先前只有自己的游戏本有一块GTX1050的GPU,所以对于官方的卷积神经网络教程,仅仅是按照自己的理解将教程简单化,具体见博客卷积神经网络:CIFAR-10训练和测试(单块GPU),现如今导师提供了具有两块GTX1080TiGPU 的工作站,硬件条件支持了,所以就将此教程完全实现一遍。
1. tf.app.flags 主要处理命令行参数的解析工作
tf.app.flag.DEFINE_xxx()就是添加命令行的可选参数(optional argument), 里面有三个参数,分别是参数名称,默认值和参数描述。如下面的代码所示,定义'num_gpu'为一个整数,默认值为1。
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string('train_dir', 'cifar10_multi_gpu_train_logs',
'''Directory where to write event logs and checkpoint''')
tf.app.flags.DEFINE_integer('max_steps', 100000, '''Number of batches to run''')
tf.app.flags.DEFINE_integer('num_gpus', 1, '''How many GPUs to use''')2. weight decay 是放在正则化前面的一个系数,正则化一般表示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就越大。
if wd is not None:
# 添加L2Loss, 并将其添加到‘losses’集合
weight_decay = tf.multiply(tf.nn.l2_loss(var), wd, name='weight_loss')
tf.add_to_collection('losses', weight_decay)3. tf.control_dependencies()设计是用来控制计算流图的,给图中的某些计算指定顺序。它是个context manager, 控制节点执行顺序,先执行[]中的操作,在执行context中的内容。
# tf.control_dependencies()是一个context manager, 控制节点执行顺序
# 先执行[]中的操作,在执行context中的操作
with tf.control_dependencies([loss_average_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
4. 在采用随机梯度下降算法训练网络时,使用tf.train.ExponentialMovingAverage滑动平均的意义在于提高模型在测试数据上的健壮性。tf.train.ExponentialMovingAverage包含两个参数,一个衰减率decay和一个num_updates。decay用于控制模型更新的速度,ExponentialMovingAverage对每一个变量(variable)都会维护一个影子变量(shadow variable)。影子变量的初始值就是这个变量的初始值,影子变量的计算公式为,decay 越大,shadow_variable 变化的越小,越趋于稳定。在实际运动中,decay的设置一般都接近于1(例如,0.99或者0.999或者0.9999)。num_updates参数动态设置decay的大小,
可以使得模型在训练的初始阶段更新得更快。
- apply()方法添加了训练变量的影子副本,并保持其影子副本中训练变量的移动平均值操作。在每次训练之后调用此操作,更新移动平均值
- average()和average_name()方法可以获取影子变量及其名称
# tf.train.ExponentialMovingAverage(decay, steps就是采用滑动平均的方法更新参数
# 这个函数初始化需要提供一个衰减速率decay,用于控制模型的更新速度,decay越大越趋于稳定
# ExponentialMovingAverage还提供num_updates参数来设置decay的大小,使得模型在训练的
# 初始阶段更新得更快
variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, num_updates=global_step)
