文章目录
- 一、准备工作
- 二、掌握转换算子
- 三、掌握行动算子
一、准备工作

(一)准备文件
1、准备本地系统文件
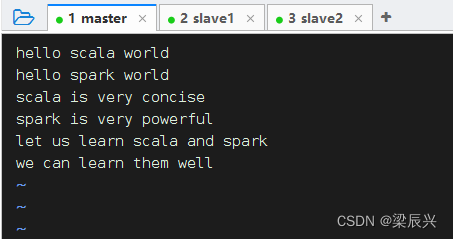
在/home目录里创建words.txt
2、把文件上传到HDFS
将words.txt上传到HDFS系统的/park目录里
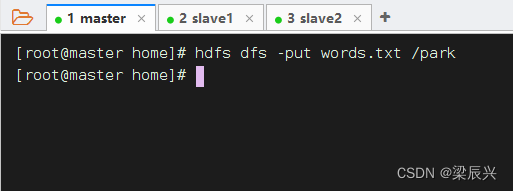
说明:/park是在上一讲我们创建的目录
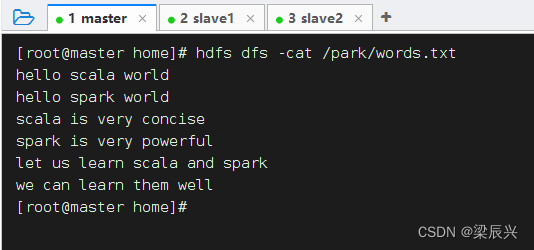
查看文件内容
(二)启动Spark Shell
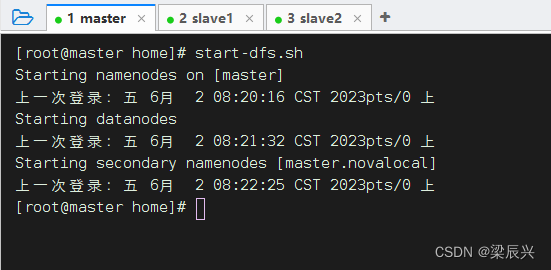
1、启动HDFS服务
执行命令:start-dfs.sh
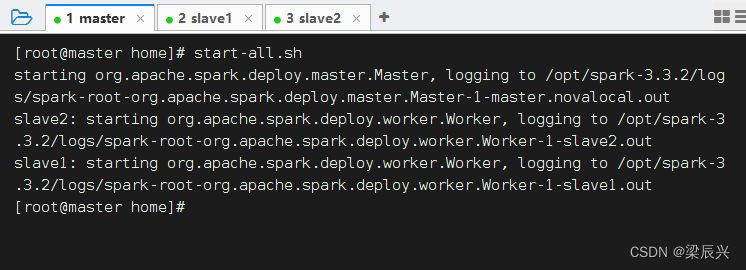
2、启动Spark服务
执行命令:start-all.sh
3、启动Spark Shell
执行名命令: spark-shell --master spark://master:7077
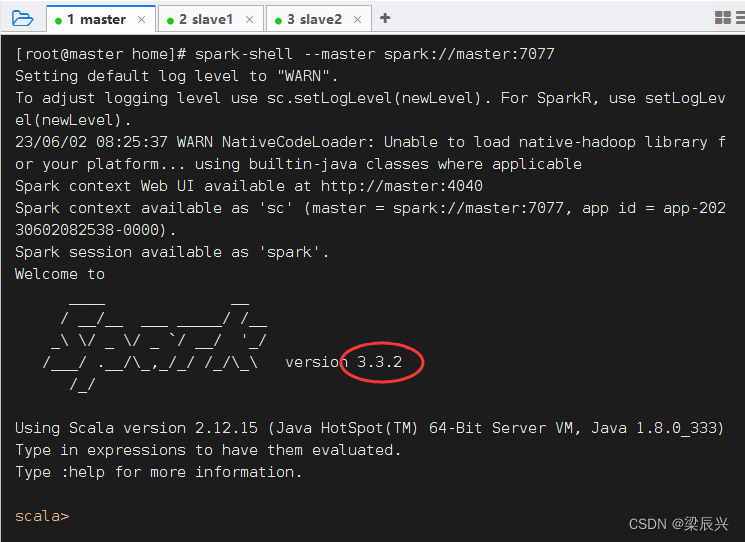
以集群模式启动的Spark Shell,不能访问本地文件,只能访问HDFS文件,加不加hdfs://master:9000前缀都是一样的效果。
二、掌握转换算子
转换算子负责对RDD中的数据进行计算并转换为新的RDD。Spark中的所有转换算子都是惰性的,因为它们不会立即计算结果,而只是记住对某个RDD的具体操作过程,直到遇到行动算子才会与行动算子一起执行。
(一)映射算子 - map()
1、映射算子功能
map()是一种转换算子,它接收一个函数作为参数,并把这个函数应用于RDD的每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
2、映射算子案例
预备工作:创建一个RDD - rdd1
执行命令:val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))

