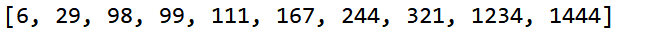重学java-7.常用的数组排序【2】
常用的数组排序
这一篇主要讲 优化 的交换排序、选择排序、插入排序。
如果文字描述使我们迷惑,直接看代码或许是个更为明智的选择。
排序算法比较表格

图片来自 该博文,里面有算法实现的gif图,向大家安利一下。
该博文 关于各类算法的时间复杂度讲得比较细。
优化的插入排序-希尔排序
- 思路:
希尔排序是对直接插入排序的优化。我们可以发现,直接插入排序在数组已经有序的情况下是 O(n) 的,因此科学家们设计了一种算法,让插入排序的每次步骤都能使数组整体上尽可能的接近有序。从而提出了 增量/步长 的概念。
举个例子:
假设现在有6张卡片,顺序为3,6,2,5,1,4,使其升序。设增量为2.
则相当于对3,2,1,6,5,4分别进行直接插入排序。
排序结果为1,4,2,5,3,6。
再把增量设为1.对整体进行直接插入排序。
排序结果为1,2,3,4,5,6。完成排序。
其实看代码就能发现,希尔排序的代码无非就是在直接插入排序的基础上,把所有的1改成了gap。
- 核心代码:
public static void insertionSort(int array[]) {
for(int gap = array.length / 2; gap > 0; gap /= 2) {
for(int i = gap; i < array.length; i += gap) {
int u = array[i], j;
for(j = i - gap; j >= 0 && array[j] > u; j -= gap) {
array[j + gap] = array[j];
}
array[j + gap] = u;
}
}
print(array);
}
public static void print(int array[]) {
System.out.println(Arrays.toString(array));
}
优化的交换排序-快速排序
- 思路:快速排序属于交换排序。可以看做是冒泡排序在 分治 思路下的优化。
快排的大致实现过程是这样的:把一个数作为基准,把比它小的数都放在它左边,比它大的数都放在右边。这样排完之后,再把左边那一块作为一个区间整体,右边那一块作为区间整体,重复上述的操作,直到区间就剩一个数,那就是完成升序排序了。
换个角度来说,对于一个数组,如果每个数都比其左边的数大,比右边的数小,那这个数组就是升序。快排就是一步一步接近这个目标的排序:在每一次递归的过程中,都会设置一个基准,满足它左边的数都小于它,右边的数都大于大。
核心代码:
递归实现
public static void quickSort(int[] arr,int left,int right){
if(left >= right) return;
int i = method(arr, left, right);
quickSort(arr,left,i-1);
quickSort(arr,i+1,right);
}
非递归实现
public static void quickSort2(int []arr, int left, int right) {
Stack<Integer> s = new Stack<Integer>();
s.push(left);
s.push(right);
while(!s.empty()) {
right = s.peek(); s.pop();
left = s.peek(); s.pop();
if(left >= right) continue;
int i = method2(arr, left, right);
s.push(left);
s.push(i-1);
s.push(i+1);
s.push(right);
}
}
其中method有三种常用的实现方法。
挖坑法
这个方法是最好理解的,举个例子,下面是以下标为1开始的数组nu[],l和r表示下标。
3,1,4,2,5
我们把最 左 边的数 3 作为基准,l=1,r=5。
- 先从r向l找比 3 小的数,找到了 2 ,就把 2 放在 3 的位置上,即nu[l]=nu[r]。此时r==4,数组变为
2,1,4,2,5 - 再从l向r找比 3 大的数,找到了 4 ,就把 4 放在 2 的位置上,即nu[r]=nu[l]。此时l==3。数组变为
2,1,4,4,5 - 继续第1步操作,发现l == r == 3,就把基准放在当前位置,数组变为
2,1,3,4,5 - 此时,3的左边都比3小,3的右边都比3大。再让他左右两个区间重复上述操作,即可完成最终的排序。
以上就是挖坑法的实现思路。
核心代码:
public int method1(int array[], int left, int right) {//挖坑法
int key = array[left];
while(left < right) {
while(array[right] >= key && left < right) {
--right;
}
if(array[right] < key) {
array[left] = array[right];
}
while(array[left] <= key && left < right) {
++left;
}
if(array[left] > key) {
array[right] = array[left];
}
}
array[left] = key;
return left;
}
测试代码:
public static void main(String[] args) {
int a[] = {1,8,2,4,5,6,7};
quickSort(a,0,6);
for(int i = 0; i <= 6; ++i) {
System.out.print(a[i]+ " ");
}
}
输出结果:
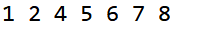
左右指针交换法
