距离上次更新已经不知道有多久了,因为过几日就是中期答辩了,为了不太监开始坚持把这个项目往后做一做。
这次我们要做的是什么呢,要先搭建整个开发环境,目前用到的如下:mysql,idea,IKAnalyzer2012_u6(一个开源的分词包,完全够用了)
这次我计划先完成最简单的一个推荐系统的设计,目的只为了完成通过余弦相似性来计算文本的相似性,提取特征值采用数据库中最好拆解分析的“原料”列
余弦相似度和tf-idf的参考文章 http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
IKAnalyzer 下载地址http://lxw1234.com/archives/2015/07/422.htm
需要用到的jar包:
上面两个在上面那个下载的文件夹里,导入即可,jdbc的java和mysql的连接用的jar包自己搜着下载吧。
用到的数据库:已经放到我百度云里了https://pan.baidu.com/s/1nv4klM5,格式是mdb也就是微软的access,我使用的是navicat将其转换为mysql的。
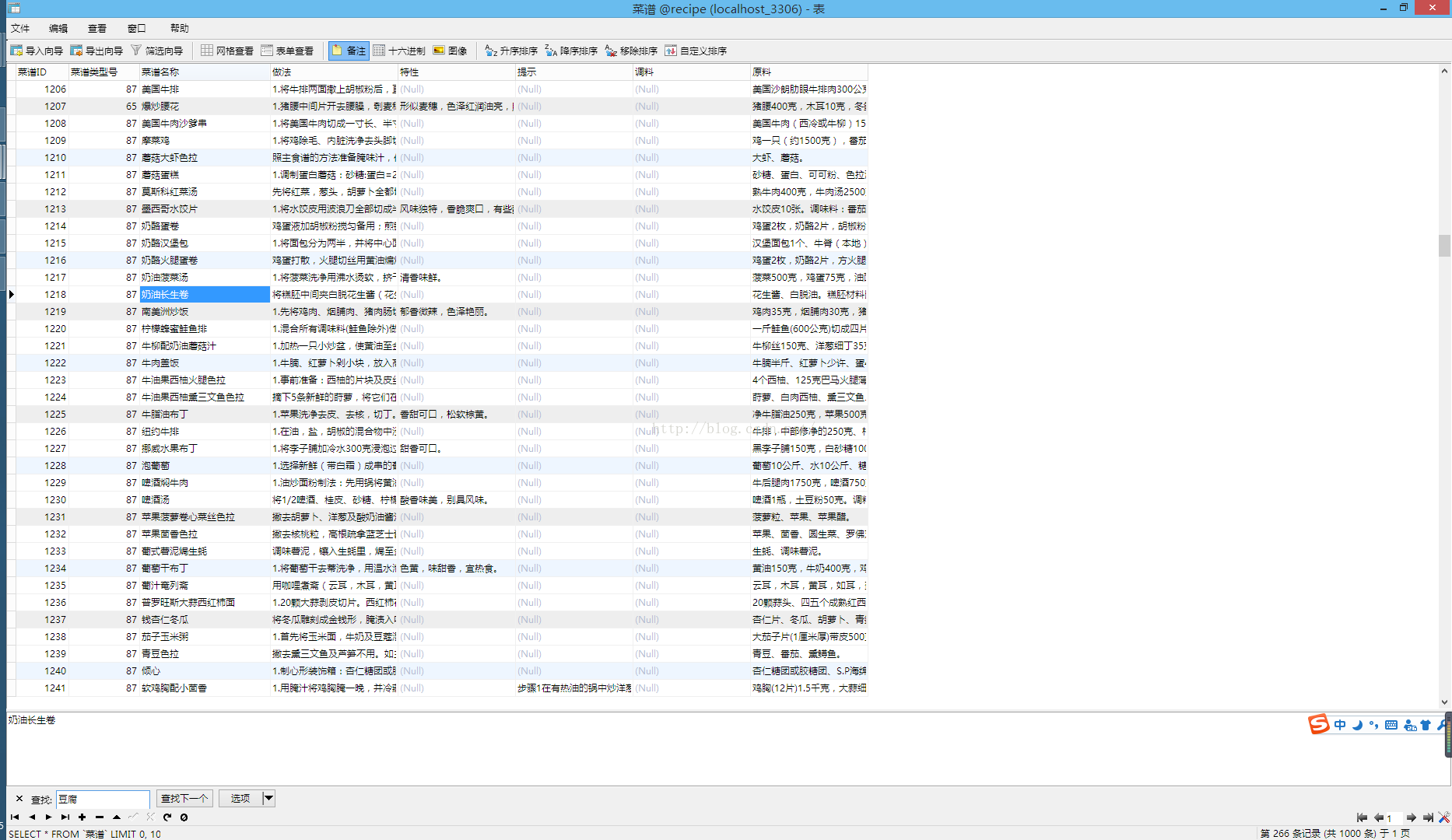
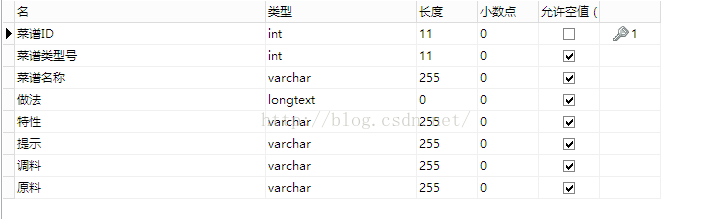
数据格式:
我们先上一个现在达到的最终效果
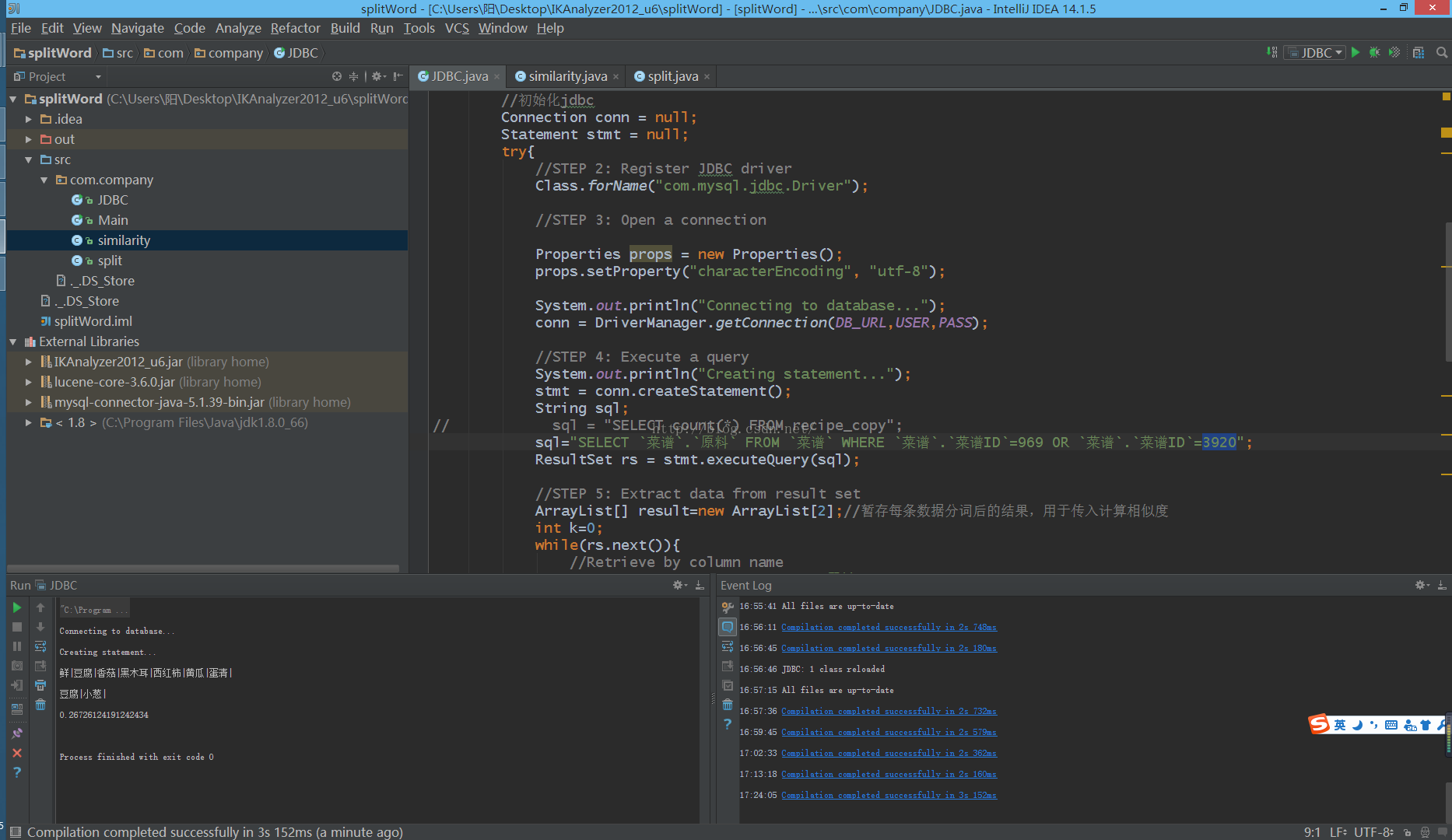

接下来讲如何实现。
首先我设计了三个类,分别是JDBC类用于连接数据库, similarity类用于计算相似度,split类用来完成分词。
先将最重要的部分,similarity类是如何工作的。
我们采用默认的分词方法,随便分一行中的原料列看看效果
菠菜|400克|熟火腿|20克|鸡蛋|50克|海米|20克|熟|冬笋|50克|水|发|冬菇|50克|胡萝卜|50克|
里面有两个方法,getSimilarDegree计算相似度,delUseless是将无用的“50克”这样的删掉。
下面我们举一个实际的例子:
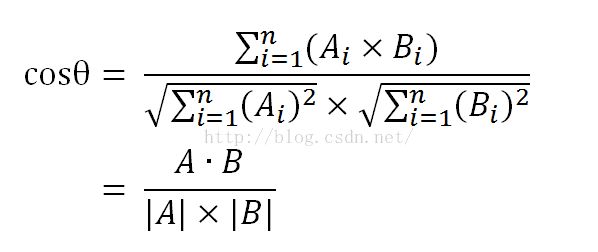
Map<String, int[]> vectorSpace = new HashMap<String, int[]>();
|
鲜
|
1 | 0 |
|
豆腐
|
1 | 1 |
|
香菇
|
1 | 0 |
|
黑木耳
|
1 | 0 |
|
西红柿
|
1 | 0 |
|
黄瓜
|
1 | 0 |
