版权声明:转载请说明来源,谢谢 https://blog.csdn.net/wsp_1138886114/article/details/86629583
运行环境
win10 | Anaconda | PyTorch ==1.0 | python==3.6.8
这一章,主要将模型的保存与加载,下面我们通过一个示例来演示,模型的成功保存与加载。
一、模型保存与加载
模型保存和加载的两种方式。关于详情请点击
1.1 只保存和载入模型参数
这种方式需要自己定义网络,并且其中的参数名称与结构要与保存的模型中的一致(可以是部分网络,比如只使用VGG的前几层),相对灵活,便于对网络进行修改。)
PATH = "./params.pkl"
torch.save(the_model.state_dict(), PATH) # 模型保存
the_model = TheModelClass(*args, **kwargs) # 初始化并载入模型
the_model.load_state_dict(torch.load(PATH))
def save_model(model, filename): # 若是使用GPU训练,先将数据转换到cpu中,再保存
state = model.state_dict()
for key in state: state[key] = state[key].clone().cpu()
torch.save(state, filename)
1.2 保存和载入整个模型
无需自定义网络,保存时已把网络结构保存,不能调整网络结构。
torch.save(the_model, './model.pkl') # 模型保存。参数:(模型,路径/文件名)
the_model = torch.load('./model.pkl') # 模型加载
1.3 关于多GPU的模型保存,加载等问题。
- 若使用nn.DataParallel在一台电脑上使用了多个GPU,load模型的时候也必须先DataParallel,这和keras类似。
- load提供了很多重载的功能,其可以把在GPU上训练的权重加载到CPU上跑。
torch.load('tensors.pt')
# 把所有的张量加载到CPU中
torch.load('tensors.pt', map_location=lambda storage, loc: storage)
# 把所有的张量加载到GPU 1中
torch.load('tensors.pt', map_location=lambda storage, loc: storage.cuda(1))
# 把张量从GPU 1 移动到 GPU 0
torch.load('tensors.pt', map_location={'cuda:1':'cuda:0'})
# 在cpu上加载预先训练好的GPU模型
torch.load('my_file.pt', map_location=lambda storage, loc: storage)
上述代码只有在模型在一个GPU上训练时才起作用。如果我在多个GPU上训练我的模型,保存它,然后尝试在CPU上加载,我得到这个错误:KeyError: ‘unexpected key “module.conv1.weight” in state_dict’ 如何解决?
您可能已经使用模型保存了模型nn.DataParallel,该模型将模型存储在该模型中module,而现在您正试图加载模型DataParallel。您可以nn.DataParallel在网络中暂时添加一个加载目的,也可以加载权重文件,创建一个没有module前缀的新的有序字典,然后加载它。
# original saved file with DataParallel
state_dict = torch.load('myfile.pth.tar')
from collections import OrderedDict
new_state_dict = OrderedDict() #创建一个没有module前缀新有序字典,然后加载它。
for k, v in state_dict.items():
name = k[7:] # remove `module.`
new_state_dict[name] = v
model.load_state_dict(new_state_dict) # load params
示例:
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 随机数种子
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y = x*x +0.2*torch.rand(x.size())
x,y = Variable(x,requires_grad=False),Variable(y,requires_grad=False)
def train_save():
net1 = torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
optimizer = torch.optim.SGD(net1.parameters(),lr=0.01)
loss_func = torch.nn.MSELoss()
plt.ion()
for t in range(10000): # 设置不同的步数100,1000
y_pred = net1(x)
loss = loss_func(y_pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#==================== 此段代码用来查看训练过程 ==================
# if (t + 1) % 50 == 0:
# plt.cla()
# pred_y = y_pred.data.numpy().squeeze()
# plt.scatter(x.data.numpy(), y.data.numpy())
# plt.plot(x.data.numpy(), y_pred.data.numpy(), "r-", lw=3)
# print('epoch {} \t loss is {:.4f} \tacc is {:.4f}'.format(t+1,print_loss,acc)) # 训练轮数
# plt.text(1.5, -4, 'acc=%.2f' % acc, fontdict={'size': 16, 'color': 'red'})
# plt.pause(0.05)
# plt.ioff()
# plt.show()
#=============================================================