# apply()方法添加了训练变量的影子副本,并保持其影子副本中训练变量的移动平均值操作
# 在每次训练之后调用此操作,更新移动平均值
with tf.control_dependencies([apply_gradient_op]):
variable_average_op = variable_average.apply(tf.trainable_variables())
5. 优化时,可以通过minimize()函数来同时计算梯度并更新该梯度所对应的参数状态,就是日常常见的代码方案,如想计算梯度,然后再将梯度对应参数状态更新,可以先利用computer_gradients()函数来计算梯度,(按照自己的需求处理梯度),然后调用apply_gradients()函数来更新该梯度所对应的参数的状态。前者不需要人工参与,比较省时省力,后者可以按照自己的需求改动后使用。
with tf.control_dependencies([loss_average_op]):
opt = tf.train.GradientDescentOptimizer(lr)
# 利用computer_gradients()函数计算梯度
grads = opt.compute_gradients(total_loss)
# 调用apply_gradients()函数来更新该梯度所对应的参数的状态
apply_gradient_op = opt.apply_gradients(grads, global_step=global_s6. 源码在训练时,并没有使用tensorboard显示训练中的一些实现数据,而是通过hook来检测网络训练的情况。
在训练中主要用到了tf.train.MonitoredTrainingSession()和tf.train.SessionRunHook()。
所有的hook都继承SessionRunHook, tf.train.SessionRunHook()类定义在tensorflow/python/trainning/session_run_hook.py中,类中包含五个通用的函数,如下:
- begin(self): 创建会话前调用,调用begin()时,default graph会被创建
- after_create_session(self, session,coord): tf.Session被创建后调用,调用后会指示所有的Hooks会有一个新的会话被创建
- before_run(seflt, run_context): 调用在每个sess.run()执行之前
- after_run(self, run_context, run_values): 调用在每个sess.run()之后
- end(self, session): 在会话结束时调用
tf.train.MonitorSession()参数过多,在这里就不展示,需要的可以去官方API文档查看。它的父类是MonitorSession。官方文档中中给出了一段示例代码:
saver_hook = CheckpointSaverHook(...) summary_hook = SummarySaverHook(...) with MonitoredSession(session_creator=ChiefSessionCreator(...), hooks=[saver_hook, summary_hook]) as sess: while not sess.should_stop(): sess.run(train_op)
操作流程如下:
Initialization:
- 对于Hooks列表中的hook,调用beigin()
- 通过scaffold.finalize()完成图的定义
- 创建会话
- 通过Scaffold提供的初始化操作初始化模型
- 如果checkpoint存在的话,恢复模型变量
- 启动队列线程
- 调用hook中的after_create_session()函数
Run:
- 调用Hook中的before_run()函数
- 用合并后的fetches和feed_dict调用Tensorflow中的session.run()定义的神经网络规模比较小,所以上图中的GPU的使用率并不高,如果训练大型的神经网络模型,Tensorflow将会占满所有能够用到的GPU
- 调用Hook中的after_run()函数
- 返回用户需要的session.run()结果
- 如果AbortedError和UnavailableError发生了,在再次执行run()之前恢复或者重新初始化会话
Exit
- 调用Hook中的end()函数
- 关闭队列线程和会话