这个实现方法最能体现快速排序是一种交换排序的本质。举个例子,下面是以下标为1开始的数组nu[],l和r表示下标。
3,1,4,2,5
我们把最 左 边的数 3 作为基准,l=1,r=5。
- 先从r向l找比 3 小的数,找到了 2 ,停止遍历,此时r==4。
- 再从l向r找比 3 大的数,找到了 4 ,停止遍历,此时l==3。
- 交换nu[l]与nu[r]的值。
- 继续第1步操作,发现l == r == 3,交换基准与nu[l]的值,数组变为
2,1,3,4,5 - 此时,3的左边都比3小,3的右边都比3大。再让他左右两个区间重复上述操作,即可完成最终的排序。
是不是发现与挖坑法很像。其实说白了,二者的区别是:挖坑法是l和r任意一个满足条件就填坑,而左右指针交换法是l和r都满足条件的时候才填坑。
核心代码:
public int method2(int array[], int left, int right) {
int key = left;
while(left < right) {
while(array[right] >= array[key] && left < right) {
--right;
}
while(array[left] <= array[key] && left < right) {
++left;
}
swap(array, left, right);
}
swap(array, key, left);
return left;
}
测试代码:
public static void main(String[] args) {
int a[] = {1,8,2,4,5,6,7};
quickSort(a,0,6);
for(int i = 0; i <= 6; ++i) {
System.out.print(a[i]+ " ");
}
}
输出结果:
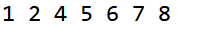
前后指针法
我们知道,对于单向链表,上面的两种方法是没法用的。
而前后指针法是左右指针法的变形,就可以用于对 链表 的快速排序。
怎么个变形法呢?就是让两个指针都从同一个方向出发了。
为了模拟链表的状态,我们假设这两个指针都从左边出发,执行以下步骤:
- 定义变量cur指向序列的开头,定义变量pre指向cur的前一个位置。
- 当array[cur] < key时,cur和pre同时往后走,如果array[cur]>key,cur往后走,pre留在大于key的数值前一个位置。
- 当array[cur]再次 < key时,交换array[cur]和array[pre]。
通俗一点就是,在没找到大于key值前,pre永远紧跟cur,遇到大的两者之间机会拉开差距,中间差的肯定是连续的大于key的值,当再次遇到小于key的值时,交换两个下标对应的值就好了。
如图所示:

注:以上解释内容与图片源自 该博客
核心代码
public static int method3(int array[], int left, int right) {
int key = array[right];
int cur = left;
int pre = cur - 1;
while(cur < right) {
if(array[cur] < key && ++pre != cur) {
swap(array, pre, cur);
}
++cur;
}
swap(array, ++pre, cur);
return pre;
}
测试代码:
public static void main(String[] args) {
int a[] = {1,8,2,4,5,6,7};
quickSort(a,0,6);
for(int i = 0; i <= 6; ++i) {
System.out.print(a[i]+ " ");
}
}
输出结果:
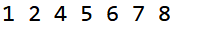
关于基准的选择
可以发现,在上述的三种实现方法的代码中,我选的基准都是最左边或最右边。
前两个代码,我选的是最左边,前后指针法我选的是最右边。这样选择是有原因的。
前后指针法基准的选择
前后指针法我是只在对链表排序的时候才会用,因为相对于前两种不太好写。因为链表没法随意的访问中间的值,最多访问个头和尾。而单向链表中两个数的关联只有一个next关系。因而我们遍历链表只能从头到尾遍历,这就决定了,基准取尾部是比较方便的选择。
可能我们会想,如果我一定要基准取头部呢?当然可以,首先看看这段代码:
while(cur < right) {//注意看这个判断条件,当cur==right的时候,结束循环
if(array[cur] < key && ++pre != cur) {
swap(array, pre, cur);
}
++cur;
}
swap(array, ++pre, cur);//结束循环后,无需判断,直接把基准交换到pre上去。
如果基准取尾,循环的最后一步一定是走到了基准本身,而++pre所在的位置恰好满足其左边都小于基准,右边大于基准,这样无需判断就可以直接交换pre和基准的值。
也就是说,其实前后指针法就是一直在维护一个区间(pre,cur),在这个区间内的所有数都比基准大。而我们维护的这个区间的过程,其实就是找cur的最终位置。 把基准设在最后面,这样当cur撞上最后一个数就正好完成了(pre,cur)区间的确定,直接把cur与++pre交换,就是快排的一次分治。
而如果把基准设在头部,又要面临一个问题,当cur走到了right还是比基准大的时候。这样如果要完成一次分治,就得把(pre,cur)区间全部前移一位,再把基准接在cur上。或者在链表中就是,删去第一个值,接在最后的一个值后面。
相对于直接把基准设在后面要麻烦一些。
- 注意:撞上这个词很重要,后面也会提到。
填坑法和左右指针交换法基准的选择
看看左右指针交换法的代码
public int method2(int array[], int left, int right) {
int key = left;