|
蛋清
|
1 | 0 |
| 小葱 | 0 | 1 |
下面是similarity类的代码:
package com.company;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by 阳 on 2016/12/5.
*/
public class similarity {
/*
* 计算两个字符串(英文字符)的相似度,简单的余弦计算,未添权重
*/
public double getSimilarDegree(ArrayList<String> str1, ArrayList<String> str2)
{
//创建向量空间模型,使用map实现,主键为词项,值为长度为2的数组,存放着对应词项在字符串中的出现次数
Map<String, int[]> vectorSpace = new HashMap<String, int[]>();
int[] itemCountArray = null;//为了避免频繁产生局部变量,所以将itemCountArray声明在此
//动态数组转为数组
int size1=str1.size();
String[] strArray1 = (String[])str1.toArray(new String[size1]);
for(int i=0; i<strArray1.length; ++i)
{
if(vectorSpace.containsKey(strArray1[i]))
++(vectorSpace.get(strArray1[i])[0]);
else
{
itemCountArray = new int[2];
itemCountArray[0] = 1;
itemCountArray[1] = 0;
vectorSpace.put(strArray1[i], itemCountArray);
}
}
int size2=str2.size();
String[] strArray2 = (String[])str2.toArray(new String[size2]);
for(int i=0; i<strArray2.length; ++i)
{
if(vectorSpace.containsKey(strArray2[i]))
++(vectorSpace.get(strArray2[i])[1]);
else
{
itemCountArray = new int[2];
itemCountArray[0] = 0;