- 在monitored_session的上下文中,抑制由于处理完所有输入抛出的OutOfRange错误
def train():
with tf.Graph().as_default():
global_step = tf.train.get_or_create_global_step()
with tf.device('/cpu:0'):
images, labels = cifar10.distorted_inputs()
logits = cifar10.inference(images)
loss = cifar10.loss(logits, labels)
train_op = cifar10.train(loss, global_step)
class _LoggerHook(tf.train.SessionRunHook):
'''
该类用来打印训练信息
'''
def begin(self):
'''
在创建会话之前调用,调用begin()时,default graph
会被创建,可在此处向default graph增加新op, begin()
调用后,default graph不能再被掉用
'''
self._step = -1
self._start_time = time.time()
def before_run(self, run_context):
'''
调用在每个sess.run()执行之前,可以返回一个
tf.train.SessRunArgs(op/tensor),在即将运行的会话中加入这些
op/tensor; 加入的op/tensor会和sess.run()中已定义的op/tensor
合并,然后一起执行。
@param run_context: A 'SessionRunContext' object
@return: None or a 'SessionRunArgs' object
'''
self._step += 1
# 在这里返回你想在运行过程中产看的信息,以list的形式传递,如:[loss, accuracy]
return tf.train.SessionRunArgs(loss)
def after_run(self, run_context, run_values):
'''
调用在每个sess.run()之后,参数run_values是before_run()中要求的
op/tensor的返回值;
可以调用run_contex.request_stop()用于停止迭代。
sess.run抛出任何异常after_run不会被调用
@param run_context: A 'SessionRunContext' object
@param run_values: A SessionRunValues object
'''
if self._step % FLAGS.log_frequency == 0:
current_time = time.time()
duration = current_time - self._start_time
self._start_time = current_time
# results返回的是上面before_run()的返回结果,上面是loss所以返回loss
# 如若上面返回的是个list,则返回的也是个list
loss_value = run_values.results
examples_per_sec = FLAGS.log_frequency * FLAGS.batch_size / duration
sec_per_batch = float(duration / FLAGS.log_frequency)
print('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f sec/batch)'
% (datetime.now(), self._step, loss_value, examples_per_sec, sec_per_batch))
'''
将计算图的各个节点/操作定义好,构成一个计算图。然后开启一个
MonitoredTrainingSession来初始化/注册我们的图和其他信息
在其参数hooks中,传递了三个hook:
1. tf.train.StopAtStepHook(last_step):该hook是训练达到特定步数时请求
停止。使用该hook必须要预先定义一个tf.train.get_or_create_global_step()
2. tf.train.NanTensorHook(loss):该hook用来检测loss, 若loss的结果为NaN,则会
