三种算法的对比
| FM | FFM | AFM | |
|---|---|---|---|
| 交叉项 | 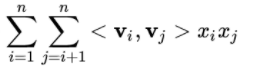 |
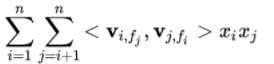 |
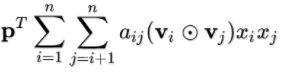 |
| 待学习的参数个数 | (1)LR部分: (2)embedding 部分: | (1)LR部分: (2)embedding 部分: | (1)FM部分参数: (2)Embedding部分参数: (3)Attention Network部分参数: (4)MLP部分参数: |
| 优点 | 使用隐向量相乘模拟特征交叉,适用于稀疏场景 | 提出field的概念,细化隐向量的表示 | 通过attention network学习不同特征交互的重要性,性能更好,可解释性强 |
| 缺点 | 一个特征只对应一个向量 | 慢 | 未考虑高阶组合特征 |
1 FM
1.1 模型方程
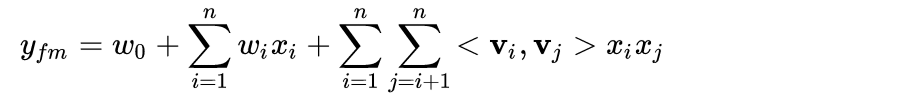
1.2 论文链接
Factorization Machines
分解机(Factorization Machines)推荐算法原理
1.3 特点
FM模型对稀疏数据有更好的学习能力,通过交互项可以学习特征之间的关联关系,并且保证了学习效率和预估能力,具有线性的计算复杂度。
1.4 原理
对于categorical(类别)类型特征,需要经过One-Hot Encoding转换成数值型特征,而大部分样本数据特征经过One-Hot编码之后是比较稀疏的(即特定样本的特征向量很多维度为0),同时导致特征空间大。
通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。因此,引入两个特征的组合是非常有意义的。
一般的线性模型为:
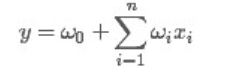
从上面的式子很容易看出,一般的线性模型压根没有考虑特征间的关联(组合)。为了表述特征间的相关性,我们采用多项式模型。在多项式模型中,特征xi与xj的组合用xixj表示。为了简单起见,我们讨论二阶多项式模型。具体的模型表达式如下:
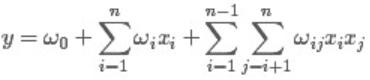
然而,每个参数 wij 的训练需要大量 xi 和xj都非零的样本,由于样本数据本来就比较稀疏,满足“xi 和 xj 都非零”的样本将会非常少。训练样本的不足,很容易导致参数 wij 不准确,最终将严重影响模型的性能。
如何解决二次项参数的训练问题呢?矩阵分解提供了一种解决思路。FM借鉴了矩阵分解的方式,将Wij拆解成vi与vj的向量点积,此时就不必要求xi与xj一定要同时非零的样本出现了,因为即使没有这种样本,假设有xh与xj的同时非零的样本存在,xk与xi同时非零的样本的存在,我们可以学到vh、vj、vk、vi。这样获得了vi与vj,就获得了曾经的wij。(此处用曾经的wij并不准确,只是方便理解这个曲线救国的过程。)
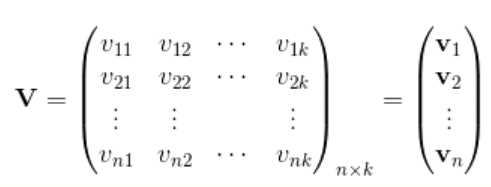
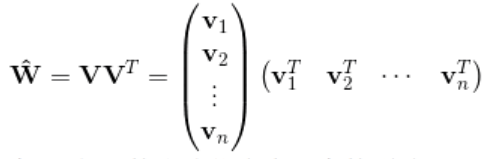
对辅助向量的维度k值的限定,反映了FM模型的表达能力。
由此得到FM的模型方程:
通过改写模型方程,可以将其复杂度降成线性的O(kn),具体过程如下:

FFM(Field-aware FM)
1.1 模型方程
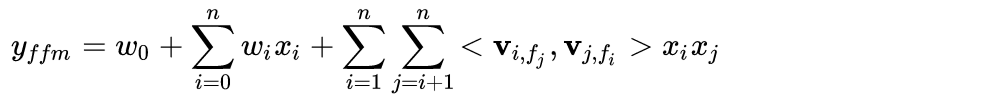
1.2 论文链接
Field-aware Factorization Machines for CTR Prediction
1.3 特点
FFM引入了field的概念。从论文中,可以看出:
-
对于包含分类特征并且转换为二进制特征的数据集,FFM表现很好
-
如果转换后的集合不够稀疏,FFM表现不是特别突出
-
将FFM应用于数值数据集会比较困难
-
FFMs在logloss方面优于其他模型,但它也比LMs和FMs需要更长的训练时间
1.4 原理
FM中一个特征只对应一个向量,而在实际场景中特征和不同field的特征交互时应该使用不同的向量,这就是Field-aware FM(FFM)的提出动机。通过引入field的概念,FFM把相同性质的特征归于同一个field, 每个特征的隐向量不再是只有一个,而是针对每个field学习一个独立的隐向量,防止互相影响。
说白了,就是将几个Field进行组合后,再在组合而成的Field的基础之上进行FM,实际上是增加了训练样本,使得结果更精确,但是它的训练时间比较尴尬:O(kn^2),而FM是线性的:O(kn)。
对比FM与FFM的交叉项,对于特征xi,它的隐向量不再是只有一个Vi,而是针对每个field学习一个独立的隐向量Vi,fj。
FM的交叉项:
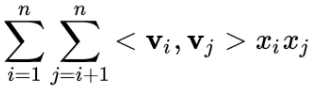
FFM的交叉项:
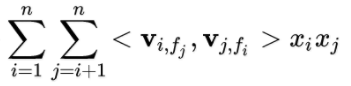
FM可以看作FFM的特例,是把所有特征都归属到一个field时的FFM模型。
AFM(Attentional FM)
1.1 模型方程
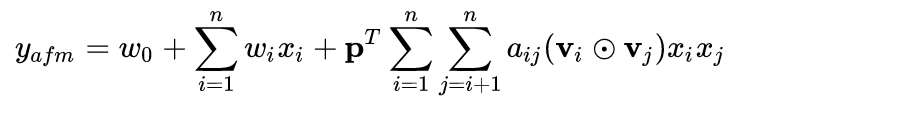

1.2 论文链接
1.3 特点
AFM区分不同特征相互作用的方式不再像ffm那么笨重,而且用一个神经网络学习得到参数 ,总体参数量增加也不明显。从论文中可以看出,AFM可以更好地拟合数据,从而使预测更加准确,对未知数据的泛化效果也更好。
1.4 原理
AFM也是FM的一种改进,它通过一个attention network来学习不同特征交互的重要性。
显然,不是所有的二阶特征交互的重要性都是一样的,例如:在句子"US continues taking a leading role on foreign payment transparency"中,除了"foreign payment transparency",其它句子明显与财经新闻无关,它们之间的交叉作用可认为对主题预测是一种噪音。如何通过机器自动的学习到这些重要性是这篇论文解决的最重要的问题。
FM模型中的两两交叉层可以表示为:
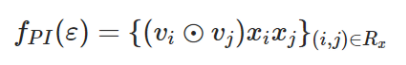
这里 表示element-wise product。然后通过全连接层映射至目标,有:
表示element-wise product。然后通过全连接层映射至目标,有:
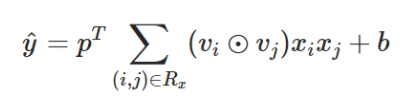
在上式的两两交叉的前面引入权重的话,即在FM的两两交叉层增加Attention-based pooling Layer, 则变为下式:
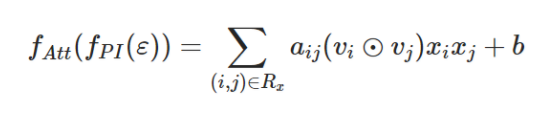
这里aij是特征交叉wij的注意力分(attention score),以说明wij的重要程度。
下面是训练 aij了。一种直接的做法是通过最小化损失函数而训练得到,但是在样本中,如果两个做交叉的两特征并不一起出现,训练就不容易了。为此,作者引入了多层感知机(multi-layer perceptron )来做训练。
attention network 可定义为:

那么最后AFM模型可表示为:
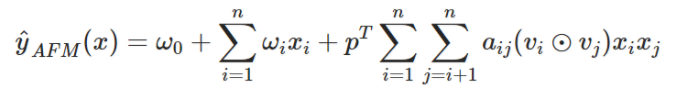
大量的实验表明,在FM上使用attention有两个好处:它不仅能带来更好的性能,而且还能观察哪些二阶特征交互对预测的贡献更大。
总结
在计算广告中使用逻辑回归等算法进行CTR(广告点击率)、CVR(转化率)等预估时,有三个重要的问题:
1) 特征稀疏问题。
2) 特征空间非常大的问题。
3) 没有考虑特征之间的相互关系。
由于以上三个问题的存在,FM应运而生。
FFM是基于FM的,它改进的地方在于添加了field, 每个特征的隐向量不再是只有一个,而是针对每个field学习一个独立的隐向量。
AFM也是FM的一种改进,它通过一个attention network来学习不同特征交互的重要性。在FM上使用attention不仅能带来更好的性能,而且还能观察哪些二阶特征交互对预测的贡献更大。
参考文献
逻辑回归、FM、FFM比较总结
FM和FFM算法精髓
FM与FFM
FM算法及FFM算法
FM及FFM算法
FM系列算法解读(FM+FFM+DeepFM)
FFM
AFM(Attention+FM)-----Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Network
深度学习在CTR预估中的应用