itemCountArray[1] = 1;
vectorSpace.put(strArray2[i], itemCountArray);
}
}
//计算相似度
double vector1Modulo = 0.00;//向量1的模
double vector2Modulo = 0.00;//向量2的模
double vectorProduct = 0.00; //向量积
Iterator iter = vectorSpace.entrySet().iterator();
while(iter.hasNext())
{
Map.Entry entry = (Map.Entry)iter.next();
itemCountArray = (int[])entry.getValue();
vector1Modulo += itemCountArray[0]*itemCountArray[0];
vector2Modulo += itemCountArray[1]*itemCountArray[1];
vectorProduct += itemCountArray[0]*itemCountArray[1];
}
vector1Modulo = Math.sqrt(vector1Modulo);
vector2Modulo = Math.sqrt(vector2Modulo);
//返回相似度
return (vectorProduct/(vector1Modulo*vector2Modulo));
}
/*
计算原料列相似度的时候去除数字和“克”这些无用词
用正则表达式
*/
public boolean delUseless(String value){
Pattern pattern = Pattern.compile("^\\pN");
Matcher isNum = pattern.matcher(value);
if(isNum.find()){
return true;
}else
return false;
}
}
最后这个正则要多说几句:
| \un |
匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
然后是split,基本上就是照着给的例子写一个就能用:
package com.company;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
/**
* Created by 阳 on 2016/12/5.