# 绘图
plt.figure(1,figsize=(12,3))
plt.subplot(131)
plt.title("net1")
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),y_pred.data.numpy(),"r-",lw=5)
torch.save(net1,"net1.pkl")
torch.save(net1.state_dict(),"net_params.pkl")
def restore_net():
net2 = torch.load("net1.pkl")
prediction = net2(x)
plt.subplot(132)
plt.title("net2")
plt.scatter(x.data.numpy(),y.data.numpy())
plt.plot(x.data.numpy(),prediction.data.numpy(),"r-",lw=5)
def restore_params():
net3 = torch.nn.Sequential(
torch.nn.Linear(1,10),
torch.nn.ReLU(),
torch.nn.Linear(10,1)
)
net3.load_state_dict(torch.load("net_params.pkl"))
prediction = net3(x)
plt.subplot(133)
plt.title("net3")
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), "r-", lw=5)
plt.show()
if __name__ == '__main__':
train_save()
restore_net()
restore_params()
我设置了不同的步数,展现一样的结果。
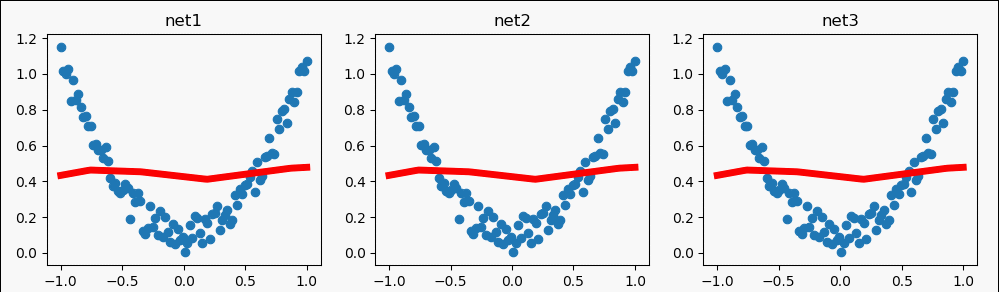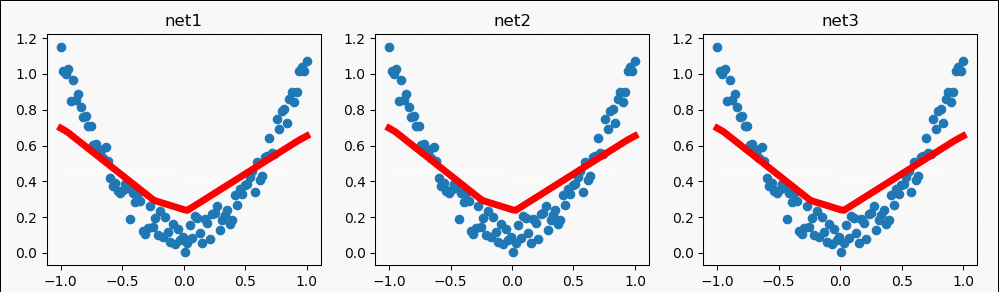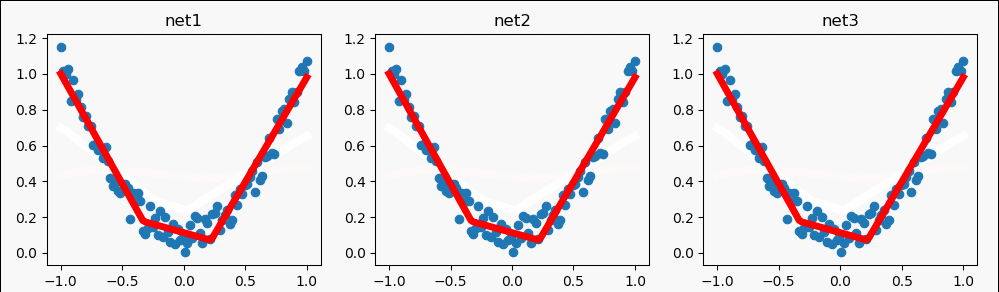
二、批训练
Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练。
import torch
import torch.utils.data as Data
torch.manual_seed(1)
Batch_size = 5
x = torch.linspace(1,2,10)
y = torch.linspace(10,1,10)
# 先转换成torch能识别的Dataset
torch_dataset = Data.TensorDataset(x,y)
# 把dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset数据格式
batch_size=Batch_size, # mini batch size
shuffle= True, # 是否打乱数据
num_workers = 2 # 多线程读取
)
if __name__ == '__main__':
for epoch in range(3):
for step,(batch_x,batch_y) in enumerate(loader): # 一批数据
print('epoch:',epoch,"| step:",step,
"| batch_x:",batch_x.numpy(),
"| batch_y:", batch_y.numpy())
输出:
epoch: 0 | step: 0 | batch_x: [1.4444444 1.6666667 2. 1.2222222 1.3333334] | batch_y: [6. 4. 1. 8. 7.]
epoch: 0 | step: 1 | batch_x: [1.1111112 1. 1.7777778 1.8888888 1.5555556] | batch_y: [ 9. 10. 3. 2. 5.]
epoch: 1 | step: 0 | batch_x: [1.3333334 1.5555556 1.6666667 2. 1.7777778] | batch_y: [7. 5. 4. 1. 3.]
epoch: 1 | step: 1 | batch_x: [1.4444444 1.2222222 1.1111112 1. 1.8888888] | batch_y: [ 6. 8. 9. 10. 2.]
epoch: 2 | step: 0 | batch_x: [1.3333334 1.1111112 1.4444444 1.5555556 2. ] | batch_y: [7. 9. 6. 5. 1.]
epoch: 2 | step: 1 | batch_x: [1.2222222 1.8888888 1. 1.7777778 1.6666667] | batch_y: [ 8. 2. 10. 3. 4.]
报错与问题解决
- 在 pytorch=0.4版本 Data.TensorDataset(data_tensor=x,target_tensor=y),现在修改为 Data.TensorDataset(x,y)
if name == ‘main‘: freeze_support()问题:在多线程环境中,mac不需要这行代码能够正常运行,在windows10中需要添加if __name__ == '__main__':才能正常运行。
第二个报错错误详情:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
特别鸣谢
https://blog.csdn.net/Gavinmiaoc/article/details/80491688
https://www.ptorch.com/news/74.html
https://blog.csdn.net/my_kingdom/article/details/85218478