Numpy
| ID | Price | Area | Bedroom | Basement |
|---|---|---|---|---|
| 1 | 200 | 105 | 3 | false |
| 2 | 165 | 80 | 2 | false |
| 3 | 184.5 | 120 | 2 | false |
| 4 | 116 | 70.8 | 1 | false |
| 5 | 270 | 150 | 4 | true |
ID代表标签一般标签是独一无二的 机器学习一般分为两类线性与非线性(分类) 但是生活中的数据往往不是所有的数据都有会有属性的数据缺失 对于这种情况通常我们会使用均值或者近似值代替
以上方数据为例 建立数据集的数据矩阵 使用不同方法处理
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])#建立数据矩阵
row = 0 #计算行的变量
for line in data:
row += 1
print(row)
print(data.size) #计算全部数据量
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])#建立数据矩阵
row = 0 #计算行的变量
for line in data:
row += 1
print(print(data[0,3]))
print(print(data[0,4]))
print(data) 
数据统计
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])#建立数据矩阵
coll = []
for row in data:
coll.append(row[0,1])
print(np.sum(coll))
print(np.mean(coll))
print(np.std(coll))
print(np.var(coll)) 
coll定义一个空的数据集 使用for填充数据 依次计算 和、均值、标准差、方差

图形化数据处理——Matplotlib
import numpy as np
import pylab
import scipy.stats as stats
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])#建立数据矩阵
coll = []
for row in data:
coll.append(row[0,1])
stats.probplot(coll,plot=pylab)
pylab.show() probplot:它主要是直观的表示观测与预测值之间的差异。一般我们所取得数量性状数据都为正态分布数据。预测的线是一条从原点出发的45度角的虚线,事假观测值是实心点。
probplot:它主要是直观的表示观测与预测值之间的差异。一般我们所取得数量性状数据都为正态分布数据。预测的线是一条从原点出发的45度角的虚线,事假观测值是实心点。
import pandas as pd
import matplotlib.pyplot as plot
rocksVMines = pd.DataFrame([[1,200,105,3,False],[2,165,80,2,False],[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
dataRow1 = rocksVMines.iloc[1,0:3] #取1-4列的第一行
dataRow2 = rocksVMines.iloc[2,0:3]
plot.scatter(dataRow1,dataRow2)
plot.xlabel("Attribute1")
plot.ylabel("Attribute2")
plot.show()
dataRow3 = rocksVMines.iloc[3,0:3]
plot.scatter(dataRow2,dataRow3)
plot.xlabel("Attribute2")
plot.ylabel("Attribute3")
plot.show()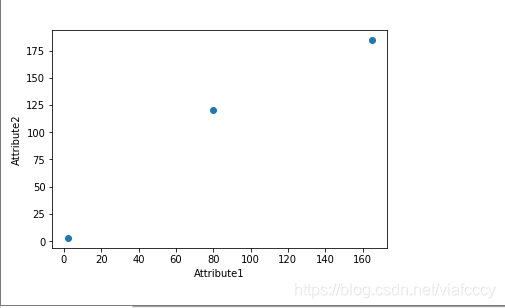

