#################LSA和LSI(start)###################
根据wikipedia:
https://en.wikipedia.org/wiki/Latent_semantic_analysis
可以知道文中提到的LSI就是LSA
通常称为LSA,因为维基百科中提到:it is sometimes called latent semantic indexing (LSI).LSA的文档里面則以称为LSI为主.
所以百度上的(包括本文在內)LSA就是LSI,LSI就是LSA
#################LSA和LSI(end)###################\
##################LDA发展史(start)#####################
原文:《Latent Dirichlet Allocation》
原文作者的代码:https://github.com/blei-lab/lda-c
Dirichlet分布是一种多维的
分布
主題模型演變順序:LSA->pLSA->LDA
目的:對文檔主題進行聚類,这里可以理解为对几个.txt文本聚类,一个.txt文本在该算法中,被处理为一个无序的词序列
论文分别是:
LSA:
《Indexing by latent semantic analysis》-1990
pLSA:
《Probabilistic Latent Semantic Analysis》 1999
LDA:
《Latent Dirichlet Allocation》-2003
注意:
必須從LSA開始理解,否則看網上各路博客,
每個人理解程度不同,還有亂寫的,是看不懂的。
##################发展史(end)#####################\
################解释文章中的一些词汇(start)################################\
首先解釋为啥取名叫Latent Dirichlet allocation:
因为这个事情是以前发生过类似的,过去的先验概率受到现在类似的事件的影响,所以说是“潜在的”(latent),我们常常说“横穿马路有潜在的危险”,是因为知道不看红绿灯很可能会车祸,如果我们再来一次,那么显然会增加“乱穿马路会车祸”这个事情的概率.
概率具体增加多少?我们就要用到“Dirichlet Distribution”,所以
整个名字中只有“Dirichlet”这个词语带有严谨的数学含义,剩余两个词是为了形象起见,作者加上去的。
"allocation"这个词语可以理解为,现在发生的类似的事件会allocate到概率计算的分子和分母中。
singular value decomposition:SVD分解,效果上类似于PCA之类的降维技术
document:就是一个txt文件,也就是一个词序列
corpus:包含一堆txt文件的文件夹,也就是很多个词序列
information Retrieval:信息检索,你可以理解为在数据库里面搜东西
exchangeability:这个是在提词袋模型的时候提出来的,意思是在对文档进行建模时,假设词的顺序是可以被忽略的,也就是說詞袋模型中的不同詞語之間的順序是exchangeable(可交換的).
https://zhuanlan.zhihu.com/p/32829048
注意上面的log在不同的開源包中使用了不同的底數,sklearn使用的就是ln來計算
simplex:就是一个理论层,不是一个很严谨的术语,就是虚晃一指。
比如说:“我要去吃饭。”你要去哪里吃饭?你要吃什么?你都没讲清楚,所以这里的“吃饭”就是虚晃一指。
################解释文章中的一些词汇(start)################################
##########################
下面开始分析论文《Latent Dirichlet Allocation》-2003
该文主要内容如下:
由上可知:
整篇文章的重点是第2,3,5部分,下面依次讲解:
表示一篇文档
词典的下标是:
算法大意如下:
1.Choose N~Poisson(
)
2.Choose
~Dir(
)
3.For each of the N words
:
(a)Choose a topic
~Multinomial(
)
(b)Choose a word
from
,a multinomial probability conditioned on the topic
然后文章介绍了三个假设,对于每个假设,我们先抄引文,然后解释是什么意思.
第一个假设:
First, the dimensionality k of the Dirichlet distribution (and thus the dimensionality
of the topic variable z) is assumed known and fixed.
翻译过来就是:假设文章聚类成几类是知道的。
讲人话:其实我们也不知道要聚类成几类,也就是k等于几我们也不知道,你随便设一个吧。
可以类比想象下,kmeans我们调包前总是需要设定我们要聚类成几类。
第二个假设:
Second, the word probabilities are parameter-
ized by a k×V matrix
where
=
, which for now we treat as a fixed quantity
that is to be estimated.
什么意思呢?文章中某个"词"的概率被一个矩阵
给参数化了。
这里的k是聚类中心,这里的V是上面提到的某个词在词典中的的下标上限
我们可以回忆下,psla在进行svd分解时,最右侧的一个矩阵也是k·V维。
第三个假设:
Finally, the Poisson assumption is not critical to anything that follows and
more realistic document length distributions can be used as needed.
讲人话:作者自己也不知道为啥服从泊松分布,所以找借口说"is not critical to",意思是:他自己也不懂,但是不好意思承认自己讲话不严谨。
下面开始介绍解释LDA的公式都是啥意思.
这个东西是Dirichlet分布(
分布的多维形式)的表达式,
注意,这里的
本身就是一个概率,所以这个式子是在表达“抽中某个文档的概率值”的概率大小。网上有个精简的说法,叫:概率的概率。
对比
,我们再来回忆一下plsa在svd分解成3个矩阵后,最左侧的一个矩阵是什么?
☆☆☆
另外注意,这个
不是条件概率,这里的“|”只是表达后面有一个参数,不要套用P(AB)=P(A)·P(B)来试图推导。
这个东西需要非常注意,否则后面的公式就没法看了。
那么什么时候“|”表示条件概率?
后面会一一指出。
☆☆☆
这里的
念作"Gamma"
而
念作"gamma"两者发音一致,都是希腊字母.
