关于hadoop的名词解释
(1)Hadoop:Apache开源的分布式框架。
(2)HDFS:Hadoop的分布式文件系统。
(3)NameNode:Hadoop HDFS元数据主节点服务器,负责保存DataNode 文件存储元数据信息,这个服务器是单点的。
(4)JobTracker:Hadoop的Map/Reduce调度器,负责与TaskTracker通信分配计算任务并跟踪任务进度,这个服务器也是单点的。
(5)DataNode:Hadoop数据节点,负责存储数据。
(6)TaskTracker:Hadoop调度程序,负责Map,Reduce任务的启动和执行。
注:Namenode记录着每个文件中各个块所在的数据节点的位置信息
实验环境
安装前,3台虚拟机IP及机器名称如下:
主机名 IP地址 角色
ldy01.cn 192.168.202.1 NameNode
ldy02.cn 192.168.202.2 DataNode1
ldy03.cn 192.168.202.3 DataNode2
第一步:
编辑hosts文件;
[root@ldy01 ~]# vim /etc/hosts
[root@ldy02 ~]# vim /etc/hosts
[root@ldy03 ~]# vim /etc/hosts
192.168.202.1 ldy01.cn
192.168.202.2 ldy02.cn
192.168.202.3 ldy03.cn

把下载好的hadoop和jdk包上传到/mnt目录下

3台机器设置免密码登录:3台机器一样的操作
ssh-keygen 一直回车
[hadoop@ldy01 hadoop]$ ssh-copy-id [email protected]
[hadoop@ldy01 hadoop]$ ssh-copy-id [email protected]



关于ldy01也要进行发布要不然后面启动服务失败
[hadoop@ldy01 sbin]$ ssh-copy-id 192.168.202.1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
[email protected]'s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '192.168.202.1'"
and check to make sure that only the key(s) you wanted were added.
java环境搭建:
第一步首先解压文件到/usr/java下
[root@ldy01 mnt]# tar -xvf jdk-8u201-linux-x64.tar.gz -C /usr/java
[root@ldy01 mnt]# vi /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_201
JRE_HOME=/usr/java/jdk1.8.0_201/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH

然后是配置文件生效一下
[root@ldy01 mnt]# source /etc/profile
然后测试一下java版本如下为成功配置:
3台都要实现配置java环境
[root@ldy01 mnt]# java -version



创建一个hadoop用户,指定他的用户id为8000



并为3台服务器配置hadoop用户密码为123456



在ldy01上的配置如下:
[root@ldy01 ~]# mkdir -p /home/hadoop/dfs/name
[root@ldy01 ~]# mkdir -p /home/hadoop/dfs/data
[root@ldy01 ~]# mkdir -p /home/hadoop/dfs/tmp
[root@ldy01 ~]# cd /mnt/
[root@ldy01 mnt]# ls
cdrom hadoop-3.1.2.tar.gz jdk1.8.0_201 jdk-8u201-linux-x64.tar.gz l
[root@ldy01 mnt]# mv hadoop-3.1.2.tar.gz /home/hadoop/ 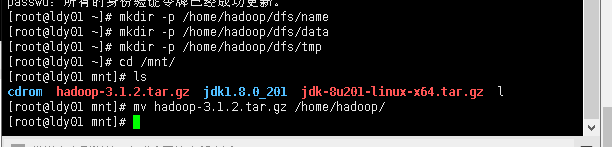
切换到hadoop用户上。可以看到家目录下有我们的hadoop软件包,然后我们把他解压
[root@ldy01 mnt]# su - hadoop
[hadoop@ldy01 ~]$ ls
dfs hadoop-3.1.2.tar.gz
[hadoop@ldy01 ~]$ tar zxf hadoop-3.1.2.tar.gz

[hadoop@ldy01 hadoop]$ vim hadoop-env.sh
配置文件做如下修改:
export JAVA_HOME=/usr/java/jdk1.8.0_201

[hadoop@ldy01 hadoop]$ vim workers

vim core-site.xml //指定访问hadoop web界面访问路径
添加一下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ldy01.cn:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value> //
</property>
</configuration>

