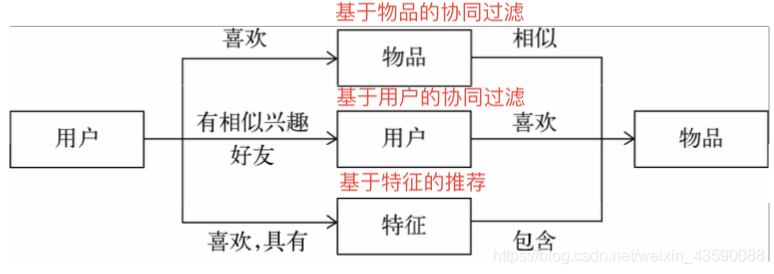
1、联系用户和物品的途径
第一种方式利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品,第二张方式是利用和用户兴趣相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品,第三种是通过一些特征联系用户和物品,向用户推荐用户喜欢的特征的物品集合。特征包括物品的属性集合,也可以是隐语义向量。这文将讨论一直重要的特征表现方式——标签。
2、标签系统的典型代表
如豆瓣,首先,在每本书的页面 上,豆瓣都提供了一个叫做“豆瓣成员常用标签”的应用,它给出了这本书上用户最常打的标签。同时,在用户给书做评价时,豆瓣也会让用户给图书打标签。最后,在最终的个性化推荐结果里, 豆瓣利用标签将用户的推荐结果做了聚类,显示了对不同标签下用户的推荐结果,从而增加了推 荐的多样性和可解释性。
以《四个春天》这本书为例,会展示用户对这本图书的标签

3、基于标签的推荐系统
一个用户标签行为的数据集一般由一个三元组的集合表示,其中记录(u,i,b)表示用户u给物品i打上了标签b,即(用户、物品、标签)。
3.1 试验设置
这里将数据集随机分为10份,分割的键值是用户和物品,不包括标签。挑选一份作为测试集,剩下的九份作为训练集,通过学习训练集中的用户标签数据预测测试集上用户会给什么物品打标签。对于用户u,令R(u)为给用户u的长度为N 的推荐列表,里面包含我们认为用户会打标签的物品。令T(u)是测试集中用户u实际上打过标签 的物品集合。然后,我们利用准确率(precision)和召回率(recall)评测个性化推荐算法的精度。

3.2 最简单的推荐算法
数据集采用Delicious数据集(delicious数据集),表格结构是:用户id-物品id-标签,数据集下载here
思路:
(1)统计每个用户最常用的标签
(2)对于每个标签,统计被打过这个标签次数最多的物品
(3)对于一个用户,首先找到他常用的标签,然后找到具有这些标签的最热门物品推荐给这个用户。
因此,用户u对物品i的兴趣公式如下:
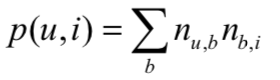
B(u)是用户u打过的标签集合,B(i)是物品i被打过的标签集合,nu,b是用户u打过标签b 的次数,nb,i是物品i被打过标签b的次数。
定义:
(1)用 records 存储标签数据的三元组,其中records[i] = [user, item, tag];
(2)用 user_tags 存储nu,b,其中user_tags[u][b] = nu,b;
(3)用 tag_items存储nb,i,其中tag_items[b][i] = nb,i。
import random
import math
#统计各类数量
def addValueToMat(theMat,key,value,incr):
if key not in theMat:
theMat[key] = dict();
theMat[key][value] = incr;
else:
if value not in theMat[key]:
theMat[key][value] = incr;
else:
theMat[key][value] += incr;#若有值,则递增
user_tags = dict();
tag_items = dict();
user_items = dict();
user_items_test = dict();#测试集数据字典
#初始化,进行统计
def InitStat():
data_file = open('delicious.dat', encoding='ISO-8859-1')
line = data_file.readline();
while line:
if random.random()>0.1:#将数据集的90%作为训练集,剩下的作为测试集
terms = line.split("\t");#将user item tag放入terms中
user = terms[0]
item = terms[1]
tag = terms[2]
#user_tags={user1:{tag:1},user2....},统计某用户标记同一个标签的次数
addValueToMat(user_tags,user,tag,1)
#tag_items={tag1:{item:1},tag2....},统计同一个标签用在多少个物品
addValueToMat(tag_items,tag,item,1)
#user_items={user1:{item:1}....},统计某用户标记了多少个物品
addValueToMat(user_items,user,item,1)
line = data_file.readline();
else:
addValueToMat(user_items_test,user,item,1)
data_file.close();
#推荐算法:
def Recommend(usr):
recommend_list = dict();
tagged_item = user_items[usr];#得到该用户所有推荐过的物品
for tag_,wut in user_tags[usr].items():#用户打过的标签以及次数
for item_,wit in tag_items[tag_].items():#物品被打过的标签以及被打过的次数
if item_ not in tagged_item:#不再推荐已经推荐过的物品
if item_ not in recommend_list:
recommend_list[item_]=wut*wit;
else:
recommend_list[item_]+=wut*wit;
return sorted(recommend_list.items(),key=lambda a:a[1],reverse=True)
InitStat()
recommend_list = Recommend("48411")
for recommend in recommend_list[:10]:
print(recommend)
结果:
('912', 610)
('3763', 394)
('52503', 238)
('39051', 154)
('45647', 147)
('21832', 144)
('1963', 143)
('1237', 140)
('33815', 140)
('5136', 138)