*/
public class split {
similarity sim=new similarity();
//体现出分词效果
public void splitWord(String s) throws IOException {
String text = s;
Analyzer analyzer = new IKAnalyzer(true);// 构造函数当为 true时,分词器采用智能切分
StringReader reader = new StringReader(text);
TokenStream ts = analyzer.tokenStream("", reader);
CharTermAttribute term=ts.getAttribute(CharTermAttribute.class);
while(ts.incrementToken()){
if(!sim.delUseless(term.toString())){
System.out.print(term.toString() + "|");
}
}
System.out.println();
analyzer.close();
reader.close();
}
//将分词结果存到数组中去,在这里面处理掉无用词
public ArrayList<String> splitWordtoArr(String s) throws IOException {
String text = s;
ArrayList List = new ArrayList();
Analyzer analyzer = new IKAnalyzer(true);// 构造函数当为 true时,分词器采用智能切分
StringReader reader = new StringReader(text);
TokenStream ts = analyzer.tokenStream("", reader);
CharTermAttribute term=ts.getAttribute(CharTermAttribute.class);
while(ts.incrementToken()){
if(!sim.delUseless(term.toString())){
List.add(term.toString());
}
}
analyzer.close();
reader.close();
return List;
}
}
然后放上最没有技术含量的jdbc:
package com.company;
import java.sql.*;
import java.util.ArrayList;
import java.util.Properties;
/**
* Created by sunyang on 16/9/25.
*/
public class JDBC {
// JDBC driver name and database URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://localhost/recipe";
// Database credentials
static final String USER = "root";
static final String PASS = "";
public static void main(String[] args) {
/*
新建split对象,然后用jdbc读取数据用splitWrod处理
*/
split sw=new split();
similarity sim=new similarity();
//初始化jdbc
Connection conn = null;
Statement stmt = null;
try{
//STEP 2: Register JDBC driver
Class.forName("com.mysql.jdbc.Driver");
//STEP 3: Open a connection
Properties props = new Properties();
props.setProperty("characterEncoding", "utf-8");
System.out.println("Connecting to database...");
conn = DriverManager.getConnection(DB_URL,USER,PASS);
//STEP 4: Execute a query
System.out.println("Creating statement...");
stmt = conn.createStatement();
String sql;
// sql = "SELECT count(*) FROM recipe_copy";
sql="SELECT `菜谱`.`原料` FROM `菜谱` WHERE `菜谱`.`菜谱ID`=969 OR `菜谱`.`菜谱ID`=1000";
ResultSet rs = stmt.executeQuery(sql);
//STEP 5: Extract data from result set
ArrayList[] result=new ArrayList[2];//暂存每条数据分词后的结果,用于传入计算相似度
int k=0;
while(rs.next()){
//Retrieve by column name
String handle = rs.getString("原料");
//Display values
sw.splitWord(handle);
result[k]=sw.splitWordtoArr(handle);
k++;
}
System.out.println(sim.getSimilarDegree(result[0],result[1]));//计算相似度
//STEP 6: Clean-up environment
rs.close();
stmt.close();
conn.close();
}catch(SQLException se){
//Handle errors for JDBC
se.printStackTrace();
}catch(Exception e){
//Handle errors for Class.forName
e.printStackTrace();
}finally{
//finally block used to close resources
try{
if(stmt!=null)
stmt.close();
}catch(SQLException se2){
}// nothing we can do
try{
if(conn!=null)
conn.close();
}catch(SQLException se){
se.printStackTrace();
}//end finally try
}//end try
}//end main
}//end FirstExample
目前先做到这这一步,往后就是考虑对整个菜谱的相似度计算的问题。以及如何对个人生成个性化的推荐(也就是如何刻画每个人人的人像)