while(left < right) {
while(array[right] >= array[key] && left < right) {//先从右向左
--right;
}
while(array[left] <= array[key] && left < right) {
++left;
}
swap(array, left, right);
}
swap(array, key, left);
return left;
}
可以发现,基准选了最左边,循环先从右向左遍历。事实上,如果基准选了最右边,循环就应该从左向右遍历。这是因为左右指针交换法和挖坑法中,一次分治可以成功结束的标志就是left与right撞上后,将left上的值与基准交换,此时基准左边的都比它小,右边的都比他大。
也就是说,若基准选了最左边,left与right撞上的时候,left上的值必须要小于基准,如何确保账上的时候left上的值必须小于基准呢?是的,仔细分析代码就可以明白了,先从右向左遍历。基准选最右边的时候也是这个道理。
快速排序的优化
基准选择的优化
当区间本身是有序的时候,如果基准仍然去最左边或者最右边的话,每一次分治都会出现一种状况,就是基准的一边是空的,数全在另一边,而这时的时间复杂度为O(
)。因此,基准的选择有很多讲究。
(可能有人会问,之前不是说基准只能取最左边和最右边吗,为什么在这里又可以选别的了,其实这里是只选了别的把它与最左边或最右边的值交换,这样基准就仍在边界啦) 不,没有人会问。
常用的有两种优化
- 随机数法
顾名思义,就是用随机数筛出来一个基准。 - 三数取中法
我们找到最左边,最右边,最中间的三个数,把中位数找出来,作为基准。
小区间优化
因为递归是很耗时间的,所以如果区间很小的话,不如直接用直接插入排序好了。
(可能有人会问,为什么要用直接插入排序呢,因为直接插入排序在数组基本有序的时候会很快呀) 不,没有人会问。
都挺好实现的,想看看具体代码的请看 该博客
优化的选择排序-堆排序
我通过对 该博客 的学习,了解了堆的构建过程其实就是在不断的重复一个步骤。
比如大顶堆,就是把这个堆分成无数个小堆,在小堆中只有一个根和两个儿子,把这三个数中最大的数放在根上就好了。而如果合在一块整体来看,还要多考虑一点,那就是如果把根与左右儿子交换,会不会影响儿子与其子节点之间的秩序。
比如这个例子:

构建完堆后,对于每个小堆来说,根都是最大的数,合为一个整体后的根也将是这个堆中最大的数。我们把这个根取出来,作为已经排好序的数,在从剩下的数中找出最大值(没错,这里就是选择排序的思想),直到堆中没有数,该数组就完成了排序。
也可以换个角度这样理解:
堆的构造过程,其实就是让根不断的与其后代比较,使其最终放在合适的位置。 还是上面那个例子,与其看做是递归的维持所有节点的大顶堆结构,不如说是让4不断的向下寻找,当子节点小于4,根节点大于4的时候停下来。
关于后续的排序过程亦是如此,把最后一个叶子节点放在根上,在让其不断地向下寻找,找到一个合适的位置停下来,这就是堆排序的步骤。
当然,这样理解无法体现 堆排序的每个步骤都是为了找出一个有序的数 这个精髓所在,仅供参考。
核心代码:
public static void swap(int a[], int i, int j) {
if(i == j) {
return;
}
a[i] = a[i] ^ a[j];
a[j] = a[i] ^ a[j];
a[i] = a[i] ^ a[j];
}
public static void HeapAdjust(int a[], int i, int n) {//把大的提上去,把i上的数放到合适的位置
for(int k = 2 * i + 1; k < n; k = 2 * k + 1) {
if(k + 1 < n && a[k] < a[k+1]) {
++k;
}
if(a[k] > a[i]) {
swap(a, i, k);
} else {
break;
}
}
}
public static void HeapSort(int a[]) {
for(int i = a.length / 2 - 1; i >= 0; --i) {//从下往上构建堆
HeapAdjust(a, i, a.length);
}
for(int i = a.length - 1; i > 0; --i) {//不断的删去最大值,维护堆
swap(a, 0, i);
HeapAdjust(a, 0, i);
}
}
public static void main(String[] args) {
int a[] = {4,6,8,5,9};
HeapSort(a);
System.out.println(Arrays.toString(a));
}
输出结果:

优化的计数排序-桶排序
该博客 有桶排序实现的gif图。
实现代码:
public static void bucketSort(int a[]) {
int maxx = a[0];
int minn = a[0];
for(int i = 0; i < a.length; ++i) {
maxx = Math.max(maxx, a[i]);
minn = Math.min(minn, a[i]);
}
int bucketNum = (maxx - minn) / a.length + 1;
ArrayList<ArrayList<Integer>> bucketArray = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; ++i) {
bucketArray.add(new ArrayList<Integer>());
}
for(int i = 0; i < a.length; ++i) {
bucketArray.get((a[i] - minn) / a.length).add(a[i]);
}
for(int i = 0; i < bucketNum; ++i) {
Collections.sort(bucketArray.get(i));
}
