hadoop第一个版本刚开始是没HA(高可用high availability)的,那会儿出现很多问题,单台namenode出现故障,就导致集群hdfs没办法访问,数据虽然没有坏,但是namenode坏了,那会儿就是手动写脚本,把edits,fsimage这两个东西,也就是namenode的数据复制一份出来,一旦出现问题,就把数据恢复回去,但是这样很慢,也不知道啥时候namenode坏的,后来版本就在Hadoop中集成了HA,当namenode坏掉后,几毫秒内第二台namenode马上顶上去.这就意味着两台namenode里的数据是同步的,每执行一次操作,备份的namenode就会同步数据

保证高可用机制
有两台namenode,只有一台可以当主,它两个之间通信,看主机是否存活,当它俩之间通信出现故障的时候,第二台namenode就会自动启动,现在就会导致两台namenode同时活跃,现在用户上传数据的时候,就会出现抢占资源的情况,也就是官网上说的split-brain(脑裂),怎么解决这个问题呢?使用隔离机制,就是failovercontroller,它会跟它自己的controller进行通信,当controller接收不到消息时,就会通知另一边的controller主namenode挂掉了.failovercontroller失效备援,它是zookeeper下的一个子模块,用来控制namenode的,当第一台namenode切换到standby或者active的时候,就会通知standby那台切换到active状态.
数据同步机制
当用户操作hdfs的时候,editlog会发生变化,namenode会直接写入journalNode,以用来分享给其它的namenode节点.
节点配置情况

namenode的HA和resourcemanager的HA都需要zookeeper的namenode基于journalNode,journalNode基于zookeeper
详细配置 我是以102,103,104三台节点为例配置


<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<!-- <value>hdfs://hadoop102:8020</value> -->
<!-- 以前就一个namenode节点,现在成了多个了,就要把它们统一起名 -->
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration> 
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定数据冗余份数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 完全分布式集群名称,这个名称必须个core-site.xml里的名称一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 ,防止脑裂-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录 这个路径是在当前用户的~目录下-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kxj/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-2.7.2/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>

然后把hadoop整个全部配置文件,分发到104,105,也就是三台节点都这么配
然后先启动zookeeper集群,三台节点都是这个状态,我就截一个图了

三台节点都启动jounderNode节点
sbin/hadoop-daemon.sh start journalnode

三台节点都清除data/logs删除这两个文件夹

然后进行初始化
bin/hdfs namenode -format
在102节点启动namenode
sbin/hadoop-daemon.sh start namenode
在n2上把n1的初始化数据拿过来,在103节点执行下面这个命令
bin/hdfs namenode -bootstrapStandby
在102上初始化后,102有tmp,103没有,执行完这个命令就把tmp拿过来了,就可以启动namenode了,不然103是启动不了namenode的

现在是没办法使用的都显示备用状态.


待机设备不允许读写权限.
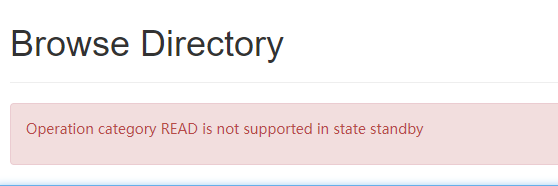
手动把nn1设置为active
bin/hdfs haadmin -transitionToActive nn1



datanode也不是无限量的存储,跟namenode的内存有关.namenode内存不够了也不让存
启动三台datanode,创建文件夹上传个文件试试 sbin/hadoop-daemon.sh start datanode


查看服务状态
bin/hdfs haadmin -getServiceState nn1

配置自动故障转移

<!-- 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- zookeeper集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>然后分发到别的机器,把配置文件再进行分发到别的两台节点
这个命令会把存储类型节点都停掉,sbin/stop-dfs.sh

如果遇到启动节点后,jps查不出来,但是显示已经启动了,这时就在tmp目录下,把对应的pid文件删掉就行了,有时候直接关机啥的,系统没来得及把这文件删掉,下次启动的时候它会上这里面一看发现有,就会出现这种问题,linux的进程都是以这种形式存在的,没关一个进程就会自动把pid文件删除掉.

初始化ha在zookeeper中的状态
bin/hdfs zkfc -formatZK

它就是在zookeeper中创建了一个目录

进入zookeeper客户端就可以看到,

sbin/start-dfs.sh 启动集群



现在是102是活跃状态,在102节点使用kill-9杀掉namenode节点

103就成active了,102就访问不了了.


如果没有切换的话,查看这个日志文件看报啥错了,进行相应的修改