任务1、将rdd1每个元素翻倍得到rdd2
对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD

上述代码中,向算子map()传入了一个函数x = > x * 2。其中,x为函数的参数名称,也可以使用其他字符,例如a => a * 2。Spark会将RDD中的每个元素传入该函数的参数中。
其实,利用神奇占位符_可以写得更简洁
 rdd1和rdd2中实际上没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。
rdd1和rdd2中实际上没有任何数据,因为parallelize()和map()都为转化算子,调用转化算子不会立即计算结果。
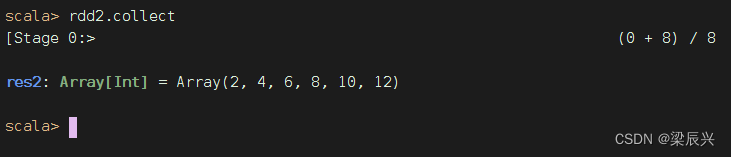
若需要查看计算结果,则可使用行动算子collect()。(collect是采集或收集之意)
执行rdd2.collect进行计算,并将结果以数组的形式收集到当前Driver。因为RDD的元素为分布式的,数据可能分布在不同的节点上。
take action: 采取行动。
函数本质就是一种特殊的映射。上面这个映射写成函数: f ( x ) = 2 x , x ∈ R
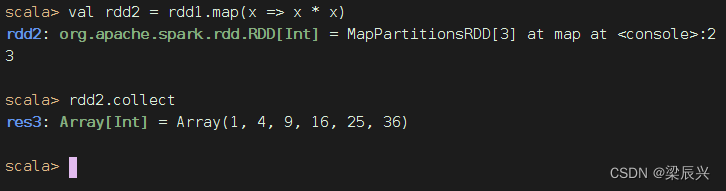
任务2、将rdd1每个元素平方得到rdd2
方法一、采用普通函数作为参数传给map()算子
方法二、采用下划线表达式作为参数传给map()算子
刚才翻倍用的是map(_ * 2),很自然地想到平方应该是map(_ * _)
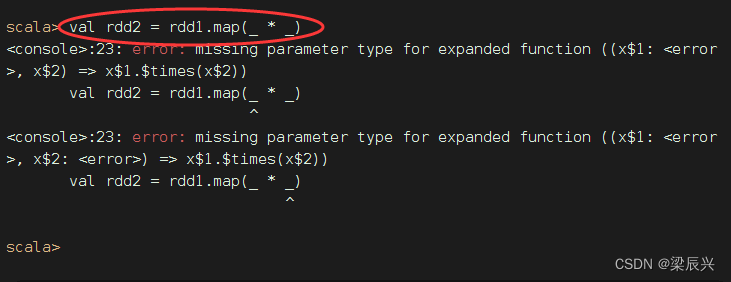 报错,
报错,(_ * _)经过eta-expansion变成普通函数,不是我们预期的x => x * x,而是(x$1, x$2) => (x$1 * x$2),不是一元函数,而是二元函数,系统立马就蒙逼了,不晓得该怎么取两个参数来进行乘法运算。
难道就不能用下划线参数了吗?当然可以,但是必须保证下划线表达式里下划线只出现1次。引入数学包scala.math._就可以搞定。
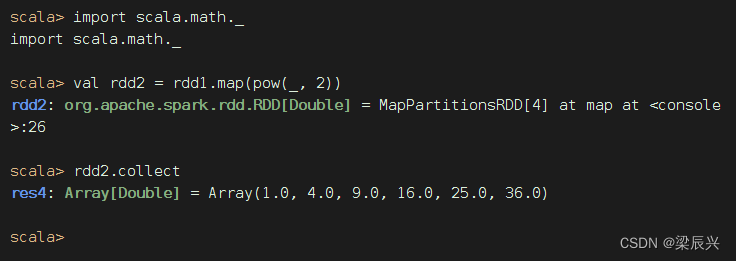
但是有点美中不足,rdd2的元素变成了双精度实数,得转化成整数
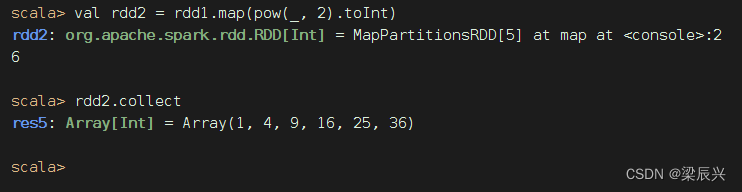
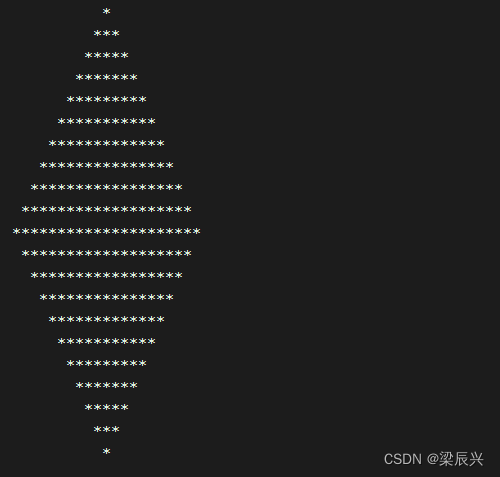
任务3、利用映射算子打印菱形
(1)Spark Shell里实现
菱形正立的等腰三角形和倒立的等腰三角形组合而成
右半菱形
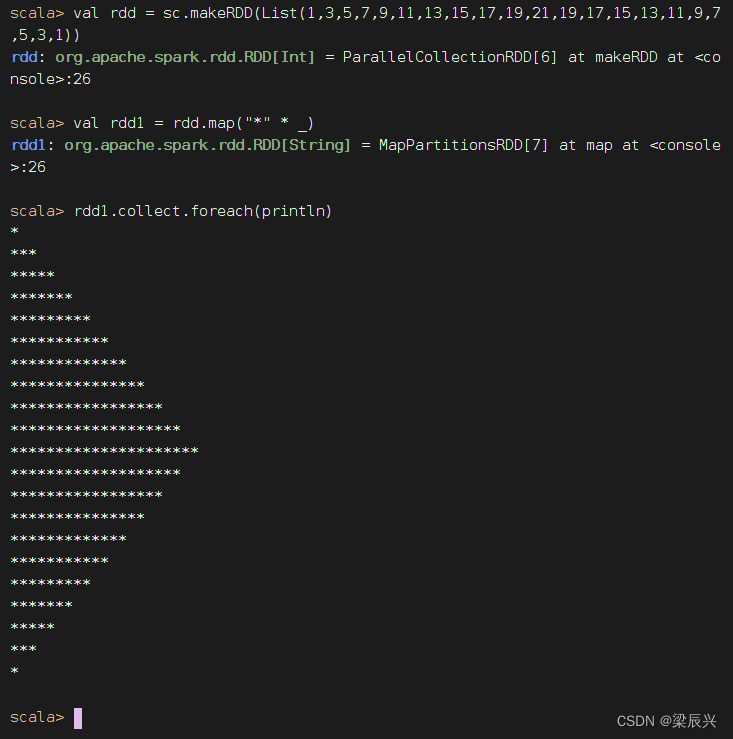
加上前导空格,左半菱形
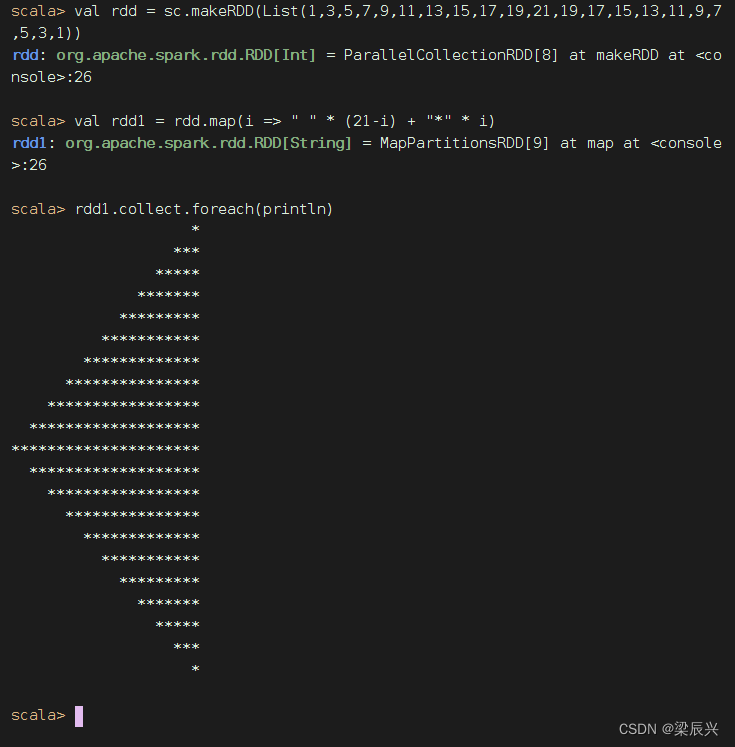
前导空格折半,显示菱形
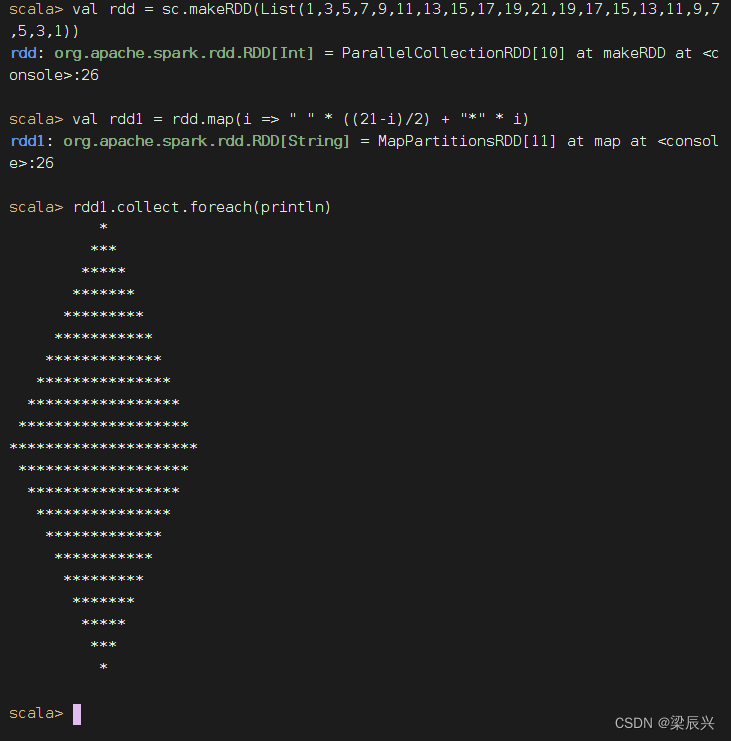
(2)在IDEA里创建项目实现
新建maven项目——SparkRDDDemo,配置如下图所示,单击【Create】按钮
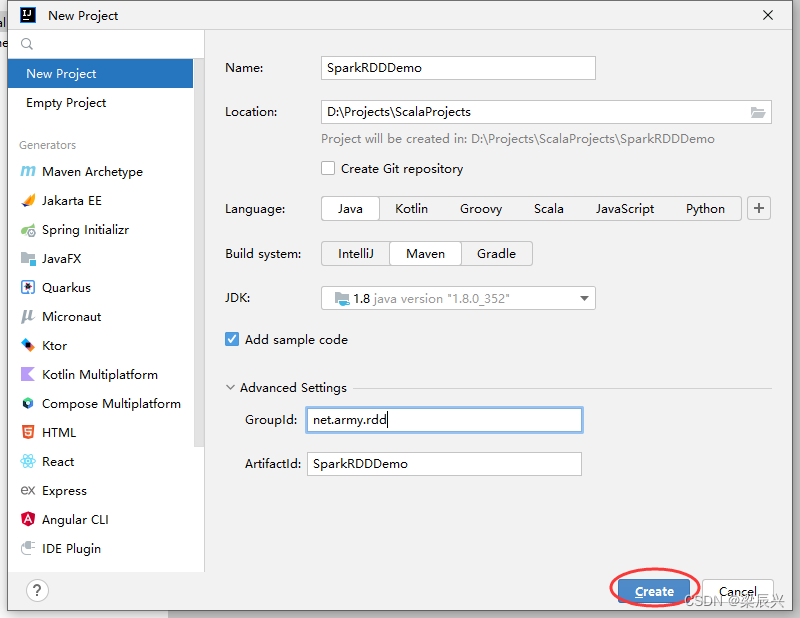
单击【Create】按钮
将java目录改成scala目录
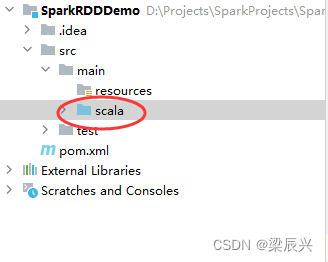
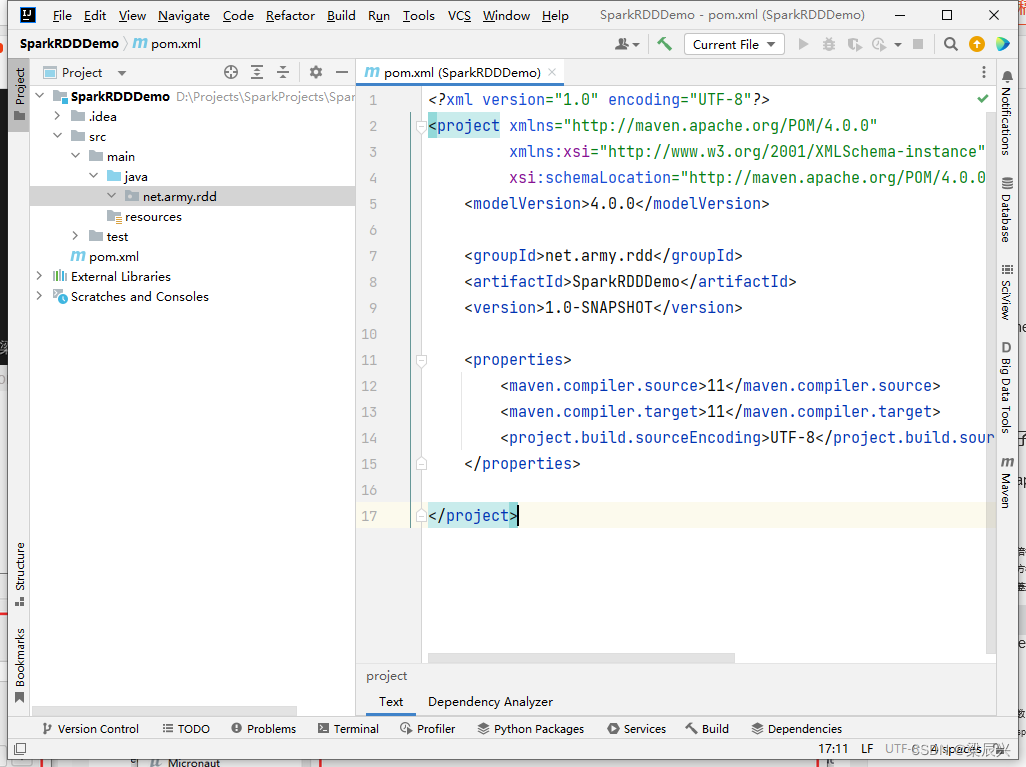
在pom.xml文件里添加相关依赖和设置源程序目录
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.army.rdd</groupId>
<artifactId>SparkRDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
</build>
</project>
刷新项目依赖
添加日志属性文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/rdd.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
创建hdfs-site.xml文件,允许客户端访问集群数据节点

<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<description>only config in clients</description>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
</property>
</configuration>
创建net.army.rdd.day01包
在net.army.rdd.day01包里创建Example01单例对象
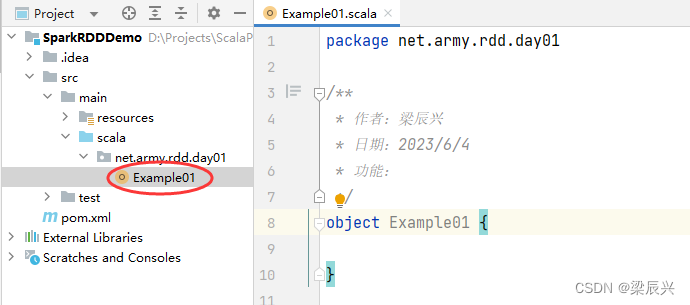
package net.army.rdd.day01
import org.apache.spark.{
SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.StdIn
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:打印钻石
*/
object Example01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 输入一个奇数
print("输入一个奇数:")
val n = StdIn.readInt()
// 创建一个可变列表
val list = new ListBuffer[Int]()
// 给列表赋值
(1 to n by 2).foreach(list.append(_))
(n - 2 to 1 by -2).foreach(list.append(_))
// 基于列表创建rdd
val rdd = sc.makeRDD(list)
// 对rdd进行映射操作
val rdd1 = rdd.map(i => " " * ((n - i) /2 ) + "*" * i)
// 输出rdd1结果
rdd1.collect.foreach(println)
}
}
运行程序,查看结果

假如用户输入一个偶数,会出现什么情况?
 修改一下代码,避免这个问题
修改一下代码,避免这个问题
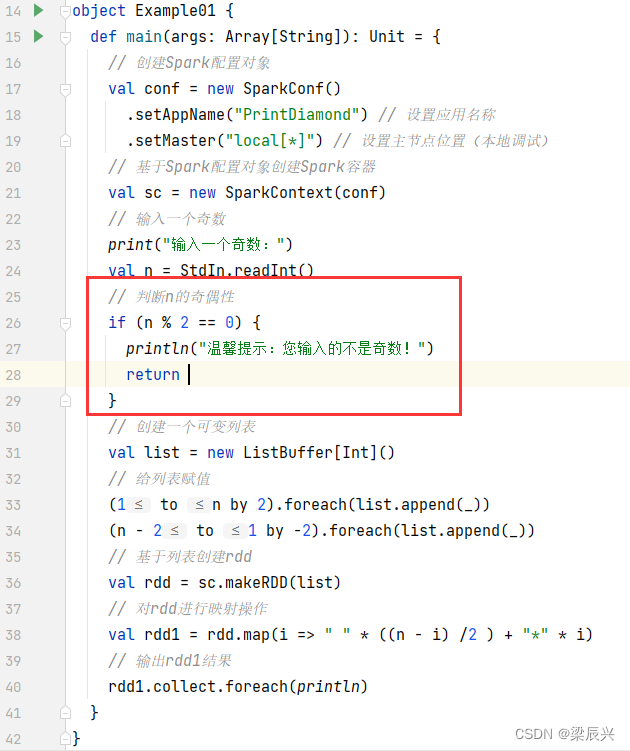
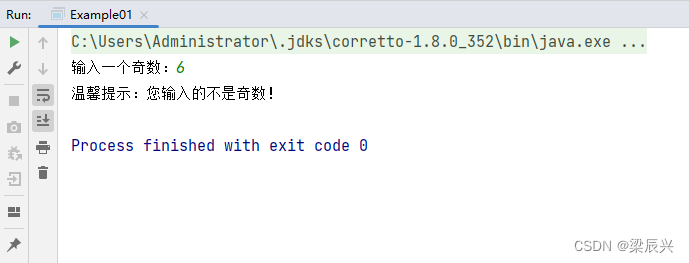
运行程序,输入一个偶数
(二)过滤算子 - filter()
1、过滤算子功能
filter(func):通过函数func对源RDD的每个元素进行过滤,并返回一个新RDD,一般而言,新RDD元素个数会少于原RDD。
2、过滤算子案例
任务1、过滤出列表中的偶数
整数(Integer):奇数(odd number)+ 偶数(even number)
基于列表创建RDD,然后利用过滤算子得到偶数构成的新RDD
方法一、将匿名函数传给过滤算子
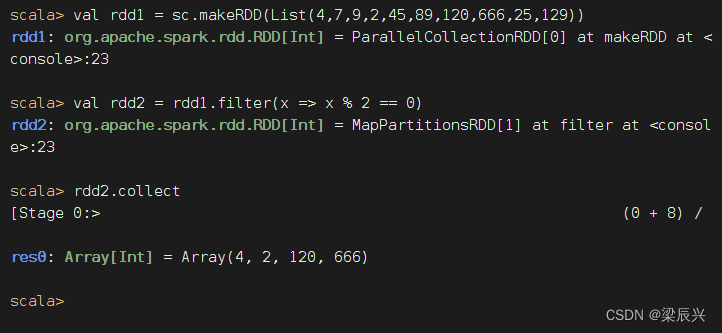
方法二、用神奇占位符改写传入过滤算子的匿名函数
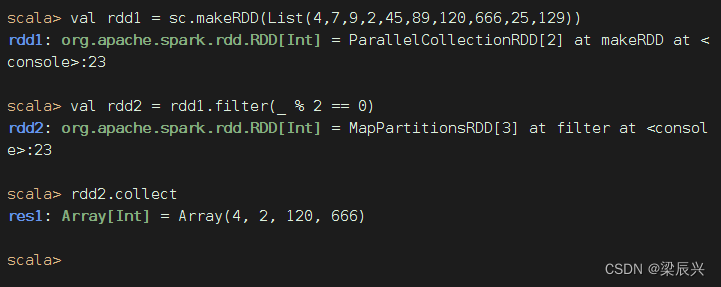
将rdd1里的每一个元素x拿去计算x % 2 == 0,如果关系表达式计算结果为真,那么该元素就丢进新RDD - rdd2,否则就被过滤掉了。
任务2、过滤出文件中包含spark的行
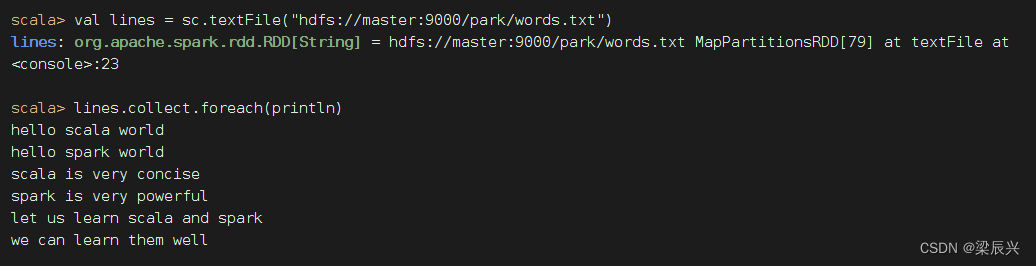
查看源文件/park/words.txt内容
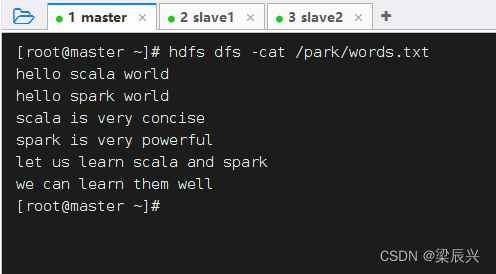
执行命令: val lines= sc.textFile(“hdfs://master:9000/park/words.txt”),读取文件 /park/words.txt生成RDD - lines

执行命令:val sparkLines = lines.filter(_.contains(“spark”)),过滤包含spark的行生成RDD - sparkLines

执行命令:sparkLines.collect,查看sparkLines内容,可以采用遍历算子,分行输出内容

输出长度超过20的行

课堂练习
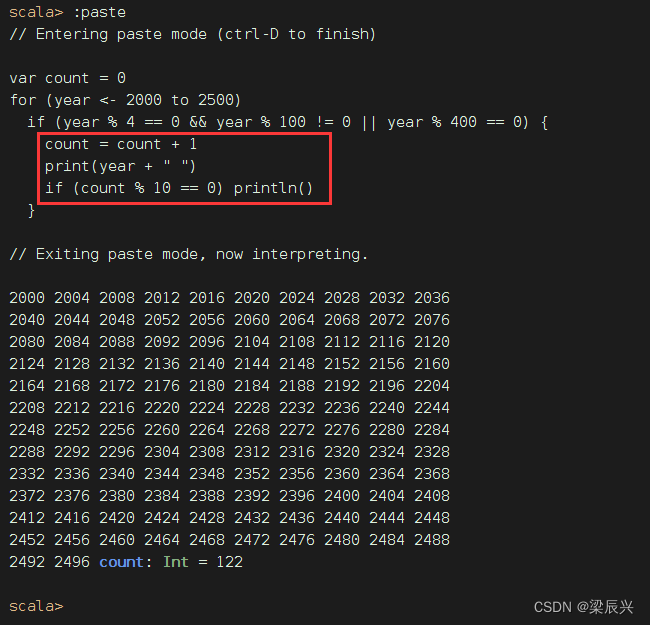
任务1、利用过滤算子输出[2000, 2500]之间的全部闰年
传统做法,利用循环结构嵌套选择结构来实现
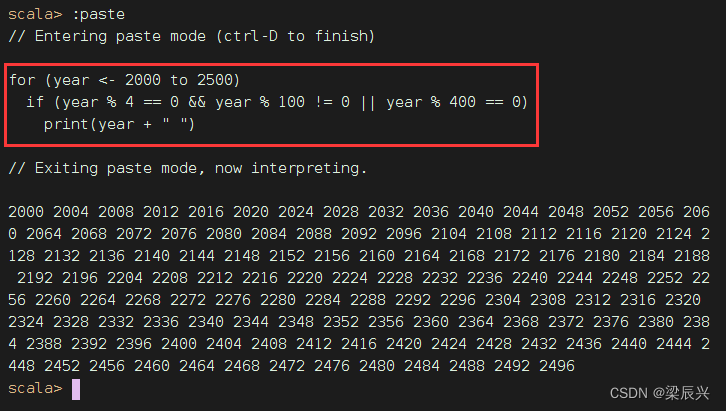
要求每行输出10个数
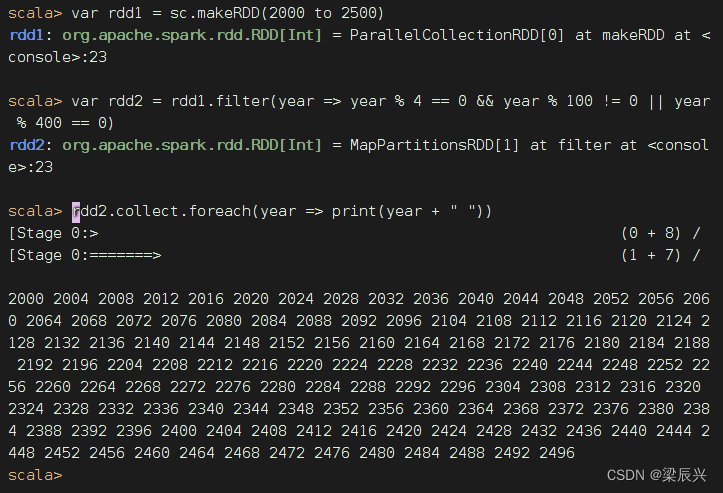
采用过滤算子来实现
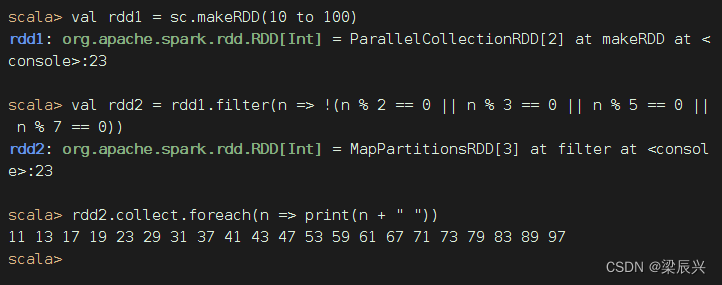
任务2、利用过滤算子输出[10, 100]之间的全部素数
过滤算子:filter(n => !(n % 2 == 0 || n % 3 == 0 || n % 5 == 0 || n % 7 == 0))
(三)扁平映射算子 - flatMap()
1、扁平映射算子功能
flatMap()算子与map()算子类似,但是每个传入给函数func的RDD元素会返回0到多个元素,最终会将返回的所有元素合并到一个RDD。
2、扁平映射算子案例
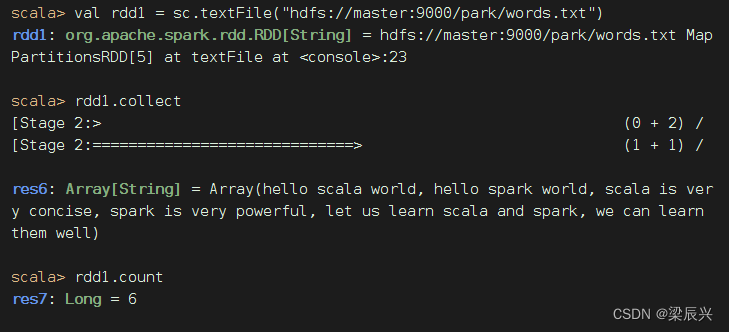
任务1、统计文件中单词个数
读取文件,生成RDD - rdd1,查看其内容和元素个数
对于rdd1按空格拆分,做映射,生成新RDD - rdd2
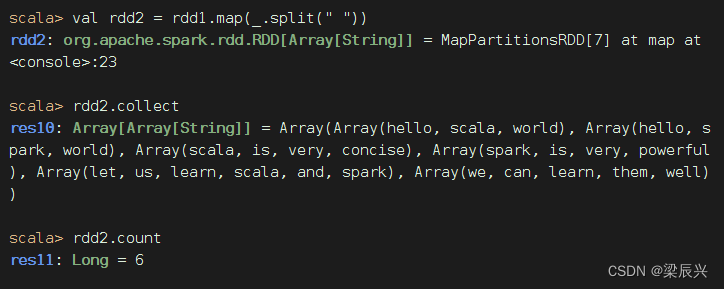
对于rdd1按空格拆分,做扁平映射,生成新RDD - rdd3,有一个降维处理的效果
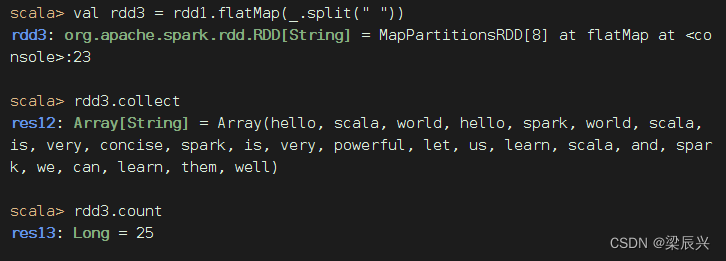
统计结果:文件里有25个单词
任务2、统计不规则二维列表元素个数
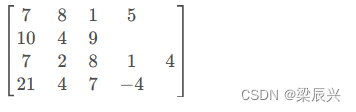
方法一、利用Scala来实现
利用列表的flatten函数
在net.army.rdd.day01包里创建Example02单例对象
package net.army.rdd.day01
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:利用Scala统计不规则二维列表元素个数
*/
object Example02 {
def main(args: Array[String]): Unit = {
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
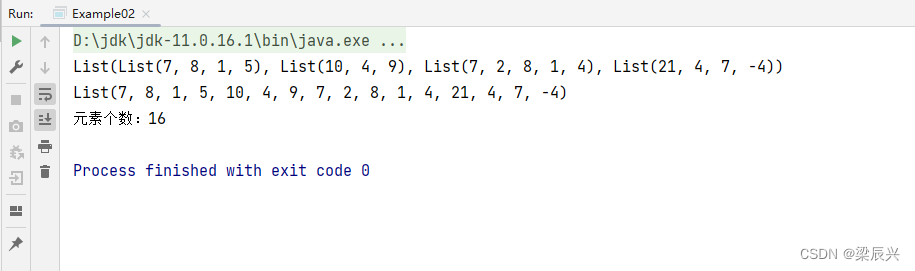
// 输出二维列表
println(mat)
// 将二维列表扁平化为一维列表
val arr = mat.flatten
// 输出一维列表
println(arr)
// 输出元素个数
println("元素个数:" + arr.size)
}
}
运行程序,查看结果
方法二、利用Spark RDD来实现
利用flatMap算子
在net.army.rdd.day01包里创建Example03单例对象
package net.army.rdd.day01
import org.apache.spark.{
SparkConf, SparkContext}
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:利用RDD统计不规则二维列表元素个数
*/
object Example03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建不规则二维列表
val mat = List(
List(7, 8, 1, 5),
List(10, 4, 9),
List(7, 2, 8, 1, 4),
List(21, 4, 7, -4)
)
// 基于二维列表创建rdd1
val rdd1 = sc.makeRDD(mat)
// 输出rdd1
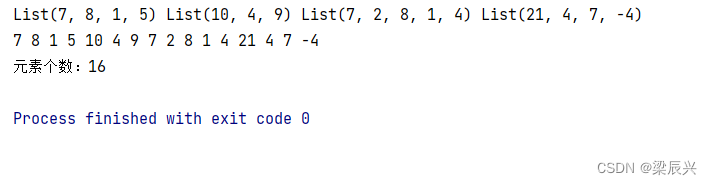
rdd1.collect.foreach(x => print(x + " "))
println()
// 进行扁平化映射
val rdd2 = rdd1.flatMap(x => x.toString.substring(5, x.toString.length - 1).split(", "))
// 输出rdd2
rdd2.collect.foreach(x => print(x + " "))
println()
// 输出元素个数
println("元素个数:" + rdd2.count)
}
}
运行程序,查看结果

