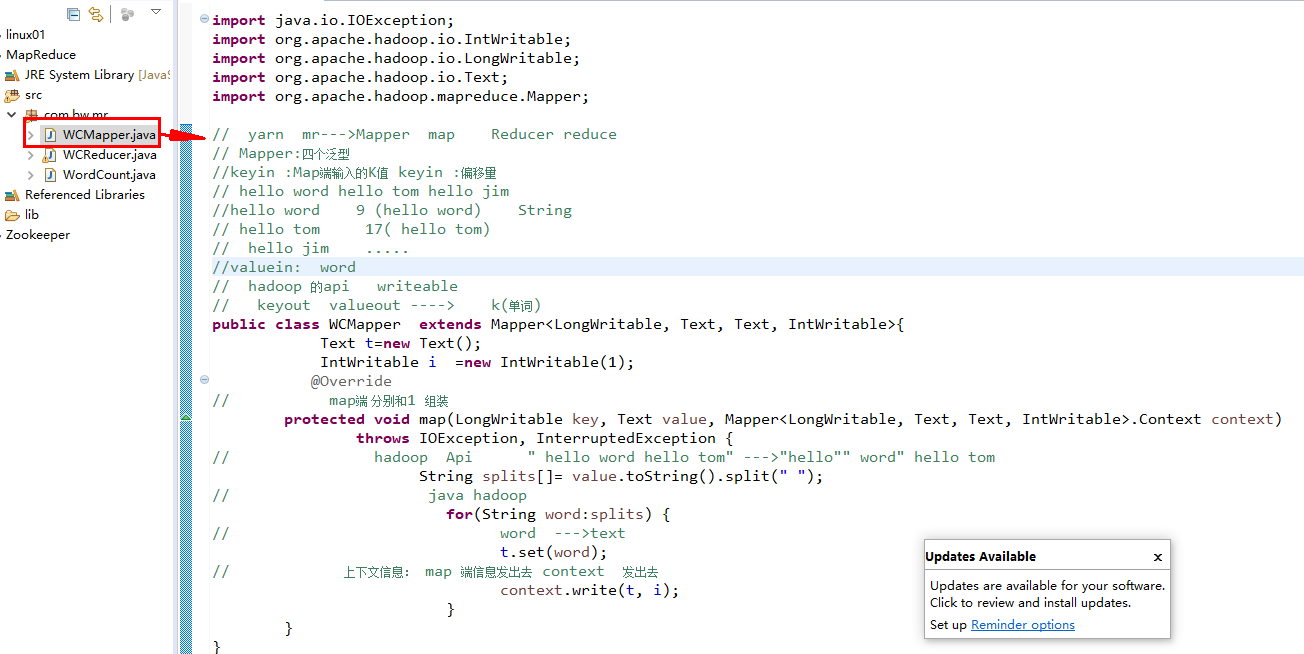

package com.bw.mr;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// yarn mr--->Mapper map Reducer reduce
// Mapper:四个泛型
//keyin :Map端输入的K值 keyin :偏移量
// hello word hello tom hello jim
//hello word 9 (hello word) String
// hello tom 17( hello tom)
// hello jim .....
//valuein: word
// hadoop 的api writeable
// keyout valueout ----> k(单词)
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text t=new Text();
IntWritable i =new IntWritable(1);
@Override
// map端 分别和1 组装
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// hadoop Api " hello word hello tom" --->"hello"" word" hello tom
String splits[]= value.toString().split(" ");
// java hadoop
for(String word:splits) {
// word --->text
t.set(word);
// 上下文信息: map 端信息发出去 context 发出去
context.write(t, i);
}
}
}
package com.bw.mr;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// Mr :input map reduce output
// reducer reduce hello(1,1,1,1,1)-->hello(1+1+1+...)
// map(LongWriteable,text) --->(text,IntWriteable)\
// reduce (text,IntWriteable) ---->(text,IntWriteable)
// hello(1,1,1,1,1)-->
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 重写 reduce 方法
@Override
// text :word Iterable (111111111111111)
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
// reduce --->归并 ---》 word(1,1,1,1,...)---->word(count)
int count =0;
// 循环 。。。for
for(IntWritable i:arg1) {
count++;
}
// 输出最后 的结果
arg2.write(arg0,new IntWritable(count));
}
}
package com.bw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
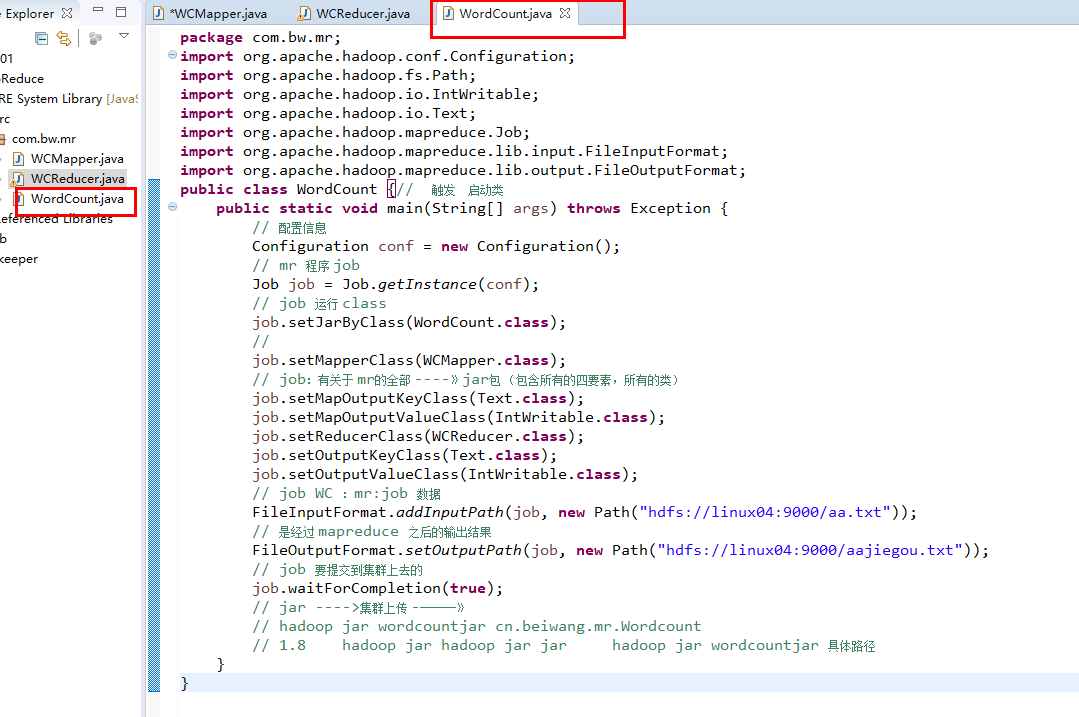
public class WordCount {// 触发 启动类
public static void main(String[] args) throws Exception {
// 配置信息
Configuration conf = new Configuration();
// mr 程序 job
Job job = Job.getInstance(conf);
// job 运行 class
job.setJarByClass(WordCount.class);
//
job.setMapperClass(WCMapper.class);
// job:有关于 mr的全部 ----》jar包 (包含所有的四要素,所有的类)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
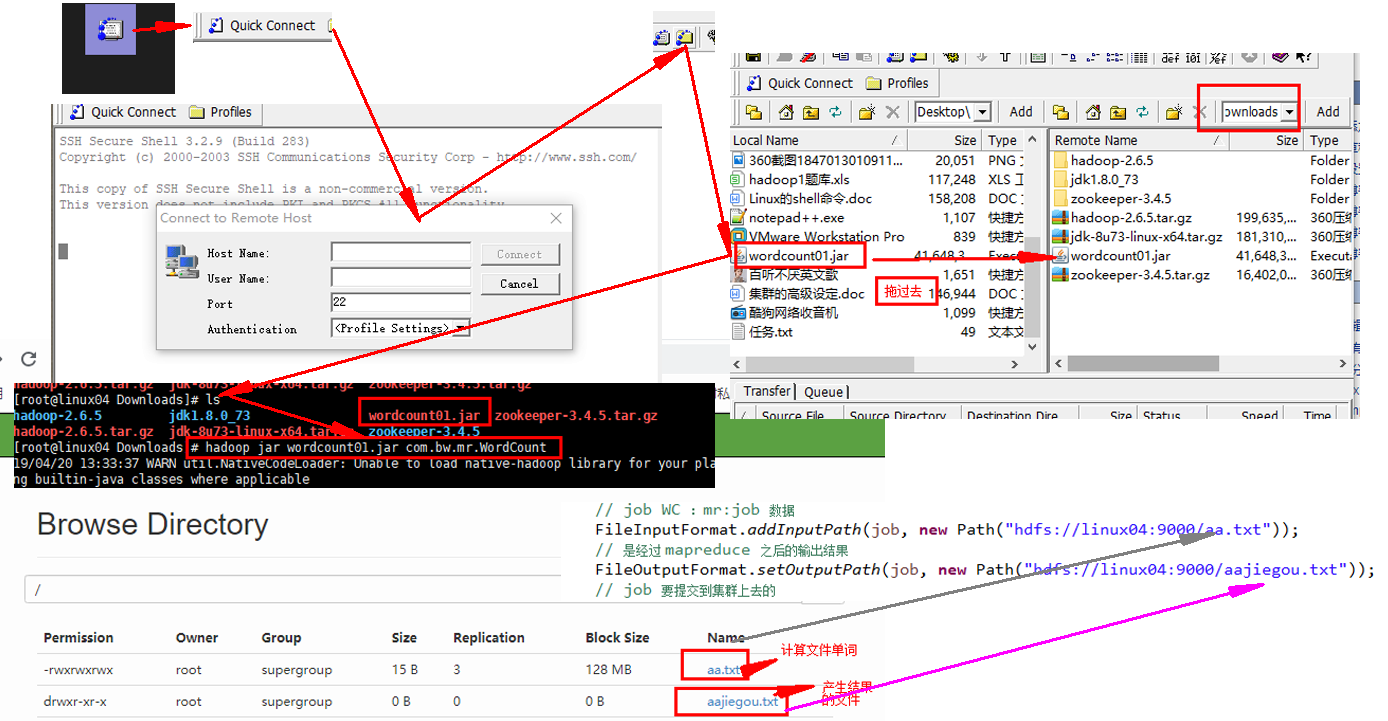
// job WC :mr:job 数据
FileInputFormat.addInputPath(job, new Path("hdfs://linux04:9000/aa.txt"));
// 是经过 mapreduce 之后的输出结果
FileOutputFormat.setOutputPath(job, new Path("hdfs://linux04:9000/aajiegou.txt"));
// job 要提交到集群上去的
job.waitForCompletion(true);
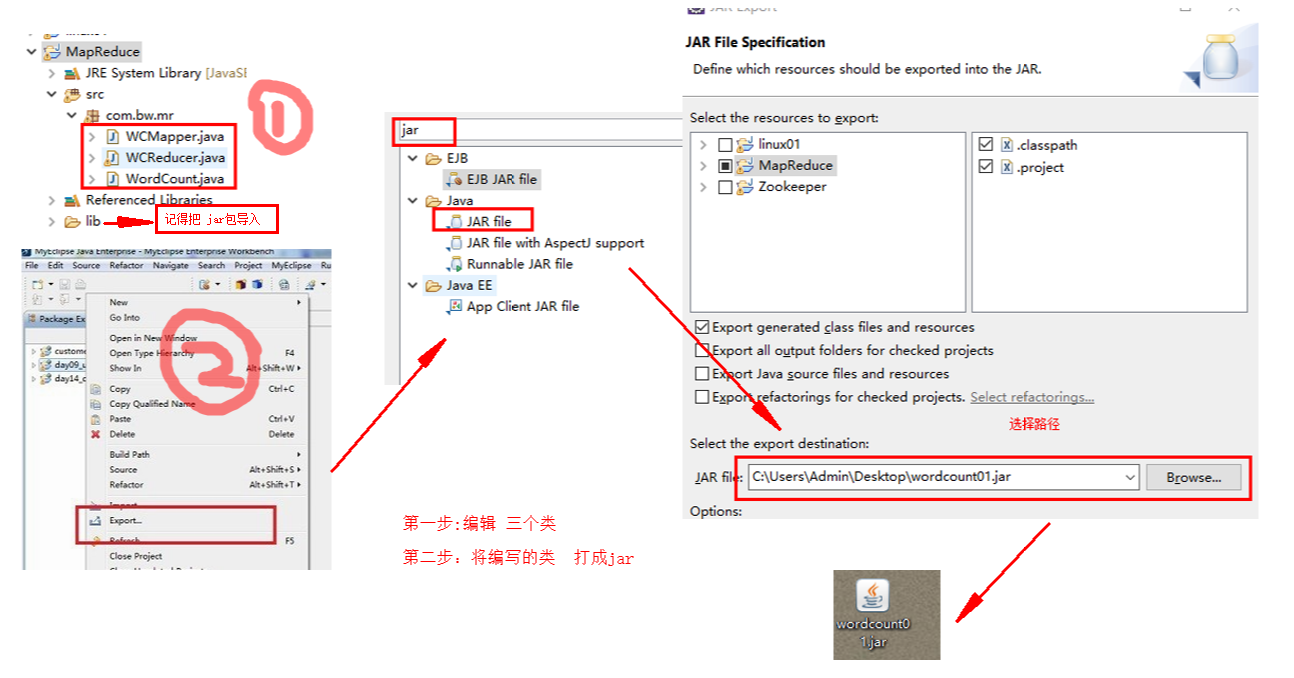
// jar ---->集群上传 -————》
// hadoop jar wordcountjar cn.beiwang.mr.Wordcount
// 1.8 hadoop jar hadoop jar jar hadoop jar wordcountjar 具体路径
}
}