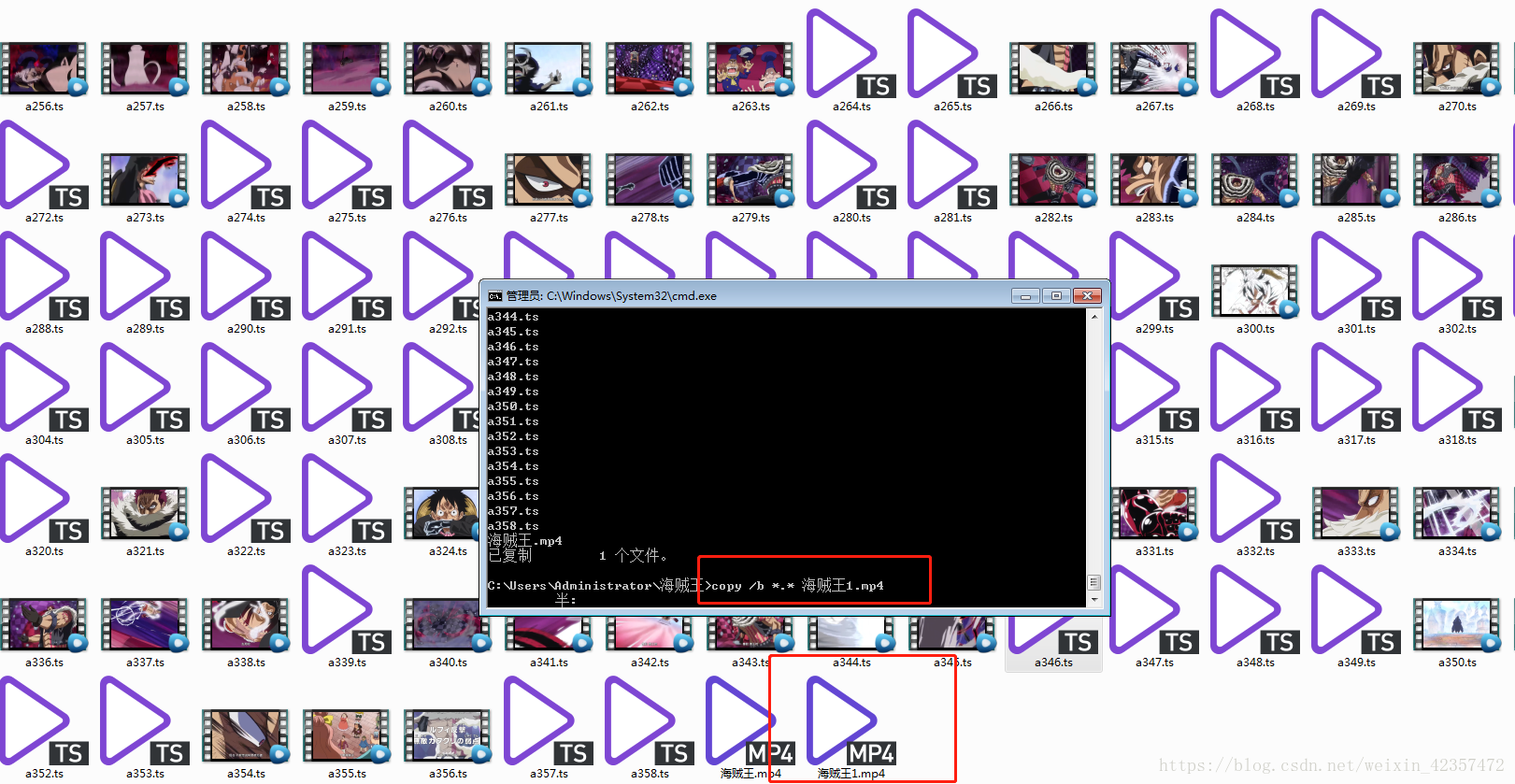
##本篇主要是尝试下载爬取视频并且下载下来,因为直接官网视频网站很难破解,所以采取已有的解析网站进行间接破解下载
##这个网上很多可以查找,这边提供几个可以尝试(VIP视频电影解析接口:http://api.greatchina56.com/?url=???, http://jx.618g.com/?url=??? ),???即为优酷爱奇艺腾讯视频连接地址复制上就行,这是第一步

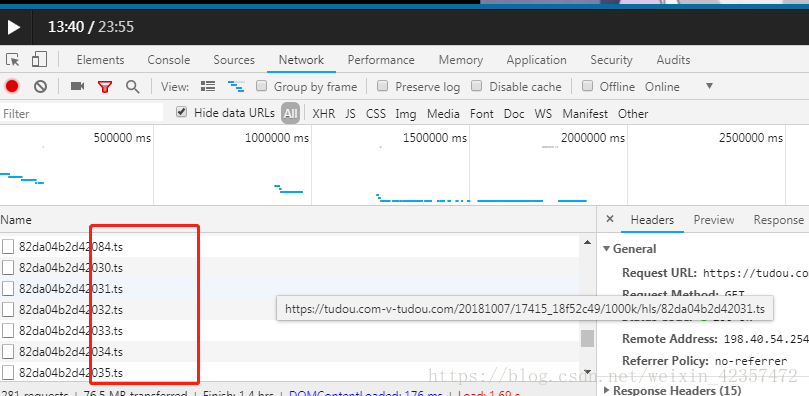
##接下来就是分析下载地址,用谷歌浏览器按 F12,通过分析是ts数据流,可以得到规律和真实下载地址,总共358个ts文件,下面就是写代码把循环下载下来
import requests
from multiprocess import Pool
def loder(i):
url="https://tudou.com-v-tudou.com/20181007/17415_18f52c49/1000k/hls/82da04b2d42%03d.ts"%i #%03d 左边补0方式
html=requests.get(url).content
# print(html)
with open("海贼王\%s%03d.ts"%("a",i),"wb") as f:
f.write(html)
if __name__== "__main__":
pool = Pool(10)
# for i in range(2238):
# pool.apply_async(loder, (i,))
pool.map(loder, range(359)
pool.close()
pool.join()
##由于数量很多所以采取了多进程方式,另外需要注意,最后下载下来文件通过系统cmd 在当前文件夹下进行 copy /b 命令合并时候文件名需要保存同样的位数,比如本例共358分,你第1也需要001这样显示才行,不然合并就会出错误