扁平化映射可以简化

(四)按键归约算子 - reduceByKey()
1、按键归约算子功能
reduceByKey()算子的作用对像是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将相同key的元素聚集到一起,最终把所有相同key的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
2、按键归约算子案例
任务1、在Spark Shell里计算学生总分
成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 78 | 90 | 76 |
| 李四 | 95 | 88 | 98 |
| 王五 | 78 | 80 | 60 |
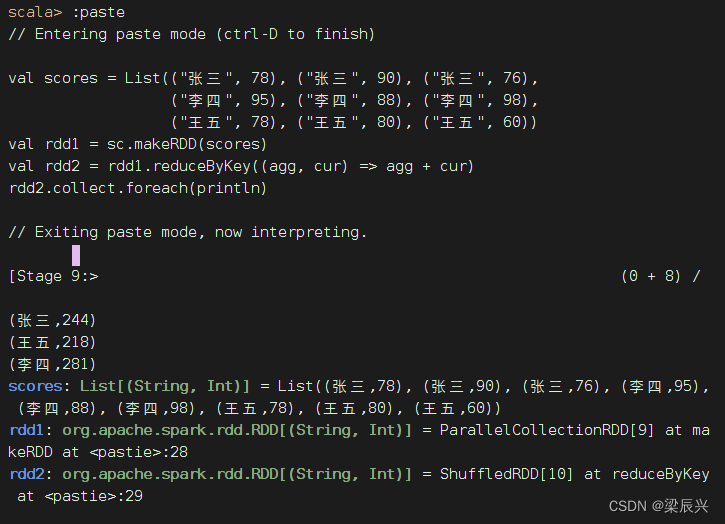
创建成绩列表scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
agg: aggregation 聚合值
cur: current 当前值
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
rdd2.collect.foreach(println)
可以采用占位符
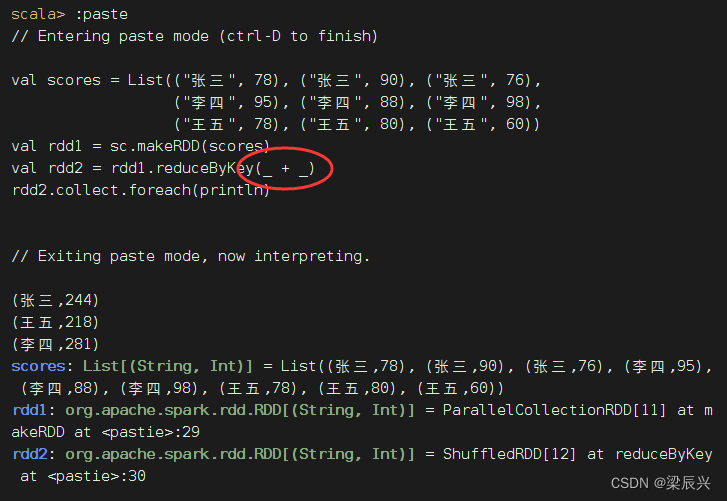
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
rdd2.collect.foreach(println)
任务2、在IDEA里计算学生总分
成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 78 | 90 | 76 |
| 李四 | 95 | 88 | 98 |
| 王五 | 78 | 80 | 60 |
第一种方式:读取二元组成绩列表
在net.army.rdd包里创建day02包,再在day02包下创建CalculateScoreSum01单例对象
package net.army.rdd.day02
import org.apache.spark.{
SparkConf, SparkContext}
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:计算总分
*/
object CalculateScoreSum01 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建二元组成绩列表
val scores = List(
("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
运行程序,查看结果

第二种方式:读取四元组成绩列表
在net.army.rdd.day02包里创建CalculateScoreSum02单例对象
package net.army.rdd.day02
import org.apache.spark.{
SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:计算总分
*/
object CalculateScoreSum02 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 创建四元组成绩列表
val scores = List(
("张三", 78, 90, 76),
("李四", 95, 88, 98),
("王五", 78, 80, 60)
)
// 将四元组成绩列表转化成二元组成绩列表
val newScores = new ListBuffer[(String, Int)]()
// 通过遍历算子遍历四元组成绩列表
scores.foreach(score => {
newScores.append(Tuple2(score._1, score._2))
newScores.append(Tuple2(score._1, score._3))
newScores.append(Tuple2(score._1, score._4))}
)
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(newScores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
可以采用循环结构将四元组成绩列表转化成二元组成绩列表
for (score <- scores) {
newScores.append(Tuple2(score._1, score._2))
newScores.append(Tuple2(score._1, score._3))
newScores.append(Tuple2(score._1, score._4))
}
运行程序,查看结果

第三种情况:读取HDFS上的成绩文件
在master虚拟机的/home目录里创建成绩文件 - scores.txt
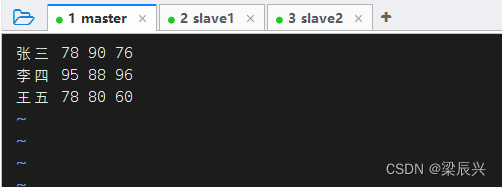
添加内容如下:
张三 78 90 76
李四 95 88 96
王五 78 80 60
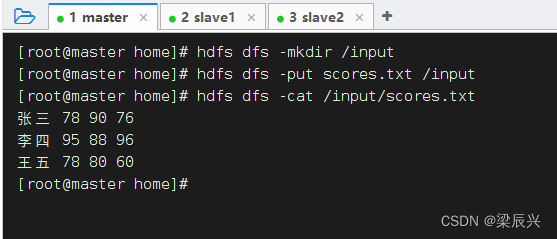
将成绩文件上传到HDFS的/input目录
在net.army.rdd.day02包里创建CalculateScoreSum03单例对象
package net.army.rdd.day02
import org.apache.spark.{
SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
/**
* 作者:梁辰兴
* 日期:2023/6/4
* 功能:计算总分
*/
object CalculateScoreSum03 {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("PrintDiamond") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取成绩文件,生成RDD
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
// 定义二元组成绩列表
val scores = new ListBuffer[(String, Int)]()
// 遍历lines,填充二元组成绩列表
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append(Tuple2(fields(0), fields(1).toInt))
scores.append(Tuple2(fields(0), fields(2).toInt))
scores.append(Tuple2(fields(0), fields(3).toInt))
})
// 基于二元组成绩列表创建RDD
val rdd1 = sc.makeRDD(scores)
// 对成绩RDD进行按键归约处理
val rdd2 = rdd1.reduceByKey(_ + _)
// 输出归约处理结果
rdd2.collect.foreach(println)
}
}
运行程序,查看结果