创建刚才配置文件上面的目录hadoop.tmp.dir
[hadoop@ldy01 hadoop]$ mkdir -p /home/hadoop/tmp
分布式存储的配置文件:
[hadoop@ldy01 hadoop]$ vim hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ldy01.cn:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>

[hadoop@ldy01 hadoop]$ vim mapred-site.xml 由于hadoop使用了yarn框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>ldy01.cn:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ldy01.cn:19888</value>
</property>
</configuration>

[hadoop@ldy01 hadoop]$ vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>ldy01.cn:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>ldy01.cn:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>ldy01.cn:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>ldy01.cn:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>ldy01.cn:8088</value>
</property>
</configuration>


其他俩台服务器直接scp上传数据,以hadoop用户上传
[hadoop@ldy01 hadoop]$ scp -r /home/hadoop/hadoop-3.1.2 [email protected]:~/
[hadoop@ldy01 hadoop]$ scp -r /home/hadoop/hadoop-3.1.2 [email protected]:~/
![]()

在ldy02和ldy03上同时创建文件夹并且赋予hadoop权限
[root@ldy03 ~]# ls /home/hadoop/
[root@ldy03 ~]# mkdir -p /home/hadoop/dfs/name
[root@ldy03 ~]# mkdir -p /home/hadoop/dfs/data
[root@ldy03 ~]# mkdir -p /home/hadoop/dfs/tmp
[root@ldy03 ~]# mkdir -p /home/hadoop/tmp
[root@ldy03 ~]# chown hadoop.hadoop -R /home/hadoop/dfs/name/ /home/hadoop/dfs/data/ /home/hadoop/dfs/tmp/
[root@ldy03 ~]# chown hadoop.hadoop -R /home/hadoop/tmp/


因为还有一个dfs目录没权限,索性直接把hadoop目录下所有目录文件都赋予hadoop用户
[root@ldy02 ~]# chown hadoop.hadoop -R /home/hadoop/
[root@ldy03 ~]# chown hadoop.hadoop -R /home/hadoop/


对命名空间格式化
![]()

[hadoop@ldy01 bin]$ echo $?
如果看到是1说明我们的配置有问题

java报错了:

问题是权限问题

解决方案是:
[root@ldy01 hadoop]# chown hadoop.hadoop -R /home/hadoop/
[root@ldy01 hadoop]# 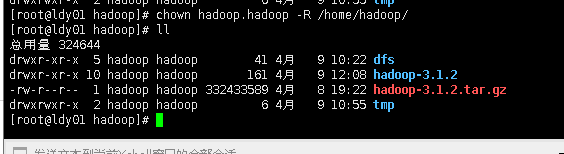
然后我们切换回hadoop用户去格式化
[root@ldy01 hadoop]# su hadoop
[hadoop@ldy01 ~]$ cd /home/hadoop/hadoop-3.1.2/bin/
[hadoop@ldy01 bin]$ ./hdfs namenode -format
我们看到再次echo $?输出的是0

说明对了
[hadoop@ldy01 hadoop-3.1.2]$ cd sbin/
[hadoop@ldy01 sbin]$ ./start-dfs.sh

我们查看namenode的进程已经启动。
[hadoop@ldy01 sbin]$ ps -ef | grep namenode

我们去ldy02和ldy03去查看datanode服务是否启动
[hadoop@ldy02 root]$ ps -ef | grep datanode

[hadoop@ldy01 sbin]$ ./start-yarn.sh

我们可以在ldy01上看到
[hadoop@ldy01 sbin]$ ps -ef | grep nodemanager

[hadoop@ldy02 root]$ ps -ef | grep nodemanager


生成一个报表:有节点各种参数
[hadoop@ldy01 hadoop-3.1.2]$ cd bin/
[hadoop@ldy01 bin]$ ls
container-executor hadoop.cmd hdfs.cmd mapred.cmd yarn
hadoop hdfs mapred test-container-executor yarn.cmd
[hadoop@ldy01 bin]$ ./hdfs dfsadmin -report



[hadoop@ldy01 bin]$ ./hdfs fsck / -files -blocks
查看块元素的组成;
搭建Hadoop进行8088端口访问;

可以查看节点信息