选取不同目标行中不同的属性,可以很好的衡量并比较两行之间的属性关系以及属性之间的相关性,构成相互关系图
如果数据较多会随着数据的增加呈现一种正态分布
使用csv的数据集
这里我们使用经典的iris数据集
数据集下载地址:
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("C://Users/Administrator/Desktop/iris.data.csv")
dataFile = pd.read_csv(filePath,header=None,prefix="V")
dataRow1 = dataFile.iloc[148,0:3] #取148行的前3列行元素 这里涉及切片从第一个开始取2个元素出来
dataRow2 = dataFile.iloc[149,0:3]
plot.scatter(dataRow1,dataRow2)
plot.xlabel("Attribute1")
plot.ylabel("Attribute2")
plot.show() 
下面进行同一属性进行分析:
偏离程度
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("C://Users/Administrator/Desktop/iris.data.csv")
dataFile = pd.read_csv(filePath,header = None,prefix="V")
target = []
for i in range(149):
if dataFile.iat[i,1] >= 3:
target.append(1.0)
else:
target.append(0.0)
dataRow = dataFile.iloc[0:149,1]
plot.scatter(dataRow, target)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
离散程度:
import pandas as pd
import matplotlib.pyplot as plot
import random
filePath = ("C://Users/Administrator/Desktop/iris.data.csv")
dataFile = pd.read_csv(filePath,header = None,prefix="V")
target = []
for i in range(149):
if dataFile.iat[i,1] >= 3:
target.append(1.0 + random.uniform(-0.3,0.3))
else:
target.append(0.0 + random.uniform(-0.3,0.3))
dataRow = dataFile.iloc[0:149,1]
plot.scatter(dataRow, target,alpha = 0.5,s = 100)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
相似度计算
1. 欧几里得距离
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
注意事项:
a.因为计算是基于各维度特征的绝对数值,所以欧氏度量需要保证各维度指标在相同的刻度级别,比如对身高(cm)和体重(kg)两个单位不同的指标使用欧式距离可能使结果失效。
b.欧几里得距离是数据上的直观体现,看似简单,但在处理一些受主观影响很大的评分数据时,效果则不太明显;比如,U1对Item1,Item2 分别给出了2分,4分的评价;U2 则给出了4分,8分的评分。通过分数可以大概看出,两位用户褒Item2 ,贬Item1,也许是性格问题,U1 打分更保守点,评分偏低,U2则更粗放一点,分值略高。在逻辑上,是可以给出两用户兴趣相似度很高的结论。如果此时用欧式距离来处理,得到的结果却不尽如人意。即评价者的评价相对于平均水平偏离很大的时候欧几里德距离不能很好的揭示出真实的相似度。
2. 皮尔逊相关系数
Pearson 相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但其数值上受量纲的影响很大,不能简单地从协方差的数值大小给出变量相关程度的判断。为了消除这种量纲的影响,于是就有了相关系数的概念。
当两个变量的方差都不为零时,相关系数才有意义,相关系数的取值范围为[-1,1]。《数据挖掘导论》中给了一个很形象的图来说明相关度大小与相关系数之间的联系:
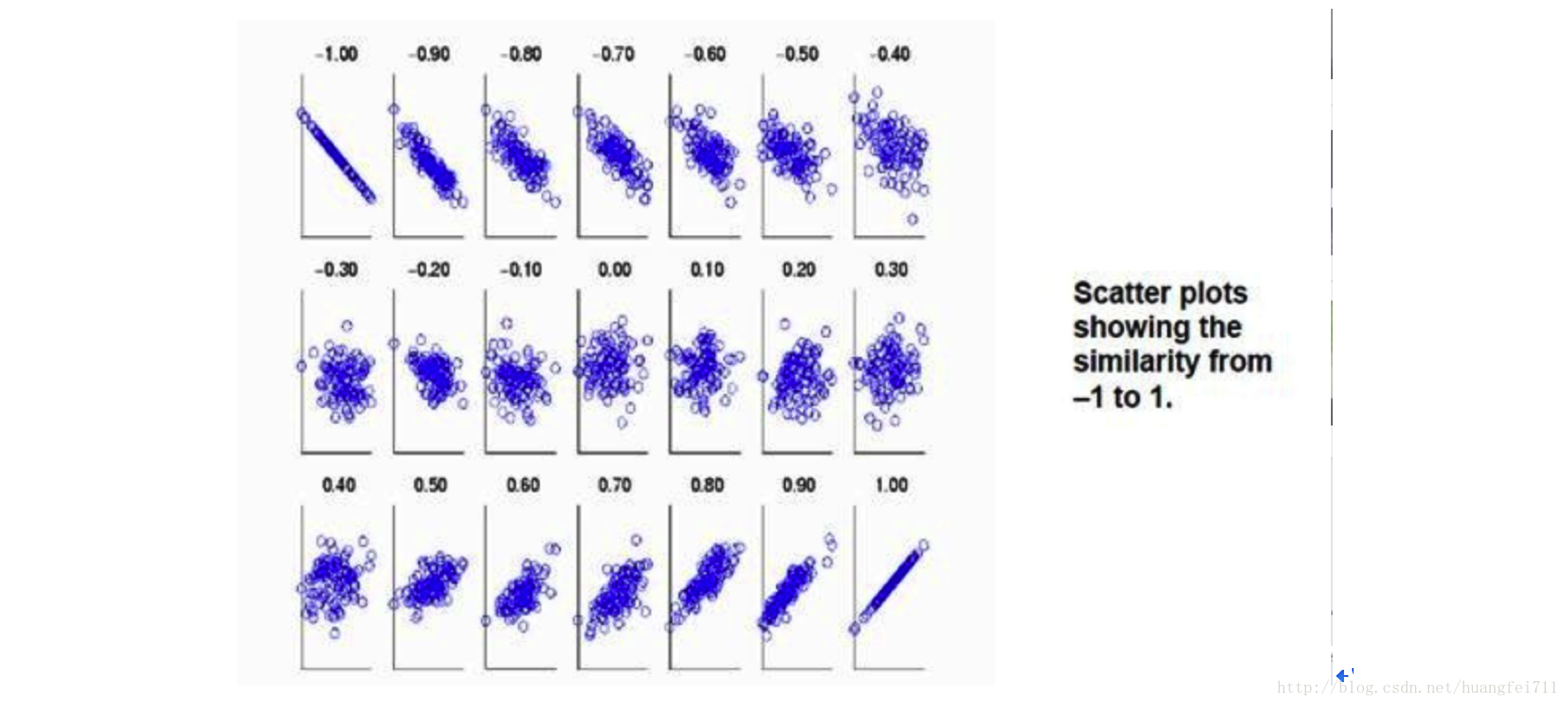
由上图可以总结,当相关系数为1时,成为完全正相关;当相关系数为-1时,成为完全负相关;相关系数的绝对值越大,相关性越强;相关系数越接近于0,相关度越弱。
皮尔逊相关的约束条件:
1 两个变量间有线性关系
2 变量是连续变量
3 变量均符合正态分布,且二元分布也符合正态分布
4 两变量独立
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性.
适用范围
适用于A的评价普遍高于B的评价
3. 余弦相似度
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
另外:余弦距离使用两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
借助三维坐标系来看下欧氏距离和余弦距离的区别:

