简介
在Spark中转换算子并不会马上进行运算的,即所谓的“惰性运算”,而是在遇到行动算子时才会执行相应的语句的,触发Spark的任务调度开始进行计算。
所有RDD行动算子:
aggregate、collect、count、first、foreach、reduce、take、takeOrdered、takeSample、saveAsObjectFile、saveAsTextFile
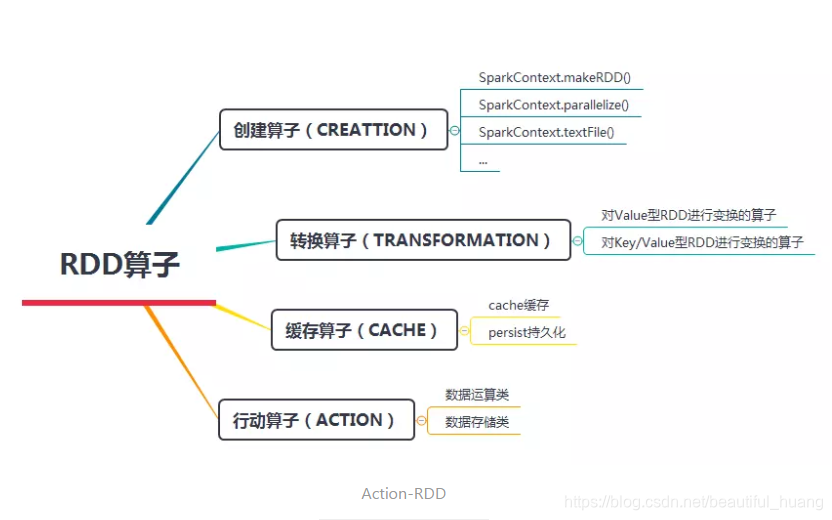
在这里我们可以将Spark中的行动算子分为两类:
- 1,数据运算类,主要用于触发RDD计算,并得到计算结果返回给Spark程序或Shell界面;
- 2,数据存储类,用于触发RDD计算后,将结果保存到外部存储系统中,如HDFS文件系统或数据库。
数据运算类行动算子
reduce——Reduce操作
reduce(func):通过函数func先聚集各分区的数据集,再聚集分区之间的数据,func接收两个参数,返回一个新值,新值再做为参数继续传递给函数func,直到最后一个元素
/**
* @Author: Stephen
* @Date: 2020/1/3 18:48
* @Content: Reduce 聚合运算
*/
object Spark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Reduce").setMaster("local[4]")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1,2,3,4,5,6))
print(rdd.reduce(_+_))
context.stop()
}
}
aggregate——聚合操作
概念
1.将每个分区里面的元素进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
2.在seq中每个值和初始值轮流比较,每个分区返回一个满足条件的值
3.在comb中将初始值和每个分区返回值聚合,得到最终结果
例子解释
1.将初始值和第一个分区中的第一个元素传递给seq函数进行计算,然后将计算结果和第二个元素传递给seq函数,直到计算到最后一个值。第二个分区中也是同理操作。最后将初始值、所有分区的结果经过combine函数进行计算(先将前两个结果进行计算,将返回结果和下一个结果传给combine函数,以此类推)
,并返回最终结果。
2.从上面的代码的输出结果可以看出,1,2,3被分到一个分区中,4,5,6被分到一个分区中。3先和第一个元素1传给seq函数,返回最小值1,然后将1和第二个元素2传给seq函数,返回1,以此类推,最后返回第一个分区中的最小值1。第二个分区一样道理,最后结果返回最小值3.最后将初始值3和两个分区的结果经过combine函数进行计算,先将初始值3和第一个分区的结果1传给combine函数,返回4,然后将4和第二个分区结果3传给combine函数,返回最终结果7。
