版权声明:转载请说明来源,谢谢 https://blog.csdn.net/wsp_1138886114/article/details/86600995
我们在训练模型时,要将 tensorflow 训练好的模型参数保存起来,以便以后进行验证或测试。此时就涉及到将模型持久化,和模型的再次读取。tensorflow中提供了这些类。
模型保存 tf.train.Saver()
- 模型保存,先要创建一个Saver对象。
在创建这个Saver对象的时候,有一个参数我们经常会用到,就是 max_to_keep 参数,这个是用来设置保存模型的个数,默认为5,即 max_to_keep=5,保存最近的5个模型。如果你想每训练一代(epoch)就想保存一次模型,则可以将 max_to_keep设置为None或者0。
当然,如果你只想保存最后一代的模型,则只需要将max_to_keep设置为1即可。(其实我们只需要保存最后一个就好) - write_meta_graph:bool型,是否把TensorFlow的图保存下来
- 创建完saver对象后,就可以保存训练好的模型了。
saver=tf.train.Saver(max_to_keep=1)
saver.save(sess,'./name.ckpt',global_step=step)
# 参数: 保存的sess,路径和名字,训练的次数作为后缀加入到模型名字中
# saver.save(sess, 'model.ckpt', global_step=1000) ==> filename: 'model-1000'
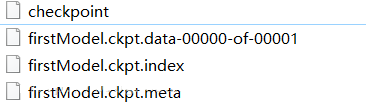
- meta:保存了TensorFlow的graph。包括all variables,operations,collections等等。
- checkpoint:二进制文件,保存了所有weights,biases,gradient and all the other variables的值。也就是上图中的.data-00000-of-00001和.index文件。.data文件包含了所有的训练变量。与此同时,Tensorflow还有一个名为checkpoint的文件,只保存最新检查点文件的记录,即最新的保存路径。
模型恢复 restore()
模型恢复restore(sess, save_path)函数:
- 参数:
-
sess:模型
save_path:模型保存的模型路径。使用tf.train.latest_checkpoint()来自动获取最后一次保存的模型
model_file=tf.train.latest_checkpoint('ckpt/')
saver.restore(sess,model_file)
sess = tf.Session()
#加载整个graph:不需要重新构建整个graph了
new_saver = tf.train.import_meta_graph('../model/model_LR_test.meta')
#加载模型中各种变量的值,注意这里不用文件的后缀
new_saver.restore(sess,'../model/model_LR_test')
#对应第一个文件的add_to_collection()函数
#返回值是一个list,我们要的是第一个,这也说明可以有多个变量的名字一样。
hyp = tf.get_collection('hypothesis')[0]
graph = tf.get_default_graph()
X = graph.get_operation_by_name('X').outputs[0]#为了将placeholder加载出来
pred = sess.run(hyp,feed_dict = {X:x_valid})
print('auc:',auc(y_valid,pred))
小案例
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=False)
x = tf.placeholder(tf.float32, [None, 784])
y_=tf.placeholder(tf.int32,[None,])
dense1 = tf.layers.dense(inputs=x,
units=1024,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
dense2= tf.layers.dense(inputs=dense1,
units=512,
activation=tf.nn.relu,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
logits= tf.layers.dense(inputs=dense2,
units=10,
activation=None,
kernel_initializer=tf.truncated_normal_initializer(stddev=0.01),
kernel_regularizer=tf.nn.l2_loss)
loss=tf.losses.sparse_softmax_cross_entropy(labels=y_,logits=logits)
train_op=tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(logits,1),tf.int32), y_)
acc= tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess=tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
is_train=True
saver=tf.train.Saver(max_to_keep=3)
#训练阶段
if is_train:
max_acc=0
f=open('ckpt/acc.txt','w') # 1.新建txt文件记录训练acc与loss过程
for i in range(100):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_op, feed_dict={x: batch_xs, y_: batch_ys})
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print('epoch:%d, val_loss:%f, val_acc:%f'%(i,val_loss,val_acc))
f.write(str(i+1)+', val_acc: '+str(val_acc)+'\n') # 2.写入文本
if val_acc>max_acc: # 确保保存最好的精度
max_acc=val_acc
saver.save(sess,'ckpt/mnist.ckpt',global_step=i+1)
f.close() # 3.关闭文本
#验证阶段
else:
model_file=tf.train.latest_checkpoint('ckpt/')
saver.restore(sess,model_file) # 模型恢复
val_loss,val_acc=sess.run([loss,acc], feed_dict={x: mnist.test.images, y_: mnist.test.labels})
print('val_loss:%f, val_acc:%f'%(val_loss,val_acc))
sess.close()
虽然我在每训练完一代的时候,都进行了保存,但后一次保存的模型会覆盖前一次的,最终只会保存最后一次。因此我们可以节省时间,将保存代码放到循环之外(仅适用max_to_keep=1,否则还是需要放在循环内)。
鸣谢
https://blog.csdn.net/liweibin1994/article/details/78307382