在Spark Shell里完成同样的任务
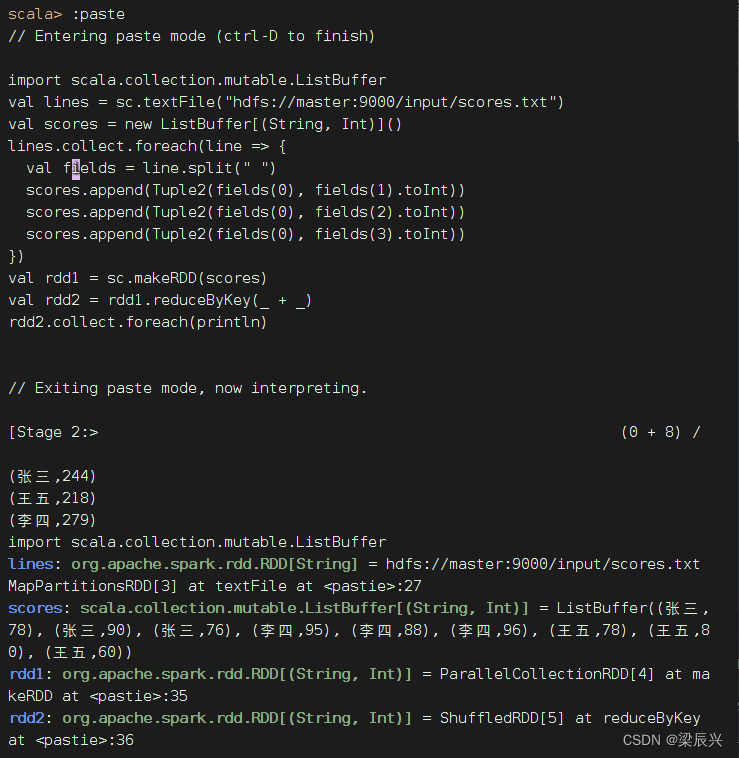
import scala.collection.mutable.ListBuffer
val lines = sc.textFile("hdfs://master:9000/input/scores.txt")
val scores = new ListBuffer[(String, Int)]()
lines.collect.foreach(line => {
val fields = line.split(" ")
scores.append(Tuple2(fields(0), fields(1).toInt))
scores.append(Tuple2(fields(0), fields(2).toInt))
scores.append(Tuple2(fields(0), fields(3).toInt))
})
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
rdd2.collect.foreach(println)
修改程序,将计算结果写入HDFS文件
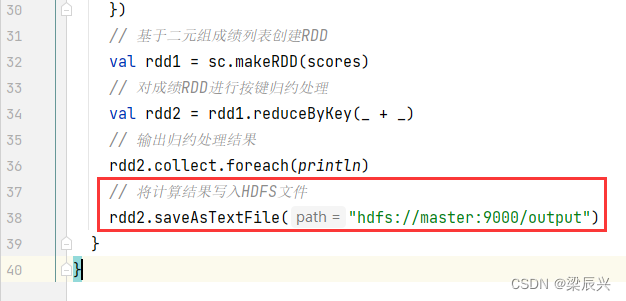
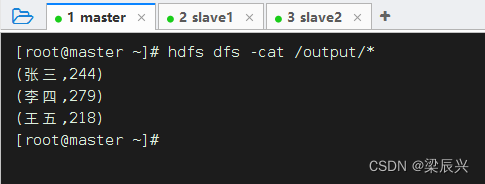
运行程序,查看结果

查看HDFS上生成的结果文件
思考题:计算每个人的平均分(双精度)
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
val rdd3 = rdd2.map(score => (score._1, score._2 / 3.0))
rdd3.collect.foreach(println)
显示姓名、总分和平均分
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
val rdd3 = rdd2.map(score => (score._1, score._2, score._2 / 3.0))
rdd3.collect.foreach(println)
平均分保留两位小数,怎么实现?
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98),
("王五", 78), ("王五", 80), ("王五", 60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey(_ + _)
val rdd3 = rdd2.map(score => (score._1, score._2, (score._2 / 3.0).formatted("%.2f")))
rdd3.collect.foreach(println)
(五)合并算子 - union()
1、合并算子功能
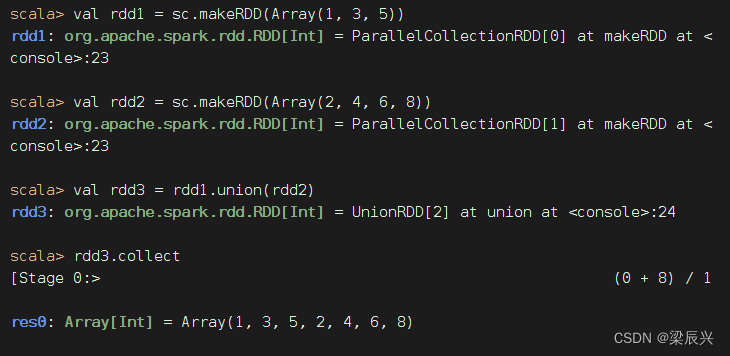
union()算子将两个RDD合并为一个新的RDD,主要用于对不同的数据来源进行合并,两个RDD中的数据类型要保持一致。
2、合并算子案例
创建两个RDD,合并成一个新RDD
练习:将两个二元组成绩表合并
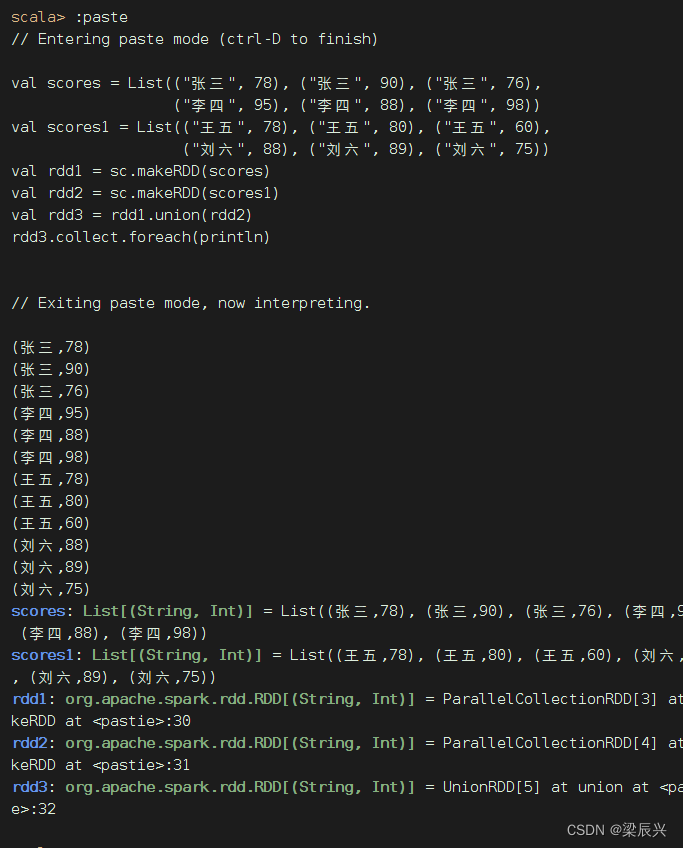
val scores = List(("张三", 78), ("张三", 90), ("张三", 76),
("李四", 95), ("李四", 88), ("李四", 98))
val scores1 = List(("王五", 78), ("王五", 80), ("王五", 60),
("刘六", 88), ("刘六", 89), ("刘六", 75))
val rdd1 = sc.makeRDD(scores)
val rdd2 = sc.makeRDD(scores1)
val rdd3 = rdd1.union(rdd2)
rdd3.collect.foreach(println)
在集合运算里,并集符号: ∪,并集运算: A ∪ B
在集合运算里,交集符号: ∩,交集运算: A ∩ B
在集合运算里,补集运算: A
(六)排序算子 - sortBy()
1、排序算子功能
sortBy()算子将RDD中的元素按照某个规则进行排序。该算子的第一个参数为排序函数,第二个参数是一个布尔值,指定升序(默认)或降序。若需要降序排列,则需将第二个参数置为false。
2、排序算子案例
一个数组中存放了三个元组,将该数组转为RDD集合,然后对该RDD按照每个元素中的第二个值进行降序排列。
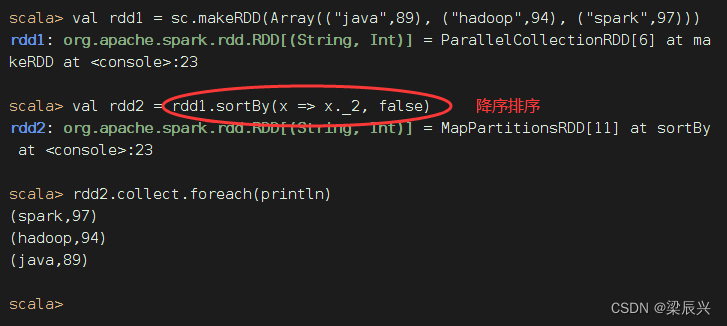
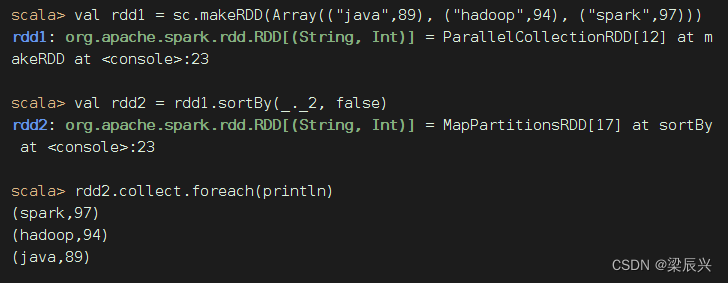
sortBy(x=>x._2,false)中的x代表rdd1中的每个元素。由于rdd1的每个元素是一个元组,因此使用x._2取得每个元素的第二个值。当然,sortBy(x=>x._2,false)也可以直接简化为sortBy(_._2,false)。
(七)按键排序算子 - sortByKey()
1、按键排序算子功能
sortByKey()算子将(key, value)形式的RDD按照key进行排序。默认升序,若需降序排列,则可以传入参数false。
2、按键排序算子案例
将三个二元组构成的RDD按键先降序排列,然后升序排列
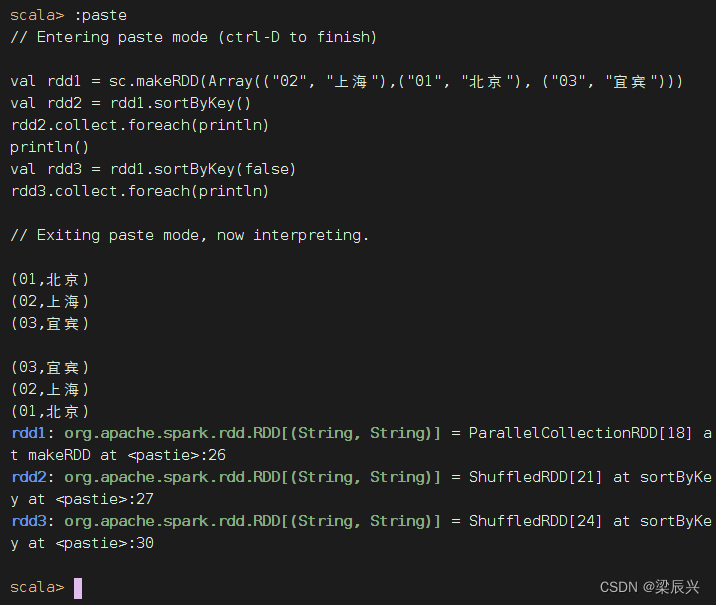
val rdd1 = sc.makeRDD(Array(("02", "上海"),("01", "北京"), ("03", "宜宾")))
val rdd2 = rdd1.sortByKey()
rdd2.collect.foreach(println)
println()
val rdd3 = rdd1.sortByKey(false)
rdd3.collect.foreach(println)
其实,用排序算子也是可以搞定的
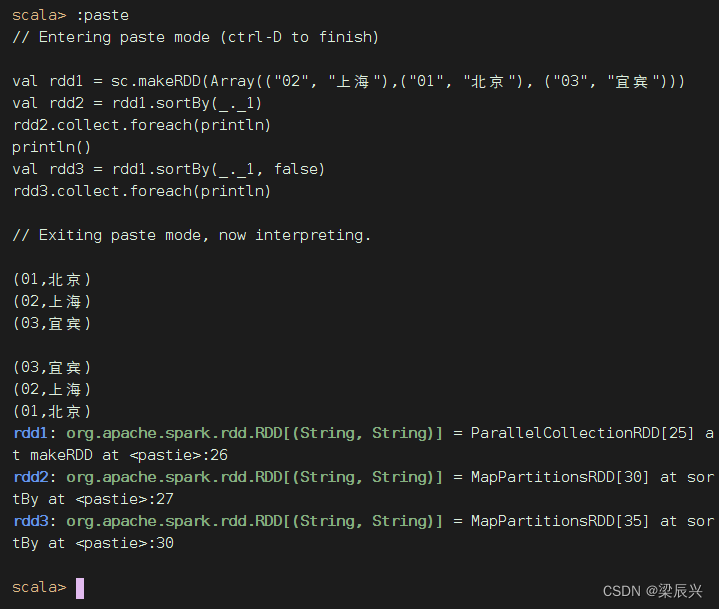
val rdd1 = sc.makeRDD(Array(("02", "上海"),("01", "北京"), ("03", "宜宾")))
val rdd2 = rdd1.sortBy(_._1)
rdd2.collect.foreach(println)
println()
val rdd3 = rdd1.sortBy(_._1, false)
rdd3.collect.foreach(println)
排序算子比按键排序算子更灵活强大
(八)连接算子
1、内连接算子 - join()
(1)内连接算子功能
join()算子将两个(key, value)形式的RDD根据key进行连接操作,相当于数据库的内连接(Inner Join),只返回两个RDD都匹配的内容。
(2)内连接算子案例
将rdd1与rdd2进行内连接
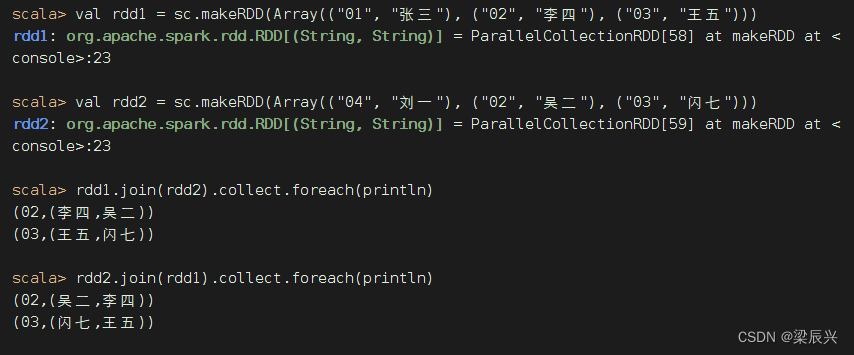
val rdd1 = sc.makeRDD(Array(("01", "张三"), ("02", "李四"), ("03", "王五")))
val rdd2 = sc.makeRDD(Array(("04", "刘一"), ("02", "吴二"), ("03", "闪七")))
val rdd2 = sc.makeRDD(Array(("04", "刘一"), ("02", "吴二"), ("03", "闪七")))
rdd2.join(rdd1).collect.foreach(println)
2、左外连接算子 - leftOuterJoin()
(1)左外连接算子功能
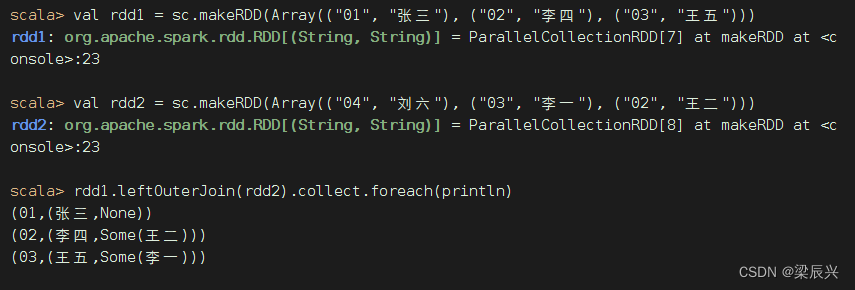
leftOuterJoin()算子与数据库的左外连接类似,以左边的RDD为基准(例如rdd1.leftOuterJoin(rdd2),以rdd1为基准),左边RDD的记录一定会存在。例如,rdd1的元素以(k,v)表示,rdd2的元素以(k, w)表示,进行左外连接时将以rdd1为基准,rdd2中的k与rdd1的k相同的元素将连接到一起,生成的结果形式为(k, (v, Some(w))。rdd1中其余的元素仍然是结果的一部分,元素形式为(k,(v, None)。Some和None都属于Option类型,Option类型用于表示一个值是可选的(有值或无值)。若确定有值,则使用Some(值)表示该值;若确定无值,则使用None表示该值。
(2)左外连接算子案例
rdd1与rdd2进行左外连接
3、右外连接算子 - rightOuterJoin()
(1)右外连接算子功能
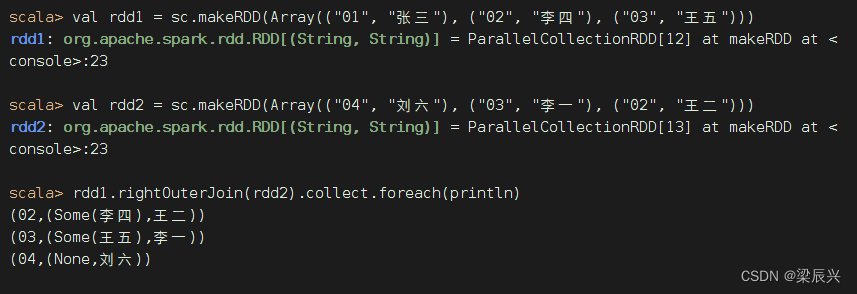
rightOuterJoin()算子的使用方法与leftOuterJoin()算子相反,其与数据库的右外连接类似,以右边的RDD为基准(例如rdd1.rightOuterJoin(rdd2),以rdd2为基准),右边RDD的记录一定会存在。
(2)右外连接算子案例
rdd1与rdd2进行右外连接
4、全外连接算子 - fullOuterJoin()
(1)全外连接算子功能
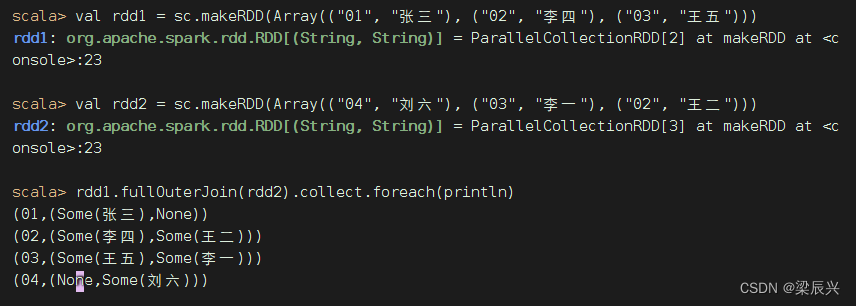
fullOuterJoin()算子与数据库的全外连接类似,相当于对两个RDD取并集,两个RDD的记录都会存在。值不存在的取None。
(2)全外连接算子案例
rdd1与rdd2进行全外连接
(九)交集算子 - intersection()
1、交集算子功能
intersection()算子对两个RDD进行交集操作,返回一个新的RDD。要求两个算子类型要一致。
2、交集算子案例
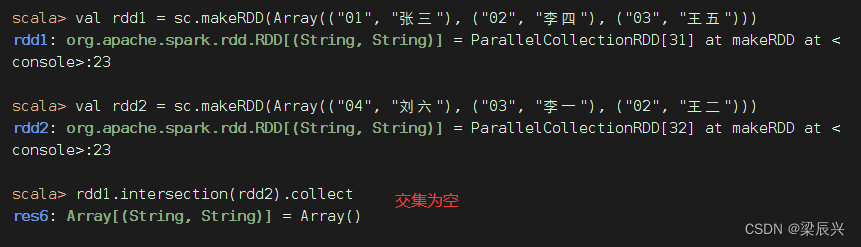
rdd1与rdd2进行交集操作,满足交换律
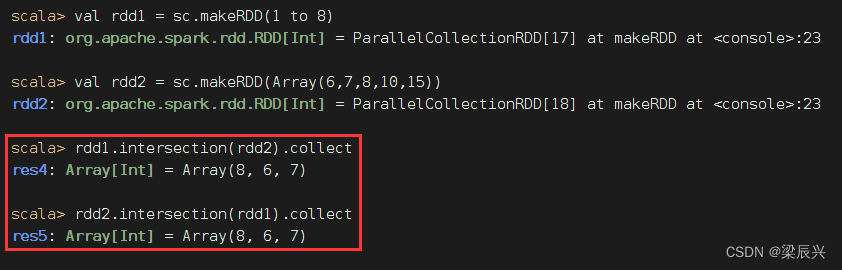
A∩B ≠ \neq =ϕ
(十)去重算子 - distinct()
1、去重算子功能
distinct()算子对RDD中的数据进行去重操作,返回一个新的RDD。有点类似与集合的不允许重复元素。
2、去重算子案例
去掉rdd中重复的元素

3、IP地址去重案例
在项目根目录创建ips.txt文件
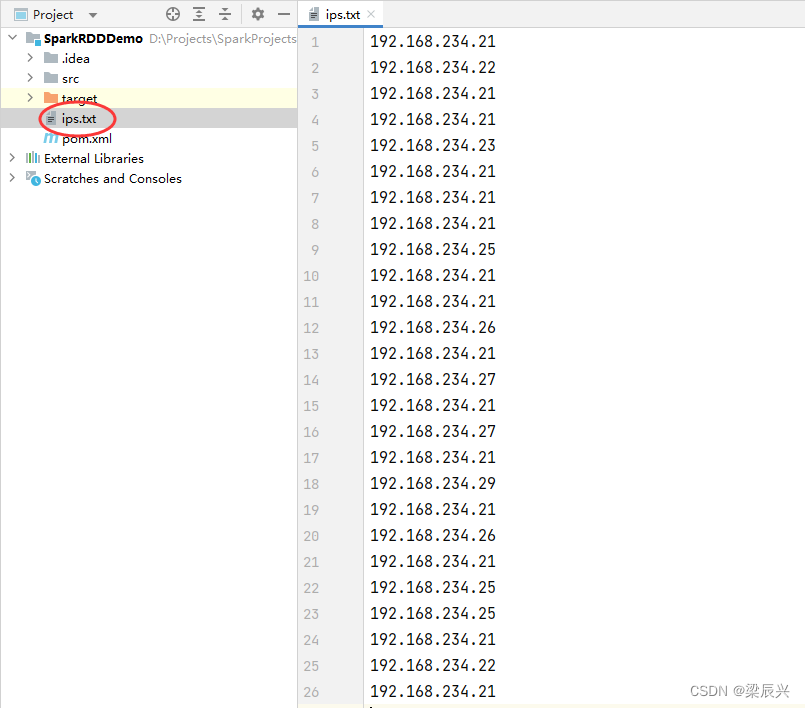
192.168.234.21
192.168.234.22
192.168.234.21
192.168.234.21
192.168.234.23
192.168.234.21
192.168.234.21
192.168.234.21
192.168.234.25
192.168.234.21
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.29
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.25
192.168.234.25
192.168.234.21
192.168.234.22
192.168.234.21
在net.army.rdd.day03包里创建DistinctIPs单例对象
package net.army.rdd.day03
import org.apache.spark.{
SparkConf, SparkContext}
/**
* 作者:梁辰兴
* 日期:2023/6/5
* 功能:IP地址去重
*/
object DistinctIPs {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setAppName("DistinctIPs ") // 设置应用名称
.setMaster("local[*]") // 设置主节点位置(本地调试)
// 基于Spark配置对象创建Spark容器
val sc = new SparkContext(conf)
// 读取本地IP地址文件,得到RDD
val ips = sc.textFile("file:///Projects/SparkProjects/SparkRDDDemo/ips.txt")
// rdd去重再输出
ips.distinct.collect.foreach(println)
}
}
运行程序,查看结果
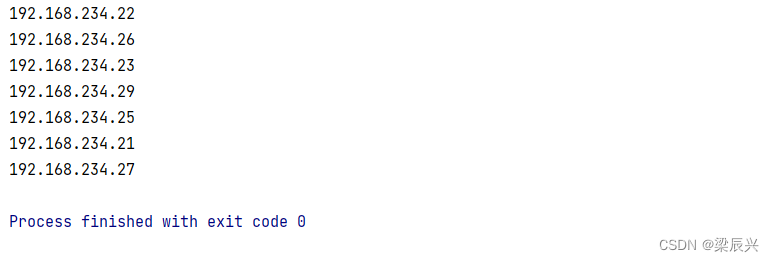
修改代码,保存去重结果到本地目录
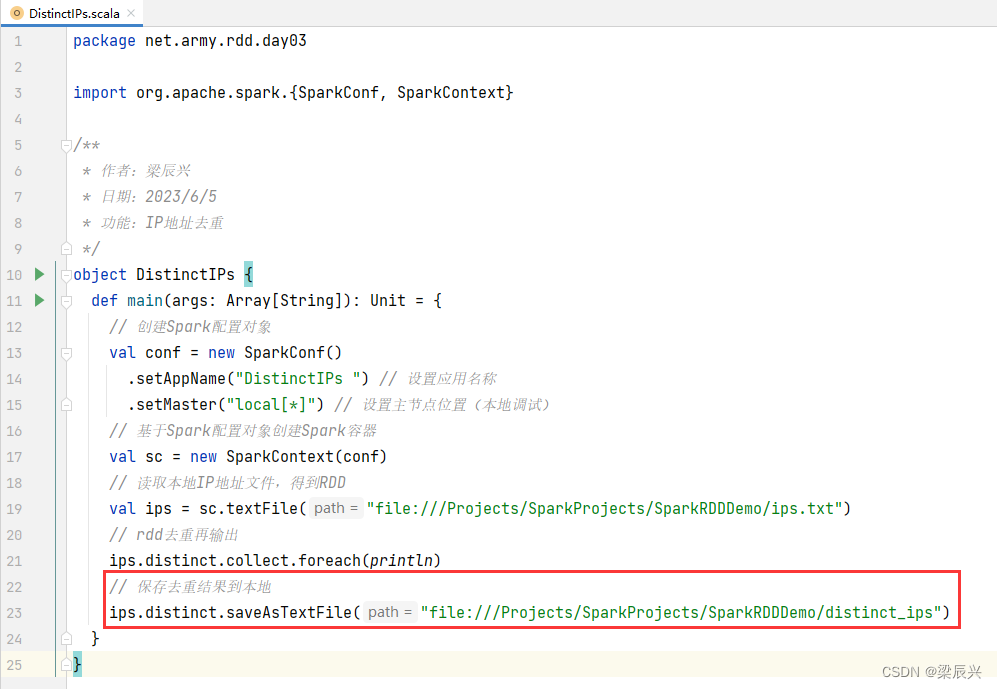
运行程序,查看结果文件
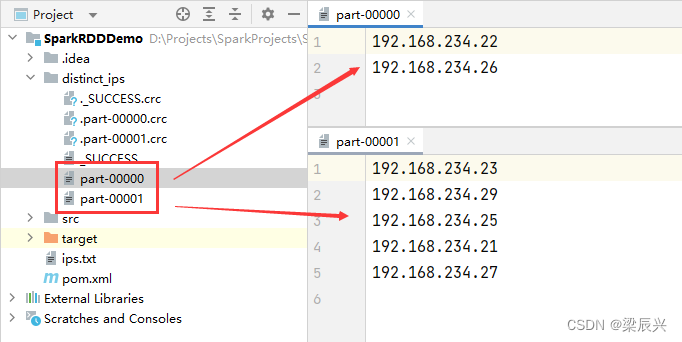
对比一下之前我们用纯粹的Scala来处理的代码
很明显,RDD解决去重问题代码更为简洁。
(十一)组合分组算子 - cogroup()
1、组合分组算子功能
cogroup()算子对两个(key, value)形式的RDD根据key进行组合,相当于根据key进行并集操作。例如,rdd1的元素以(k, v)表示,rdd2的元素以(k, w)表示,执行rdd1.cogroup(rdd2)生成的结果形式为(k, (Iterable, Iterable))。
2、组合分组算子案例
rdd1与rdd2进行组合分组操作

三、掌握行动算子
Spark中的转化算子并不会马上进行运算,而是在遇到行动算子时才会执行相应的语句,触发Spark的任务调度。
| 行动算子 | 功能说明 |
|---|---|
| reduce(func) | 将RDD中的元素进行聚合计算,func为传入的聚合函数 |
| collect() | 向Driver以数组形式返回数据集的所有元素。通常对于过滤操作或其他返回足够小的数据子集的操作非常有用 |
| count() | 返回数据集中元素的数量 |
| countByKey() | 统计RDD 中key相同的元素的数量,仅元素类型为键值对(key, value)的RDD可用,返回的结果类型为Map |
| foreach(func) | 对RDD中的每一个元素运行给定的函数func |
| first() | 返回数据集中第一个元素 |
| take(n) | 返回包含数据集前n个元素组成的数组 |
| takeOrdered(n, [ordering]) | 返回RDD中的前n个元素,并以自然顺序或自定义的比较器顺序进行排序 |
| saveAsTextFile(path) | 将数据集中的元素持久化为一个或一组文本文件,并将文件存储在本地文件系统、HDFS或其他Hadoop支持的文件系统的指定目录中。Spark 会对每个元素调用toString()方法,将每个元素转化为文本文件中的一行。 |
| saveAsSequenceFile(path) | 将数据集中的元素持久化为一个 Hadoop SequenceFile文件,并将文件存储在木地文件系统、HDFS 或其他Hadoop支持的文件系统的指定目录中。实现了Hadoop Writable接口的键值对形式的RDD可以使用该操作。 |
| saveAsObjectFile(path) | 将数据集中的元素序列化成对象,存储到文件中。然后可以使用SparkContext.objectFile()对该文件进行加载。 |
(一)归约算子 - reduce()
1、归约算子功能
reduce()算子按照传入的函数进行归约计算
2、归约算子案例
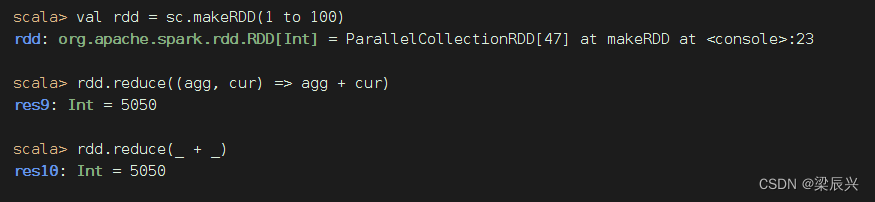
计算 1 + 2 + 3 + … … + 100 1 + 2 + 3 + …… + 100 1+2+3+……+100的值
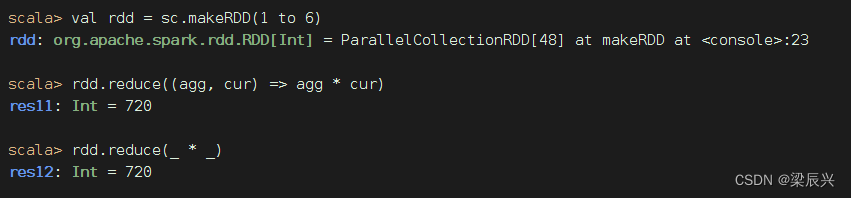
 计算 1 × 2 × 3 × 4 × 5 × 6 1 \times 2 \times 3 \times 4 \times 5 \times 6 1×2×3×4×5×6的值(阶乘 - 累乘)
计算 1 × 2 × 3 × 4 × 5 × 6 1 \times 2 \times 3 \times 4 \times 5 \times 6 1×2×3×4×5×6的值(阶乘 - 累乘)
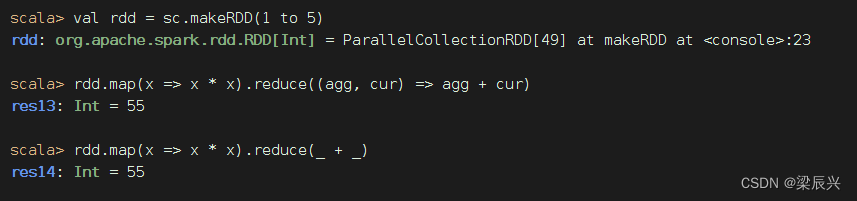
计算 1 2 + 2 2 + 3 2 + 4 2 + 5 2 1^2 + 2^2 + 3^2 + 4^2 + 5^2 12+22+32+42+52的值(先映射,后归约)
高中时的等差数列求和问题,只需map()和reduce()算子就可以通通搞定。
(二)采集算子 - collect()
1、采集算子功能
collect()算子向Driver以数组形式返回数据集的所有元素。通常对于过滤操作或其他返回足够小的数据子集的操作非常有用。
2、采集算子案例
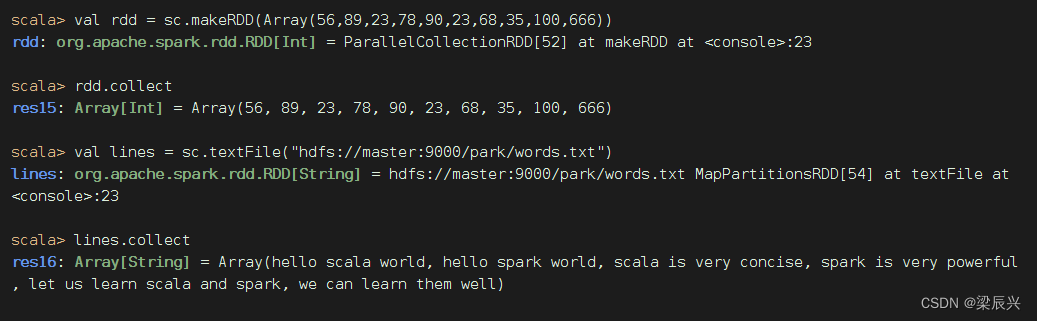
显示RDD的全部元素
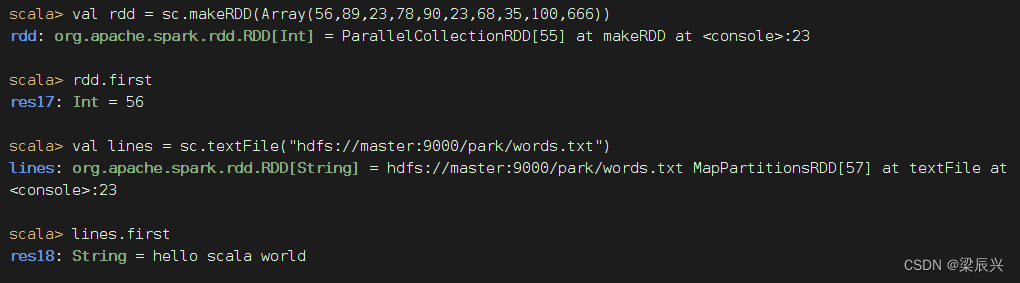
(三)首元素算子 - first()
1、首元素算子功能
first()算子返回数据集中第一个元素
2、首元素算子案例
显示RDD的首元素
(四)计数算子 - count()
1、计数算子功能
count()算子统计RDD的元素个数
2、计数算子案例
统计RDD的元素个数
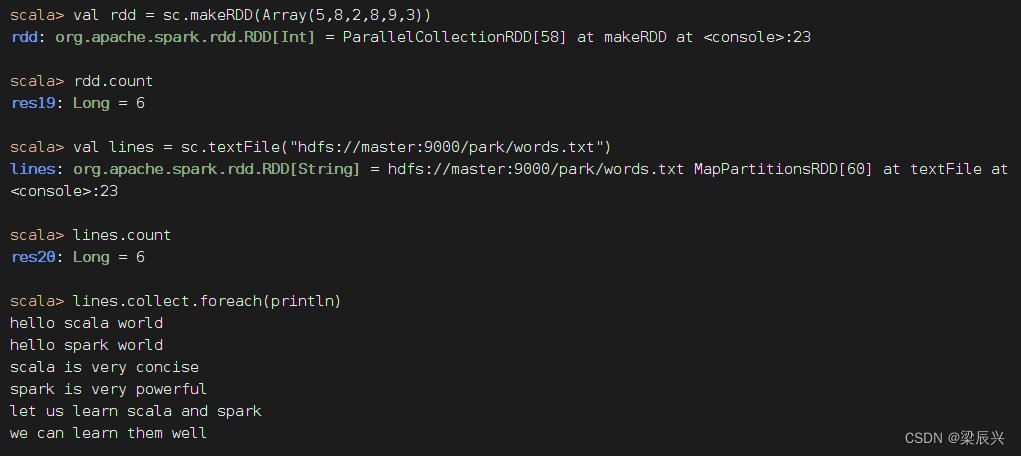 如果要统计单词个数,那就要采用扁平映射算子
如果要统计单词个数,那就要采用扁平映射算子
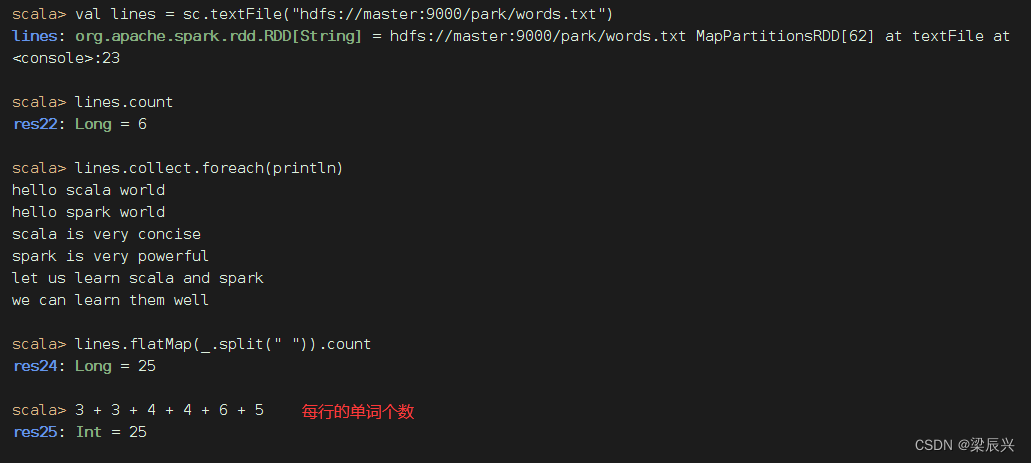 单词文件words.txt ——6行25个单词
单词文件words.txt ——6行25个单词
(五)按键计数算子 - countByKey()
1、按键计数算子功能
countByKey()算子按键统计RDD键值出现的次数,返回由键值和次数构成的映射。
2、按键计数算子案例
List集合中存储的是键值对形式的元组,使用该List集合创建一个RDD,然后对其进行countByKey的计算。
 注意:元素必须是键值对的二元组,不能是三元组
注意:元素必须是键值对的二元组,不能是三元组

