1.导入运行库
from keras.datasets import cifar10
import numpy as np
np.random.seed(10)
2.数据预处理
(x_img_train,y_label_train),(x_img_test,y_label_test)=cifar10.load_data()
print("train data:",'images:',x_img_train.shape,
" labels:",y_label_train.shape)
print("test data:",'images:',x_img_test.shape ,
" labels:",y_label_test.shape)
x_img_train_normalize = x_img_train.astype('float32') / 255.0
x_img_test_normalize = x_img_test.astype('float32') / 255.0
from keras.utils import np_utils
y_label_train_OneHot = np_utils.to_categorical(y_label_train)
y_label_test_OneHot = np_utils.to_categorical(y_label_test)
3.建立训练模型
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
model = Sequential()
model.add(Conv2D(filters=32,kernel_size=(3,3),
input_shape=(32, 32,3),
activation='relu',
padding='same'))
model.add(Dropout(rate=0.25))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=64, kernel_size=(3, 3),
activation='relu', padding='same'))
model.add(Dropout(0.25))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(rate=0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(rate=0.25))
model.add(Dense(10, activation='softmax'))
print(model.summary())
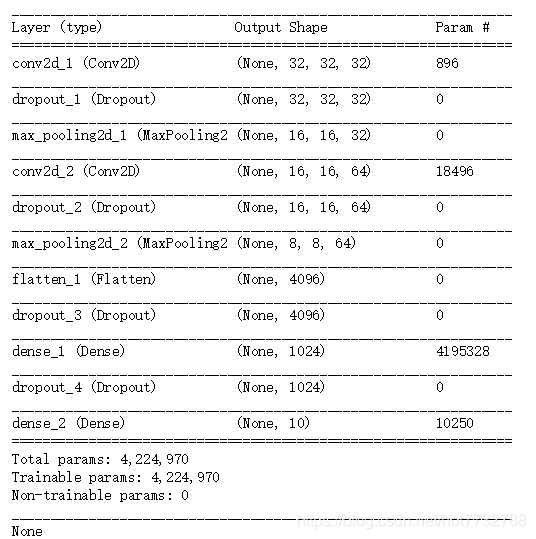
4.如果有已经训练好的模型超参数便读入
try:
model.load_weights("SaveModel/cifarCnnModelnew1.h5")
print("加载模型成功!继续训练模型")
except :
print("加载模型失败!开始训练一个新模型")
5.训练
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
train_history=model.fit(x_img_train_normalize, y_label_train_OneHot,
validation_split=0.2,
epochs=10, batch_size=128, verbose=1)
- veose数值变化对显示的影响
- 1(动态显示训练过程 )

- 2(等待完成一个epoch之后才会显示此次epoch的具体信息)

- 显示训练过程中的准确率,损失值的变化
import matplotlib.pyplot as plt
def show_train_history(train_acc,test_acc):
plt.plot(train_history.history[train_acc])
plt.plot(train_history.history[test_acc])
plt.title('Train History')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
show_train_history('acc','val_acc')
show_train_history('loss','val_loss')
scores = model.evaluate(x_img_test_normalize,
y_label_test_OneHot, verbose=0)
print(scores[1])
6.进行预测,查看预测结果
label_dict={0:"airplane",1:"automobile",2:"bird",3:"cat",4:"deer",
5:"dog",6:"frog",7:"horse",8:"ship",9:"truck"}
import matplotlib.pyplot as plt
def plot_images_labels_prediction(images,labels,prediction,
idx,num=10):
fig = plt.gcf()
fig.set_size_inches(12, 14)
if num>25: num=25
for i in range(0, num):
ax=plt.subplot(5,5, 1+i)
ax.imshow(images[idx],cmap='binary')
title=str(i)+','+label_dict[labels[i][0]]
if len(prediction)>0:
title+='=>'+label_dict[prediction[i]]
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.show()
plot_images_labels_prediction(x_img_test,y_label_test,
prediction,0,10)

7.查看数据样本预测为各个分类的具体概率
Predicted_Probability=model.predict(x_img_test_normalize)
def show_Predicted_Probability(y,prediction,
x_img,Predicted_Probability,i):
print('label:',label_dict[y[i][0]],
'predict:',label_dict[prediction[i]])
plt.figure(figsize=(2,2))
plt.imshow(np.reshape(x_img_test[i],(32, 32,3)))
plt.show()
for j in range(10):
print(label_dict[j]+
' Probability:%1.9f'%(Predicted_Probability[i][j]))
show_Predicted_Probability(y_label_test,prediction,
x_img_test,Predicted_Probability,0)

8.显示混淆矩阵
y_label_test.reshape(-1)
import pandas as pd
print(label_dict)
pd.crosstab(y_label_test.reshape(-1),prediction,
rownames=['label'],colnames=['predict'])
9.模型保存(important)参考
model_json = model.to_json()
with open("SaveModel/cifarCnnModelnew.json", "w") as json_file:
json_file.write(model_json)
model.save_weights("SaveModel/cifarCnnModelnew.h5")
print("Saved model to disk")
model_yaml = model.to_yaml()
with open("SaveModel/cifarCnnModelnew.yaml", "w") as yaml_file:
yaml_file.write(model_yaml)