计算实例:
看完式(1),来看式(2):
注意这个式子中:
非条件概率
非条件概率,根据过往经验,选择主题分布向量
的概率
是条件概率,根据文章的概率分布选择主题
的概率
是条件概率,根据第
个主题中选择
的概率
条件概率的意思就是"|“右侧的因子是事件,可以通过乘以另外一个概率来抵消。
非条件概率的意思就是”|"右侧的因子是参数,不能通过乘以另外一个概率来抵消。
由于该论文认为:一篇文章是包含多个主题的。
所以
是k维度的,就是这个k维度的向量中,每个维度塞进去一个概率值,这个概率是k个主题中,其中一个主题的分布概率大小。
再来回顾下Dirichlet函数,我们知道,
分布只有一个维度输入,得到一个函数值,而Dirichlet函数相当于多维的
分布,也就是说,在一篇文章中,k个主题的分布概率被输入Dirichlet函数,得到这个“k维主题分布概率”向量的概率值.
☆☆☆
整个式子什么意思呢?
式(2)的等式右边=选择某种主题分布的概率·
·根据主题分布选择某个主题的概率·根据某个主题选择某个词的概率
☆☆☆
所以这个模型在模仿人写文章时的顺序。
“主题”的意思:某个文章中的“段落大意”
“根据主题分布选择某个主题的概率”啥意思呢:
举例:
一篇文章怎么写呢?
第一段写,爸爸平时怎么怎么滴
第二段写,妈妈怎么怎么滴
第三段写,爸爸和妈妈怎么认识滴
选择某个主题就是这篇文章的每一段的“段落大意”是啥。
再次注意,这个论文不是“把文章归类到某个主题”,而是任何一个文章都具备“很多个主题”
一句话解释啥意思,式(2)计算的是:
选择某种主题分布然后最终生成整篇文章的概率。
注意这个式子其实是不合理的。
由于这个式子的不合理性,也导致了后面变分EM算法的出现,什么地方不合理呢?这个
和
其实是有关联的,
文章中的专业说法:
和
之间有耦合性,
工科数学的说法:“
和
互相不独立”,
说人话就是:“
和
有一腿”
“变分EM”算法啥意思,就是把
和
撇清关系后,然后使用EM算法迭代收敛。
**关键性问题来了,这个论文假设一个文章(论文中,document定义为一个word sequence)包含多个主题,那说好的聚类呢?如何把这个原理用来文章内容聚类?
回到Dirichlet分布,上面提到,这个式子的目的是计算“根据某个主题分布生成某个文档的概率”
也就是说,目标函数是求得,哪个主题分布,能生成某个文章的概率最大,我们就认为,这个文章的各个段落大意,满足这个主题分布。
这样说在理解上又进一步了,但是依然不清晰,回到式(2),其中有一项是:
,
这个意思是:
根据"假设满足"的主题
,我们从训练集中选择一个单词
,来计算概率
如果确定最终得到的
是最大的,那么我们就认为这个假设的“主题分布
”就是我们想要的聚类分布,聚类算法结束。
**
怎么理解文章中给出的示意图呢?
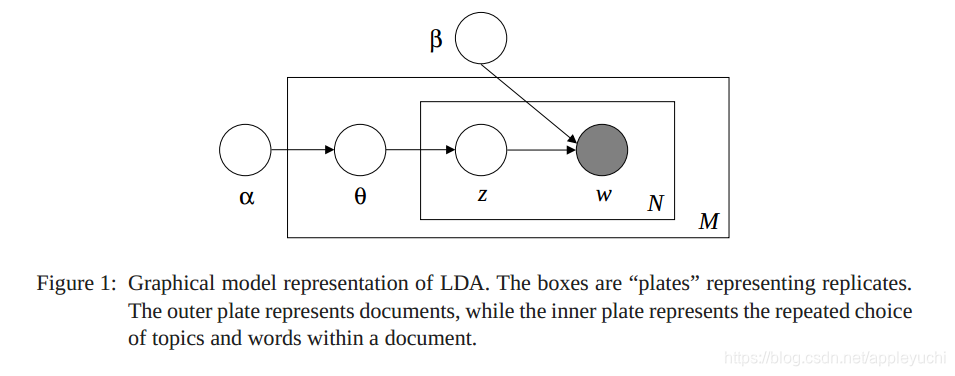
图中方框外侧就是概率P中“|”的右侧
图中方框内侧就是概率P中“|”的左侧,
例如
中,
在“|”的右侧,对应图中的方框外侧
在“|”的左侧,对应图中的方框内侧
根据上面的那个模型图片,我们大概也能想到
和
是有关联的,作者在论文的这个部分着重处理这个问题。
这个"变分EM"算法想要完全看懂的话,需要把论文后面的Appendix中所有公式推导一遍,没必要,这里就说个大概。
算法大意是:
试图让
与
撇清关系,然后使用EM算法。
假定所有的隐变量(
)都是服从各自的独立分布的,然后搞出来一个KL散度,KL散度的意思是希望近似处理的前后差别不要太大。
所以由原来的
改为折腾
KL散度是两个不同概率分布的差异的衡量指标:
也就是把EM的E步中的目标函数换了下,
其余不变,依然是EM算法的原理。
好了,一句话概括这个算法:
该算法中,每个document都是一个词序列。
聚类思想是:
每次迭代时选择的一个k维(k需要自己指定)主题分布,选择一个词,根据式(2)来获取最大的
.
复习时需要记住式(2),并且能说出“文章由多个主题组成,主题由多个词组成”的思想
因为作者建模不合理,算法没法直接落地,
硬着头皮搞出来个"变分EM算法"来收拾烂摊子。