抛出异常
3. _LoggerHook():该hook是自定义的hook,用来检测训练过程中的一些数据,譬如loss, accuracy
。首先会随着MonitoredTrainingSession的初始化来调用begin()函数,在这里初始化步数,before_run()
函数会随着sess.run()函数的调用而调用。所以每训练一步调用一次,这里返回想要打印的信息,随后调用
after_run()函数。
'''
with tf.train.MonitoredTrainingSession(checkpoint_dir=FLAGS.train_dir,
hooks=[tf.train.StopAtStepHook(last_step=FLAGS.max_steps),
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement
)) as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
7. 在多个GPU上训练模型。在具有多个GPU的工作站中,每个GPU的速度基本接近,并且都含有足够的内存来运行整个CIFAR-10模型。因此我们选择以下方式来设计我们的训练系统:在每个GPU上放置单独的模型副本,等所有的GPU处理完一批数据后再同步更新模型的参数。这一机制要求所有GPU能够共享模型参数。由于GPU之间传输数据非常慢,因此在CPU上存储和更新所有模型的参数。
如下图所示,每一个GPU会用一批独立的数据计算梯度和估计值,而且GPU是同步运行的,所有GPU中的梯度会累积并求平均值(CPU),所以导致GPU在处理一批新的数据之前会更新一遍参数。
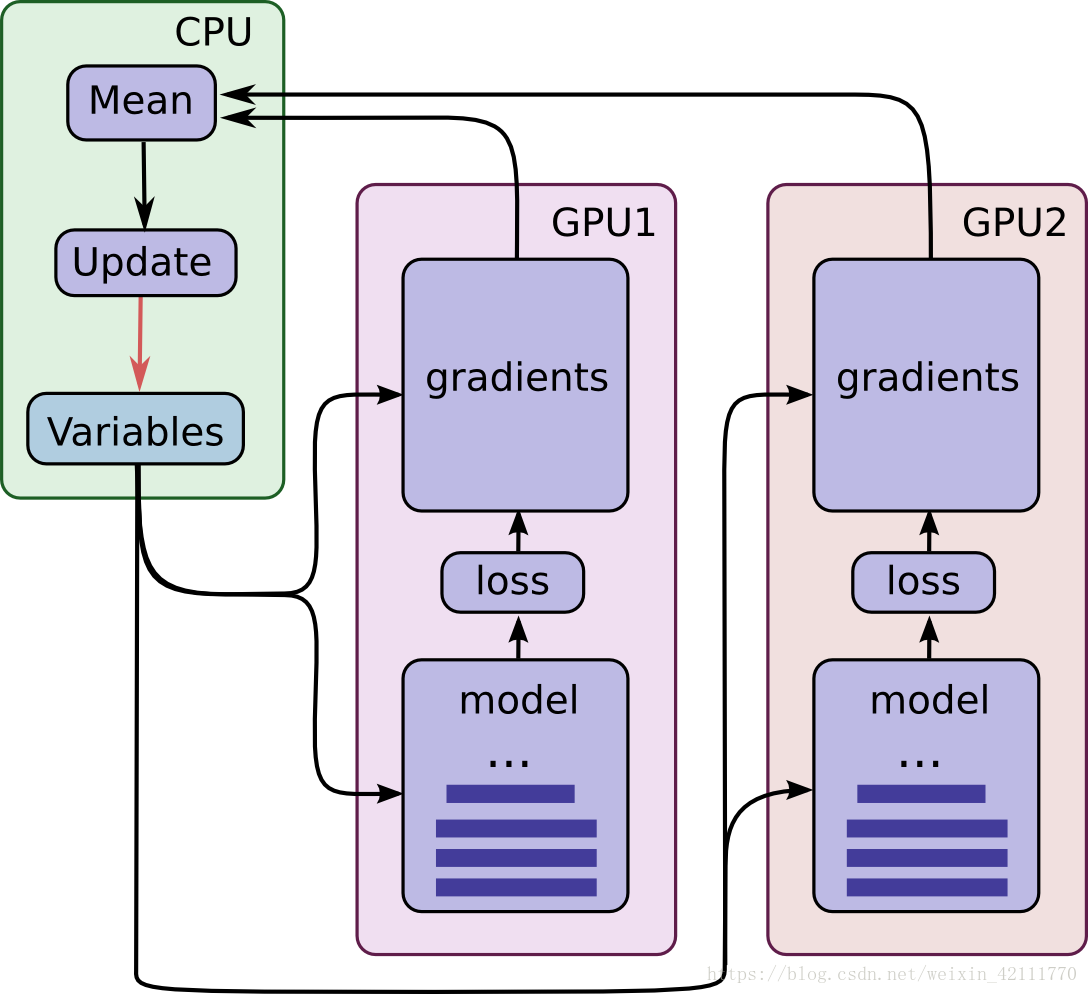
总而言之就是:模型参数保存在cpu上,模型参数的副本在不用gpu上,每次训练,提供batch_size*gpu_nums数据,并等量拆分成多个batch,分别送入不同GPU。前向在不同gpu上进行,模型参数更新时,将多个GPU后向计算得到的梯度数据进行平均,并在cpu上利用梯度数据更新模型参数
8. 在多个设备中设置变量和操作。在多个设备中设置变量和操作需要做一些特殊的抽象,首先需要把在单个模型拷贝中计算估计值和梯度的行为抽象到一个函数中,在代码中,我们称这个抽象对象为"tower"。对每一个"tower"设置两个属性:
在一个tower中为所有操作设定一个唯一的名称。tf.name_scope()通过添加一个范围前缀来提供该唯一的名称。比如,在第一个tower中的所有操作都会附带一个前缀tower_0
在一个tower中运行操作的优先硬件设备。tf.device()提供该信息。比如,在第一个tower中的所有操作都位于device('/gpu:0')范围中,暗含的意思是这些操作应该运行在第一块GPU上。
为了在多个GPU上共享变量,所有的变量都绑定在CPU上,并通过tf.get_variable()访问。
9. tf.ConfigProto()函数是用在创建session的时候,用来对session进行参数配置。
- 参数llog_device_placement=True记录设备指派情况,可以获取到operations和Tensor被指派到哪个设备(几号CPU或几号GPU)上运行,在终端打印出各项操作是在哪个设备上运行的
- 参数allow_soft_placement=True自动选择运行设备,允许tf自动选择一个存在并且可用的设备来运行操作
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
log_device_placement=FLAGS.log_device_placement))tensorflow提供了两种限制GPU资源使用的方法,一是让tf在运行过程中动态申请内存,需要多少就申请多少;第二种方式就是研制GPU的使用率。
config= tf.ConfigProto()
# 动态申请显存
config.gpu_options.allow_growth = True
# 限制GPU使用率,占用40%显存
config.gpu_options.per_process_gpu_memory_fraction = 0.4
sess = tf.Session(config=config)10. 启动并在多个GPU上训练模型。运行multi_gpu_train.py,使用多个GPU实现模型并行训练。我有两个GPU,所以设num_gpus=2.
