1、data降维
1、what?
维度(数组的维度)
降维:维度(特征的数量) 3个特征----> 2个特征

2、data降维方法
1. 特征选择
2. 主成分分析
2、特征选择
1、reason of 特征选择


2、what is 特征选择?

3、主要方法

扫描二维码关注公众号,回复:
5924118 查看本文章



4、varianceThreshold 删除低方差的特征
1.sklearn特征选择api
sklearn.feature_selection.VarianceThreshold
2.语法

3.流程

4.代码
def var():
"""
特征选择--删除低方差的特征
:return: None
"""
# var = VarianceThreshold(threshold=0.0) # 删除特征相同的data
var = VarianceThreshold(threshold=1.0)
data = var.fit_transform([[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]])
print(data)
return None
if __name__ == '__main__': var()

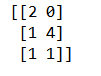
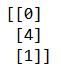
5.意义
删除差不多相同的特征data
3、PCA(主成分分析)
1、what is PCA


2、三维-----> 二维
所有data信息并未损耗太多
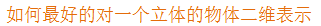

高维度数据容易出现的问题
特征相关


找到最好的箭头?

PCA目的:简化dataSet
3、公式计算(了解)

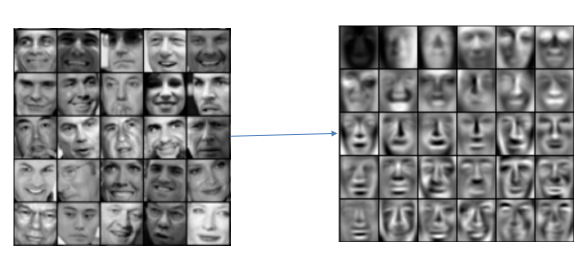
4、人脸特征主成分分析
5、PCAdemo
1、语法

一般保留90%以上的信息

2、流程

3、代码
def pac():
"""
主成分分析 进行 特征降维
:return: None
"""
pca = PCA(n_components=0.9)
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None if __name__ == '__main__': pac()
是原data的 90%的信息
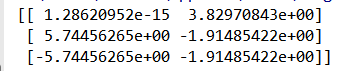
4、探究:用户对物品类别的喜好细分降维
kaggle比赛题, 预测用户对物品类别的喜好
https://www.kaggle.com/c/instacart-market-basket-analysis

data

1、合并各张表到一张表中


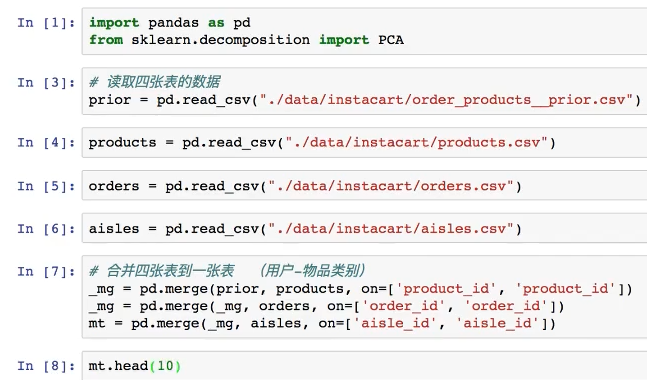
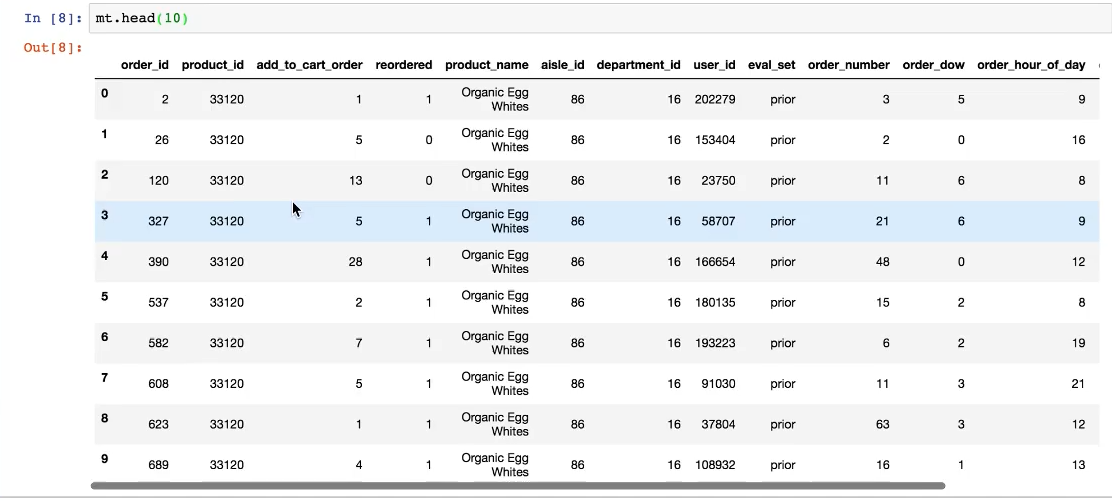


3、进行主成分分析
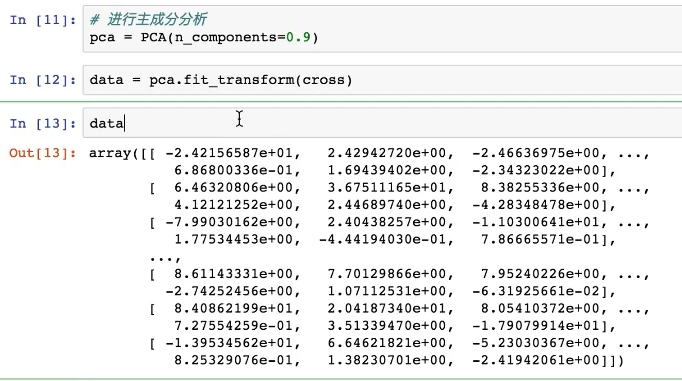


134简化到 27
5、jupyter notebook的安装和打开
安装非常简单,只需要在终端输入:
pip install jupyter
打开jupyter notebook 也只需要在终端输入:
jupyter notebook
运行上面的命令之后,你将看到类似下面这样的输出:

如上图,它打开了一个端口,并且会在你的浏览器中打开这个页面,主目录是图中的那个directory(可能第一次打开没有这个目录)。

点击New,选择python3

6、其他降维方法

7、

维度特征 数量有几百个 用PCA