正因为余弦相似度在数值上的不敏感,会导致这样一种情况存在:
用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
那么是否可以在(用户-商品-行为数值)矩阵的基础上使用调整余弦相似度计算呢?从算法原理分析,复杂度虽然增加了,但是应该比普通余弦夹角算法要强。
“判断两段文本的语义相似度”的事情,实验中用doc2vec做文本向量化,用余弦值衡量文本相似度。
为什么选用余弦?
如向量的维度是3,有三段文本a、b、c,文本向量化之后的结果假如如下:a=(1,0,0)、b=(0,1,0)、c=(10,0,0)。
我们知道doc2vec的每一个维度都代表一个特征,观察向量的数字,主观看来a和c说的意思应该相似,阐述的都是第一个维度上的含义,a和b语义应该不相似。那么如果用欧式距离计算相似度,a和b的相似度就比a和c的相似度高,而如果用余弦计算,则答案反之。
那么欧式距离和余弦相似度的区别是什么呢?
余弦相似度衡量的是维度间取值方向的一致性,注重维度之间的差异,不注重数值上的差异,而欧氏度量的正是数值上的差异性。
那么欧式距离和余弦相似度的应用场景是什么呢
以下场景案例是从网上摘抄的。
-
如某T恤从100块降到了50块(A(100,50)),某西装从1000块降到了500块(B(1000,500)),那么T恤和西装都是降价了50%,两者的价格变动趋势一致,可以用余弦相似度衡量,即两者有很高的变化趋势相似度,但是从商品价格本身的角度来说,两者相差了好几百块的差距,欧氏距离较大,即两者有较低的价格相似度。
-
如果要对电子商务用户做聚类,区分高价值用户和低价值用户,用消费次数和平均消费额,这个时候用余弦夹角是不恰当的,因为它会将(2,10)和(10,50)的用户算成相似用户,但显然后者的价值高得多,因为这个时候需要注重数值上的差异,而不是维度之间的差异。
-
两用户只对两件商品评分,向量分别为(3,3)和(5,5),显然这两个用户对两件商品的偏好是一样的,但是欧式距离给出的相似度显然没有余弦值合理。
4. Tanimoto系数(广义Jaccard相似系数)
定义:广义Jaccard相似度,元素的取值可以是实数。又叫作谷本系数
关系:如果我们的x,y都是二值向量,那么Tanimoto系数就等同Jaccard距离
应用场景:比较文本相似度,用于文本查重与去重;计算对象间距离,用于数据聚类等。

数据的统计学可视化
数据的四分位

import pandas as pd
import matplotlib.pyplot as plot
from pylab import *
filePath = ("C://Users/Administrator/Desktop/iris.data.csv")
dataFile = pd.read_csv(filePath,header=None,prefix="V")
print(dataFile.head())
print(dataFile.tail())
summary = dataFile.describe()
print(summary)
array = dataFile.iloc[:,0:3].values
boxplot(array)
plot.xlabel("Attribute")
plot.ylabel("Score")
plot.show()


数据标准化
min-max标准化(Min-max normalization)/0-1标准化(0-1 normalization)/线性函数归一化/离差标准化
是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
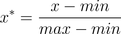
其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
x* = x* * 2 -1
或者进行一个近似
x* = (x - x_mean)/(x_max - x_min), x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
z-score 标准化(zero-mean normalization)
最常见的标准化方法就是Z标准化,也是SPSS中最为常用的标准化方法,spss默认的标准化方法就是z-score标准化。
也叫标准差标准化,这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,其转化函数为:
x* = (x - μ ) / σ
其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。、
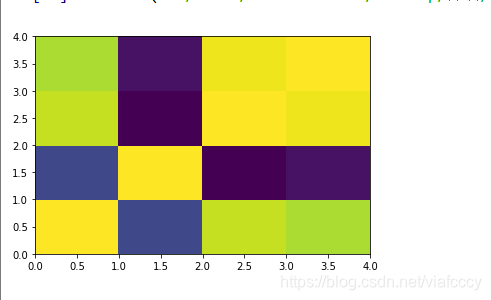
热点图——属性相关度检测
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("C://Users/Administrator/Desktop/iris.data.csv")
dataFile = pd.read_csv(filePath,header=None,prefix="V")
summary = dataFile.describe()
corMat = pd.DataFrame(dataFile.iloc[0:149,0:4].corr())
plot.pcolor(corMat)
plot.show()