python multi_gpu_train.py --num_gpus=2
注:tensorflow在训练时默认占用所有的GPU显存。
用多GPU运行时,发现一个问题,两块GPU运行的时间竟然是单块GPU运行时间的近2倍,使用nvidia-smi命令查看GPU的使用起情况,发现GPU的使用率过低,如下图所示:
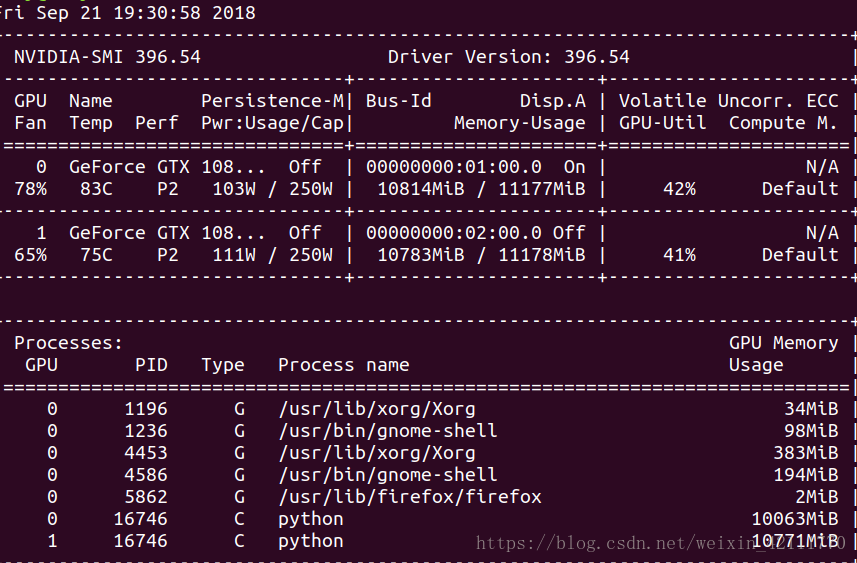
原因可能是:定义的神经网络规模比较小,所以上图中的GPU的使用率并不高,如果训练大型的神经网络模型,Tensorflow将会占满所有能够用到的GPU(这是我目前找到的能使我信服的解释,具体如何,等到有时间训练一个复杂的网络后再去看看GPU运行效率如何)。毕竟cifar10数据集并不是多大,而且定义的网络模型并不是很复杂。
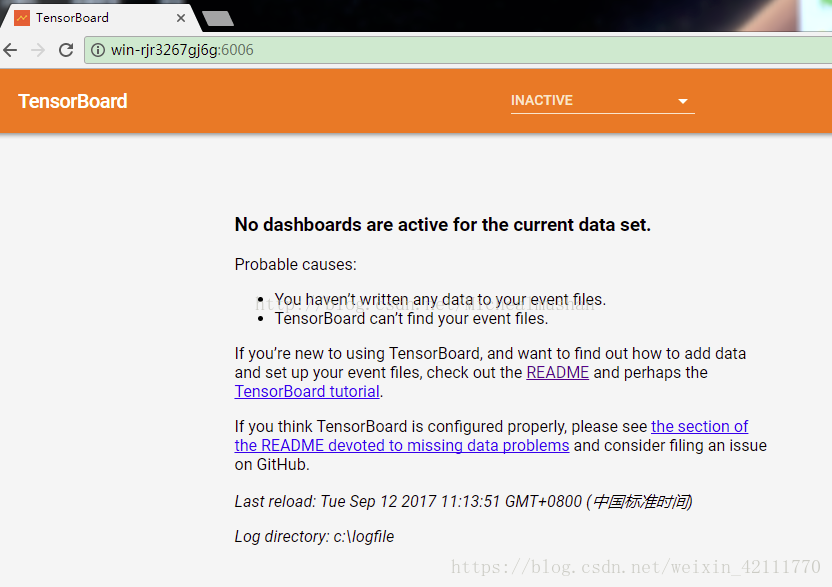
11. 最后是tensorboard可视化问题。原先使用tensorboard --logdir=/PycharmProjects/cifar10/cifar10_train或者tensorboard --logdir=/cifar10_train就会出现如下"No dashboards are active for thr current data set",网上答案千奇百怪,好像每个人遇见的困难都不一样,最后,我是使用tensorboard --logdir=cifar10_train才成功的,有人解释是‘/’这个符号问题,可是不同系统要求的格式不同吧。
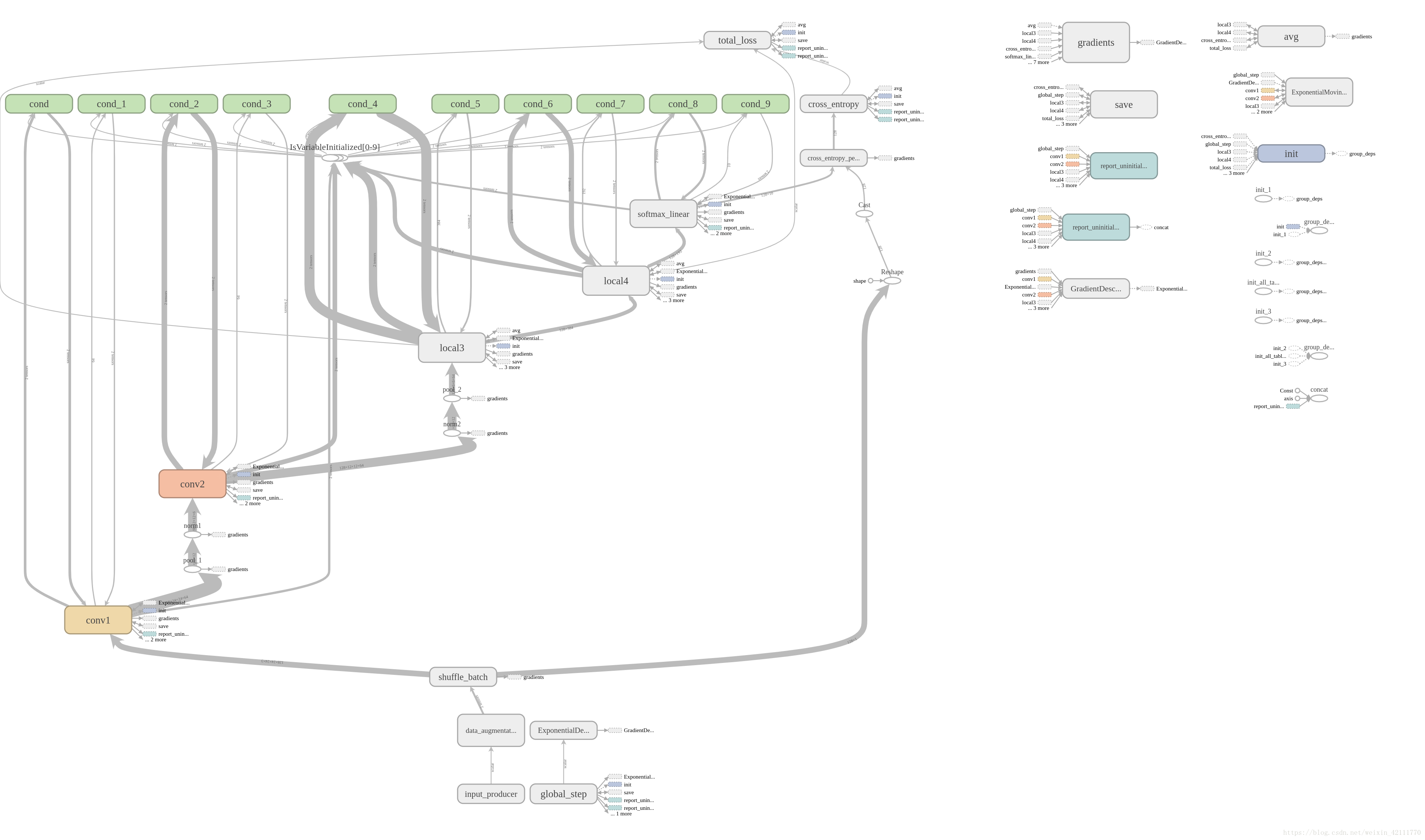
最后,奉上网络架构图: