图解版:
一.map阶段
二.reduce阶段
文解版:
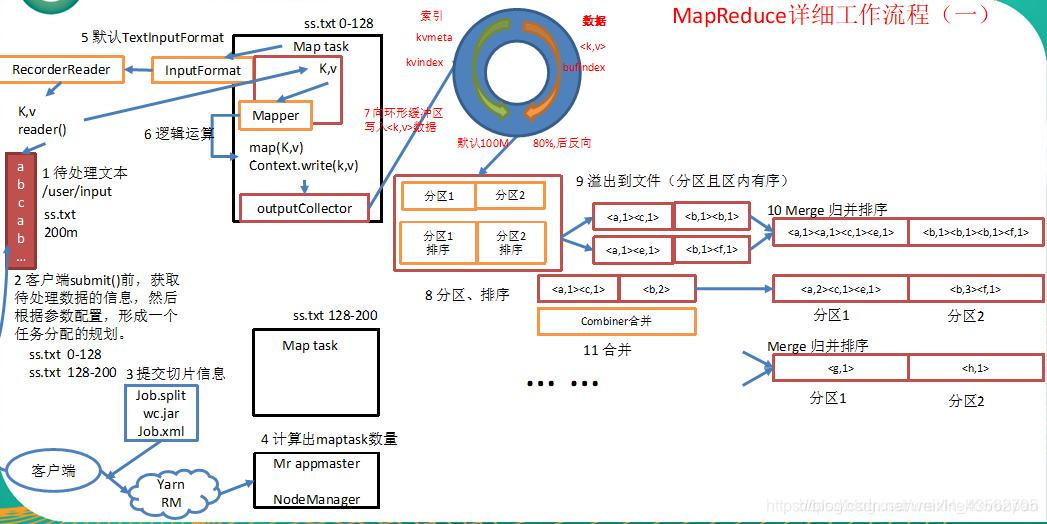
1.首先我们有一个待处理的文本ss.txt,大小为200m,假设要对这个文本中的内容进行单词统计。
2.在我们客户端提交之前,获取到待处理文本相关信息,根据block块的大小划分出具体的切片信息(默认集群中的块大小是128m,所以这里将我们的待处理文本ss.txt划分为两个切片分别为0-128m和128-200m)。
3.客户端将切片信息和jar包提交到yarn集群ResourceManager上。
4.ResourceManager将根据切片的个数决定开启多少个MapTask(一个MapTask处理一个切片)。
5.MapTask通过InputFormat(默认使用它的实现类TextInputFormat:将偏移量作为key,将一行数据作为value)来解析key/value对。将key/value对解析到map方法中。
6.在map方法中进行相应的逻辑处理,然后通过outputCollector写出到环形缓冲区。
7.当环形缓冲区数据达到80%以后,将会对数据进行分区、排序处理,然后溢出到文件。
8.可能会有多次溢出,将多次溢出的文件进行归并排序(可以使用Combiner来进行数据的汇总操作,来优化MapReduce减少IO流的传输)。形成一个大的有序文件。为下一阶段的reduce阶段拷贝数据做准备。
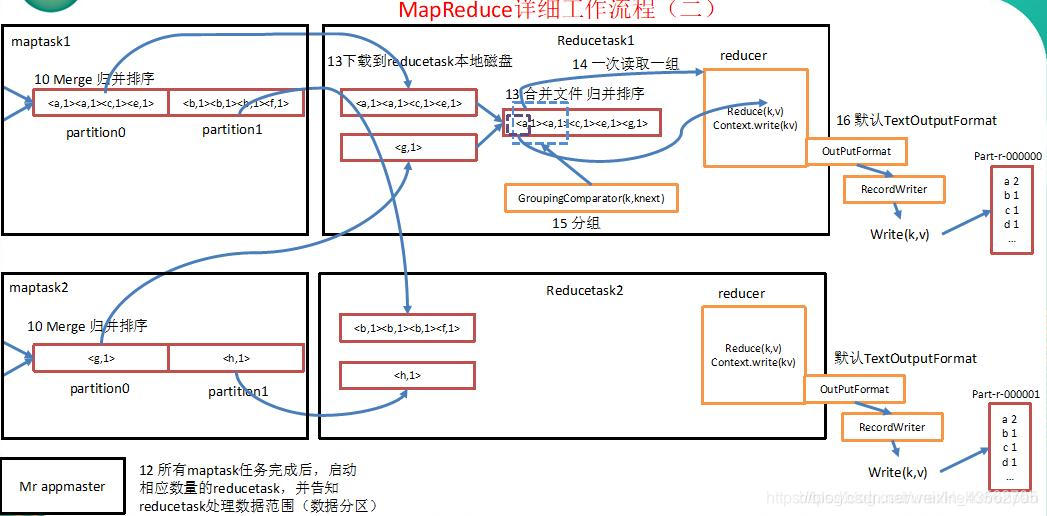
9.在reduce阶段,根据map阶段的分区个数,启动相应数量的ReduceTask。
10.将map处理后溢出到磁盘的结果从远程拷贝到ReduceTask本地磁盘(实际是内存中,内存不足时才溢写到磁盘)。
11.将多个MapTask中文件的相同分区(例如:MapTask1中的一号分区和MapTask2中的一号分区)的数据进行一次合并进行归并排序,合并为一个文件。
12.然后送入到reducer方法中。reduce方法进行相应的处理,然后进行写出到文件中(当然也可以自定义OutputFormat,按照自定义的格式写入到自定义的路径当中)。
注意:我特意仔细说明一哈shuffle的具体过程
1)maptask收集我们的map()方法输出的kv对,放到内存缓冲区中。
2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件。
3)多个溢出文件会被合并成大的溢出文件。
4)在溢出过程中,及合并的过程中,都要调用partitioner进行分区和针对key进行排序。
5)reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据。
6)reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)。
7)合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)。