在 Hadoop 中 MapReduce 中, map 和 reduce 函数遵循的常规格式:
map : (k1, v1) -> list(k2, v2)
reduce : (k2, list(v2)) -> (k3, v3)
- Java 接口代码:
// Map
public class Map extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{
@Override
protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException {
}
}
// Reduce
public class Reduce extends Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>{
@Override
protected void reduce(KEYIN key, Iterable<VALUEIN> value, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context)
throws IOException, InterruptedException {
}
}
Context 对象用于输出键值对 :
public void write(KEYOUT key, VALUEOUT value) throws IOException, InterruptedException;
使用 Combiner 的 MapReduce
map : (k1, v1) -> (k2, v2)
combine : (k2, list(v2)) -> list(k2, v2)
reduce : (k2, list(v2)) -> list(k3, v3)
分区处理:
- partition 函数对中间结果的键值对进行处理, 并且返回一个分区索引(partition index)。
- 分区由 键 对单独决定。
> partition : (k2, v2) -> integer
public class Partition extends Partitioner<KEYIN, VALUEIN>{
@Override
public int getPartition(KEYIN key, VALUEIN value, int numPartitions){
return 0;
}
}
MapReduce 的属性设置
Configuration conf = new Configuration();
Job job = new Job();
job.setJarByClass(MRModel.class); // 设置调用作业调用的程序类
FileInputFormat.addInputPath(job, new Path(args[0])); // 设置作业的输入路径跟输入格式
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置作业的输出路径跟格式
job.setMapperClass(Map.class); // 设置 调用的 Map 类
job.setMapOutputKeyClass(Text.class); // 设置 Map 的输出Key 格式
job.setMapOutputValueClass(Text.class); // 设置 Map 的输出 value 格式
job.setCombinerClass(Reduce.class); // 设置调用的 Combiner 类
job.setPartitionerClass(Partition.class); // 设置调用 Partition 的类
job.setReducerClass(Reduce.class); // 设置 调用的 Reduce 类
job.setOutputKeyClass(Text.class); // 设置 输出的 key 格式
job.setOutputValueClass(Text.class); // 设置 输出的 value 格式
- 输入分片与记录
输入分片在 java 中表示为 InputSplit 接口
public abstract class InputSplit{
public abstract long getLength() throws IOException, InterruptedException;
public abstract String[] getLocations() throws IOException, InterruptedException;
}
- 分片不包含数据本身, 而是指向数据的引用。
- 存储位置供 MapReduece 系统使用以便将 map 任务尽量放在分片数据附近
- 存储大小用来排序分片
- MapReduce 应用开发人员不直接处理 InputSplit , 因为它将由 InputFormat 创建。 InputFormat 负责产生输入分片并将他们分割成记录
public abstract class InputFormat<Text, Text>{
public abstract RecordReader<Text, Text> createRecordReader(InputSplit arg0, TaskAttemptContext arg1)throws IOException, InterruptedException;
public abstract List<InputSplit> getSplits(JobContext arg0) throws IOException, InterruptedException;
/*
* - getSplits() 负责计算分片, 然后将他们发送到 jobtracker
* - jobtracker 使用其存储位置信息来调度 map 任务从而在 trasktracker 上处理这些分片数据.
* - 在 tasktracker 上, map 任务把输入分片传给 InputFormat 的createRecordReader() 方法来获取这个分片的RecordReader
* - map 任务用一个 RecordReader 来生成记录的键/值对, 然后在传递给 map 函数。
*/
}
- FileInputFormat 类
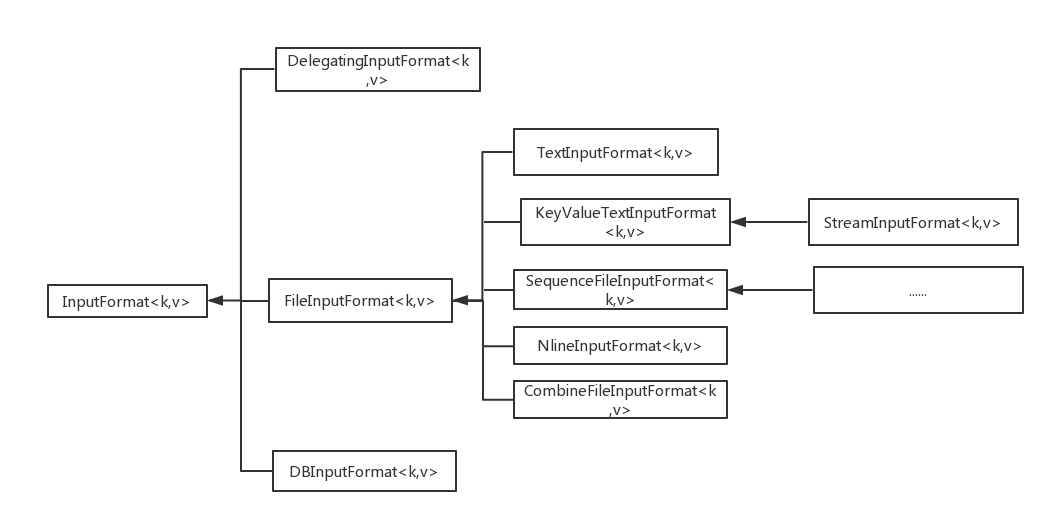
- FileInputFormat
作业的输入被设置为一组路径, 这对指定作业的输入提供了很强的灵活性
- 一个被指定为输入路径的目录, 其内容不会递归处理,
- 解决问题的办法是 : 使用一个文件 glob 或 一个过滤器根据明明模式限定选择目录的文件,
- add 方法 和 set 方法允许指定包含的文件。
- 如果需要排除特定的文件, 可以使用 FileInputFormat 的 setInputPathFileter() 设置一个过滤器
- FileInputFormat 只分隔大文件, 这里的大指的是超过 HDFS 块大小, 分片通常与 HDFS 大小相同
- 小文件与 CombineFileInputFormat
相对于大批量的小文件, Hadoop 更适合处理少量的大文件
- CombineFileInputFormat 可以缓解这个问题, 他把多个文件打包到一个分区中以便每个 mapper 可以处理更多的数据。
- CombineFileInputFormat 处理分片会考虑到节点和机架因素
- 避免切片
- 增加最小分片的大小
- 使用 FileInputFormat 的具体子类, 并且重载 isSplitable() 方法把返回置为 false。
public class NoSplitInputFormat extends TextInputFormat{
@Override
protected boolean isSplitable(FileSystem fs, Path file) {
return false;
}
}
- mapper 中的文件信息
处理文件输入分片的 mapper 可以从作业的某些特定属性中读取 输入分片的有关信息
- 通过 Mapper 的context 对象上的 getInputSplit() 方法来获取 InputSplit 对象 , 可以强制转换为 FileInputSplit;
-> getPath() // 曾在处理的输入输入文件的路径
-> getStart() // 分片开始处的字节偏移量
-> getLength() // 分片的长度
- 把整个文件作为一条记录来处理
- 文本输入
输入分片在 java 中表示为 InputSplit 接口
public abstract class InputSplit{
public abstract long getLength() throws IOException, InterruptedException;
public abstract String[] getLocations() throws IOException, InterruptedException;
}
- 分片不包含数据本身, 而是指向数据的引用。
- 存储位置供 MapReduece 系统使用以便将 map 任务尽量放在分片数据附近
- 存储大小用来排序分片
- MapReduce 应用开发人员不直接处理 InputSplit , 因为它将由 InputFormat 创建。 InputFormat 负责产生输入分片并将他们分割成记录
public abstract class InputFormat<Text, Text>{
public abstract RecordReader<Text, Text> createRecordReader(InputSplit arg0, TaskAttemptContext arg1)throws IOException, InterruptedException;
public abstract List<InputSplit> getSplits(JobContext arg0) throws IOException, InterruptedException;
/*
* - getSplits() 负责计算分片, 然后将他们发送到 jobtracker
* - jobtracker 使用其存储位置信息来调度 map 任务从而在 trasktracker 上处理这些分片数据.