(六)前截取算子 - take(n)
1、前截取算子功能
take(n)算子返回RDD的前n个元素(同时尝试访问最少的partitions),返回结果是无序的,测试使用。
2、前截取算子案例
返回集合中前任意多个元素组成的数组
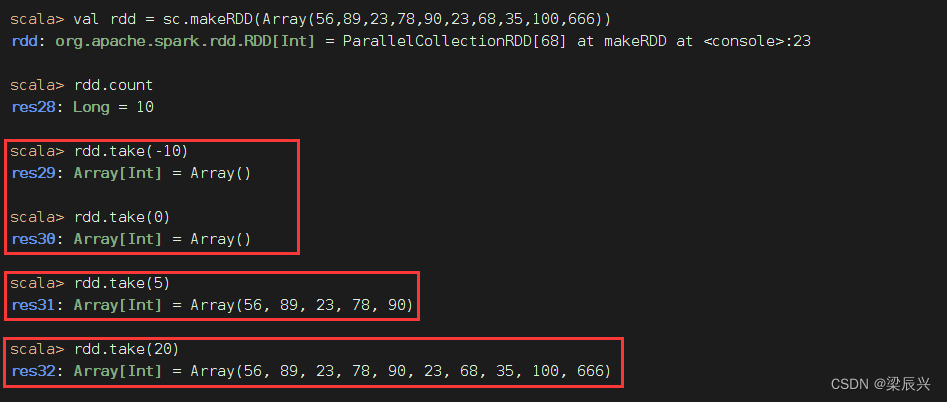
三种情况:返回空集、真子集、全集
(七)排序前截取算子 - takeOrdered(n)[(ordering)]
1、排序前截取算子功能
takeOrdered(n, [ordering])算子返回RDD中的前n个元素,并以自然顺序或自定义的比较器顺序进行排序
2、排序前截取算子案例
返回RDD前n个元素(升序)
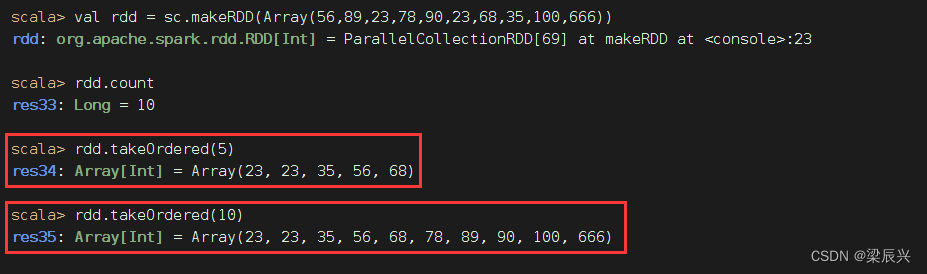
返回前n个元素(降序)
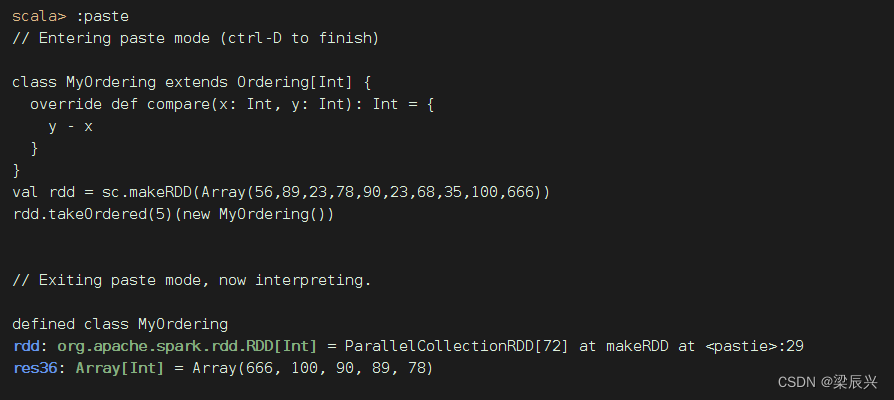
class MyOrdering extends Ordering[Int] {
override def compare(x: Int, y: Int): Int = {
y - x
}
}
val rdd = sc.makeRDD(Array(56,89,23,78,90,23,68,35,100,666))
rdd.takeOrdered(5)(new MyOrdering())
其实,可以top(n)算子来实现同样的效果,更简单

(八)遍历算子 - foreach()
1、遍历算子功能
计算 RDD中的每一个元素,但不返回本地(只是访问一遍数据),可以配合println友好地打印数据。
2、遍历算子案例
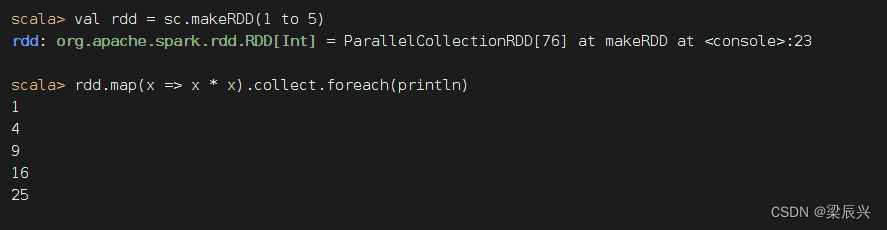
将RDD里的每个元素平方后输出(一定要采集,才能遍历)
将RDD的内容逐行打印输出
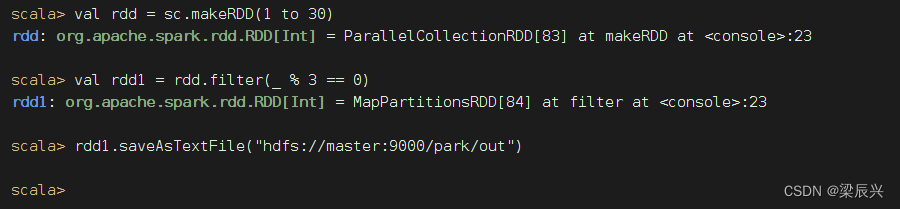
(九)存文件算子 - saveAsFile()
1、存文件算子功能
将RDD数据保存到本地文件或HDFS文件
2、存文件算子案例
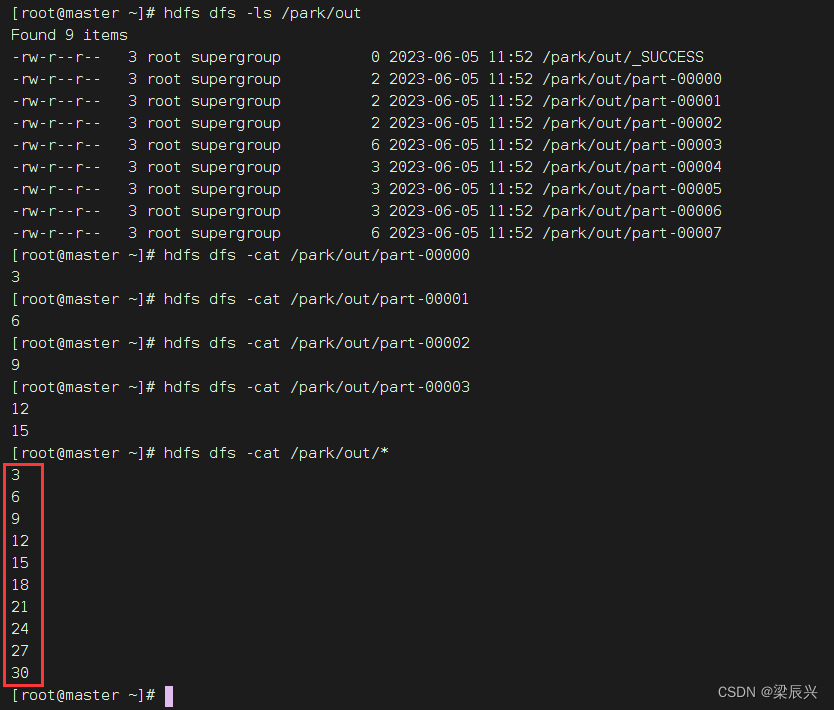
将rdd内容保存到HDFS的/park/out目录
查看另存的结果文件