集群节点类型
Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的MapReduce。
MapReduce的作业主要包括:(1)从磁盘或从网络读取数据,即IO密集工作;(2)计算数据,即CPU密集工作。
一个基本的Hadoop集群中的节点主要有:
NameNode名称节点(Master Node主节点):负责协调集群中的数据存储
DataNode数据节点(Slave Node从节点):存储被拆分的数据块
JobTracker:协调数据计算任务
TaskTracker:负责执行由JobTracker指派的任务
SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
集群规模
Hadoop集群规模可大可小,初始可以从一个较小规模的集群开始,然后规模随着存储器和计算需求的扩大而扩大。
对于一个小的集群,NameNode和JobTracker运行在单个节点上通常是可以接受的。但是,随着集群和存储在HDFS中的文件数量的增加,名称节点需要更多的主存,这时,NameNode和JobTracker就需要运行在不同的节点上。
SecondaryNameNode(第二名称节点)会和名称节点可以运行在相同的机器上,但是,由于SecondaryNameNode和NameNode几乎具有相同的主存需求,因此,二者最好运行在不同节点上
集群硬件配置
在集群中,大部分的机器设备是作为Datanode和TaskTracker工作的Datanode/TaskTracker的硬件规格可以采用以下方案:
4个磁盘驱动器(单盘1-2T),支持JBOD(Just a Bunch Of Disks,磁盘簇)
2个4核CPU,至少2-2.5GHz
16-24GB内存
千兆以太网
NameNode提供整个HDFS文件系统的NameSpace(命名空间)管理、块管理等所有服务,因此需要更多的RAM,与集群中的数据块数量相对应,并且需要优化RAM的内存通道带宽,采用双通道或三通道以上内存。硬件规格可以采用以下方案:
8-12个磁盘驱动器(单盘1-2T)
2个4核/8核CPU
16-72GB内存
千兆/万兆以太网
SecondaryNameNode在小型集群中可以和NameNode共用一台机器,较大的群集可以采用与NameNode相同的硬件
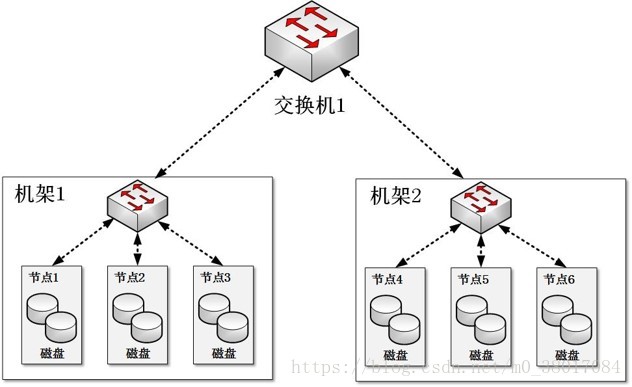
集群网络拓扑
普通的Hadoop集群结构由一个两阶网络构成
每个机架(Rack)有30-40个服务器,配置一个1GB的交换机,并向上传输到一个核心交换机或者路由器(1GB或以上)
在相同的机架中的节点间的带宽的总和,要大于不同机架间的节点间的带宽总和
集群的建立与安装
采购好相关的硬件设备后,就可以把硬件装入机架,安装并运行Hadoop
安装Hadoop有多种方法:(1)手动安装(2)自动化安装
为了缓解安装和维护每个节点上相同的软件的负担,可以使用一个自动化方法实现完全自动化安装,比如Red Hat Linux’ Kickstart、Debian或者Docker
自动化安装部署工具,会通过记录在安装过程中对于各个选项的回答来完成自动化安装过程。
集群基准测试
如何判断一个Hadoop集群是否已经正确安装?可以运行基准测试
Hadoop自带有一些基准测试程序,被打包在测试程序JAR文件中
用TestDFSIO基准测试,来测试HDFS的IO性能
用排序测试MapReduce:Hadoop自带一个部分排序的程序,这个测试过程的整个数据集都会通过洗牌(Shuffle)传输至Reducer,可以充分测试MapReduce的性能
在云计算环境中使用Hadoop
Hadoop不仅可以运行在企业内部的集群中,也可以运行在云计算环境中
可以在Amazon EC2中运行Hadoop。EC2是一个计算服务,允许客户租用计算机,来运行自己的应用。客户可以按需运行或终止实例,并且按照实际使用情况来付费
Hadoop自带有一套脚本,用于在EC2上面运行Hadoop
在EC2上运行Hadoop尤其适用于一些工作流。例如,在Amazon S3中存储数据,在EC2上运行集群,在集群中运行MapReduce作业,读取存储在S3中的数据,最后,在关闭集群之前将输出写回S3中;如果长期使用集群,复制S3数据到运行在EC2上的HDFS中,则可以使得数据处理更加高效,因为,HDFS可以充分利用数据的位置,S3则做不到,因为,S3与EC2的存储不在同一个节点上