* - 在 tasktracker 上, map 任务把输入分片传给 InputFormat 的createRecordReader() 方法来获取这个分片的RecordReader
* - map 任务用一个 RecordReader 来生成记录的键/值对, 然后在传递给 map 函数。
*/
}
- FileInputFormat 类
- FileInputFormat
作业的输入被设置为一组路径, 这对指定作业的输入提供了很强的灵活性
- 一个被指定为输入路径的目录, 其内容不会递归处理,
- 解决问题的办法是 : 使用一个文件 glob 或 一个过滤器根据明明模式限定选择目录的文件,
- add 方法 和 set 方法允许指定包含的文件。
- 如果需要排除特定的文件, 可以使用 FileInputFormat 的 setInputPathFileter() 设置一个过滤器
- FileInputFormat 只分隔大文件, 这里的大指的是超过 HDFS 块大小, 分片通常与 HDFS 大小相同
-
小文件与 CombineFileInputFormat
相对于大批量的小文件, Hadoop 更适合处理少量的大文件
- CombineFileInputFormat 可以缓解这个问题, 他把多个文件打包到一个分区中以便每个 mapper 可以处理更多的数据。 - CombineFileInputFormat 处理分片会考虑到节点和机架因素 -
避免切片
- 增加最小分片的大小
- 使用 FileInputFormat 的具体子类, 并且重载 isSplitable() 方法把返回置为 false。
public class NoSplitInputFormat extends TextInputFormat{ @Override protected boolean isSplitable(FileSystem fs, Path file) { return false; } } -
mapper 中的文件信息
处理文件输入分片的 mapper 可以从作业的某些特定属性中读取 输入分片的有关信息
- 通过 Mapper 的context 对象上的 getInputSplit() 方法来获取 InputSplit 对象 , 可以强制转换为 FileInputSplit; -> getPath() // 曾在处理的输入输入文件的路径 -> getStart() // 分片开始处的字节偏移量 -> getLength() // 分片的长度 -
把整个文件作为一条记录来处理
-
文本输入
-
TextInputFormat
TextInputFormat 是默认的 InputFormat.
- 每条记录是一行输入
- 键 : LongWritable类型, 存储该行在文件中的字节偏移量
- 值 : 这一行的内容
说明:
- 一般情况下很难获取行号, 因为文件按照字节进行切片
- 如果某行会跨文件存放, 这意味着会执行远程的读取操作
- KeyValueText
- KeyValueTextInputFormat 与 TextInputFormat 相似
- 它可以指定分隔符来区分 key value [mapreduce.input.keyvaluelinerecordreader.key.value.separator]
- NLineInputFormat
- 如果希望mapper 收取固定行数的输入, 须将 NLineInputFormat 作为 InputFormat.
- [mapreduce.input.lineinputformat.linespermap]属性设置要读取的行数
- 键值与 TextInputFormat 相同
如果要用 顺序文件作为 MapReduce 的输入, 应用 sequenceInputFormat.
键值对由顺序文件决定
- SequenceFileAsTextInputFormat
将顺序文件的键值转为 Text 对象
- SequenceFileAsBinaryInputFormat
他获取顺序文件的键值作为作为 二进制对象, 他们被封装为 ByteWritable 对象。
- MultipleInputs 允许为每条路径指定InputFormat 和 Mapper
MultipleInputs.addInputPath(job, metofficeInputPath, TextInputFormat.class, MetofficeMaxTeperatureMapper.class);
默认的输出格式是 TextOutputFormat , 他把每条记录写为文本行。 他的键值可以是任意类型, 他将调用 toString() 方法转换为字符串
- SequenceFileOutFormat:
他的输出为一个顺序文件, 他的格式紧凑, 很容易被压缩。
- SequenceFileAsBinaryOutputFormat:
它把 键/值 对作为二进制格式写到一个 SequenceFile 容器中
- MapFileOutputFormat :
- 把 MapFile 作为输出。
- MapFile 中的键必须顺序添加, 所以必须确保 reducer 输出的键已经排好序
MutipleOutputFormat 类
- MutipleOutputFormat 类可以将数据写到多个文件, 这些文件名源于输出键和值的或任意字符串
- 采用 name-r-nnnnn 形式的文件名作为reduce的输出,