByKey([numTasks]):在一个由(k,v)对组成的数据集上调用,返回一个(k,Seq[v])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task;
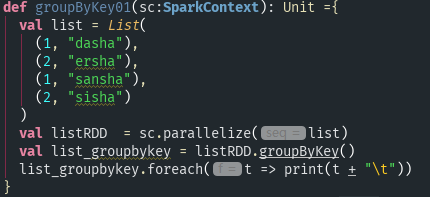
运行结果

- reduceByKey(func,[numTasks]):在一个(k,v)对的数据集上使用,返回一个(k,v)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupByKey类似,任务的个数可以是通过第二个可选参数来配置的。
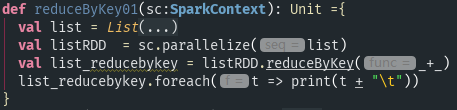
运行结果

- join(otherDataset,[numTasks]):在类型为(k,v)和(k,w)类型的数据集上调用,返回一个(k,(v,w))对,每个key中所有元素都在一起的数据集

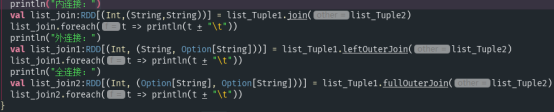
运行结果

9. groupWith(oterDataset,[numTasks]):在类型为(k,v)和(k,w)类型的数据集上调用,返回一个数据集,组成元素为(k,Seq[v],Seq[w])Tuples。这个操作在其他框架,称为CoGroup。
10. cartesian(otherDataset):笛卡尔积。在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行迪卡尔积。
11. sortByKey:在一个(k,v)对的数据集上使用,返回一个(k,v)对的数据集,根据k进行排序。

运行结果

12. sortBy:

运行结果

点击查看:常见Action算子小结
本人新人,希望大佬们多关照!!