System.out.println(bucketArray.toString());
}
public static void main(String[] args) {
int[] a = {244, 167, 1234, 321, 29, 98, 1444, 111, 99, 6};
bucketSort(a);
}
优化的计数排序-基数排序
- 思想:基数排序就是在计数排序的基础上引入了一个概念,那就是对每一位进行排序。
比如3,32,321 这个序列。
- 我们先按个位进行计数排序,则结果是321, 32, 3。
- 在第1步的基础上,再按十位进行排序,则结果是3,321,32。
- 在第2步的基础上,按百位进行排序,则结果是3,32,321。完成排序。
核心代码:
public static void radixSort(int a[]) {
int maxx = a[0];
int temp[] = new int[a.length];
int radix[] = new int[10];
for(int i = 0; i < a.length; ++i) {
maxx = Math.max(a[i], maxx);
}
int d = 1;
while(maxx > 0) {
maxx /= 10;
++d;
}
int pos = 1;
while(d > 0) {
--d;
for(int i = 0; i < 10; ++i) {
radix[i] = 0;
}
for(int i = 0; i < a.length; ++i) {
int x = (a[i] / pos) % 10;
++radix[x];
}
for(int i = 1; i < 10; ++i) {//计数排序
radix[i] += radix[i-1];
}
for(int i = a.length - 1; i >= 0; --i) {//基数排序一定要保持其稳定性
//比如12,11这两个数,如果在对个位进行排序后不保持其稳定,
//再在对十位进行排序时,可能会出现11在12后面的情况
int x = (a[i] / pos) % 10;
temp[radix[x] - 1] = a[i];
--radix[x];
}
for(int i = 0; i < a.length; ++i) {
a[i] = temp[i];
}
pos *= 10;
}
System.out.println(Arrays.toString(a));
}
测试代码:
public static void main(String[] args) {
int[] a = {244, 167, 1234, 321, 29, 98, 1444, 111, 99, 6};
radixSort(a);
}
输出结果:

归并排序
归并排序从小到大排序:首先让数组中的每一个数单独成为长度为1的区间,然后两两一组有序合并,得到长度为2的有序区间,依次进行,直到合成整个区间。
归并排序的 关键操作 在于将 两个有序的区间 合为一个区间。
建议大家做做 这道题 ,有助于我们更深刻的理解归并排序。
gif图实现过程请看该博客 。
核心代码:
- 归并操作:
public static void merge(int a[], int left, int mid, int right, int temp[]) {
int i = left, j = mid+1, k = 0;
while(i <= mid && j <= right) {
if(a[i] < a[j]) temp[k++] = a[i++];
else temp[k++] = a[j++];
}
while(i <= mid) temp[k++] = a[i++];
while(j <= right) temp[k++] = a[j++];
for(i = 0; i < k; ++i) {
a[left+i] = temp[i];
}
}
- 递归版
public static void mergeSort(int a[], int left, int right, int temp[]) {
if(left == right) return;
int mid = (left + right) / 2;//注意,因为这里是向下取整,所以分治的时候,右区间应为mid+1
//System.out.println("left: "+left +" right: "+right+" mid: "+ mid);
mergeSort(a, left, mid, temp);
mergeSort(a, mid + 1, right, temp);
merge(a, left, mid, right,temp);
}
- 迭代版
public static void mergeSort2(int a[], int temp[]) {//非迭代需要注意保证每个区间合并之前都是有序的
for(int len = 1; len < a.length; len<<=1) {
for(int i = 0; i + len < a.length; i += 2 * len) {
int left = i;
int right = Math.min(i + 2* len, a.length) - 1;
int mid = i + len - 1;
merge(a, left, mid, right, temp);
}
//System.out.println(Arrays.toString(a));
}
}
测试代码:
}
public static void main(String[] args) {
int[] a = {244, 167, 1234, 321, 29, 98, 1444, 111, 99, 6};
int temp[] = new int[a.length];
mergeSort(a, 0, a.length - 1, temp);
System.out.println(Arrays.toString(a));
}
输出结果: