因为这是我第一个独立实践的爬虫项目,所以这次把思路都放上来了
特别注意,用的是charles,可以拦截查看url
知识点:
·······利用charles分析网页,抓包,得出对应URL
·······json网页不是可以直接用json.load 直接转换json的
·······利用find_path快速找到所需内容的路径
······学会用try,预防程序中断
·······urltrieve下载文件可以添加回调函数
·······多进程使用
·······利用sys.stdout.write 记录进度
============先打开charles,再操作qq音乐
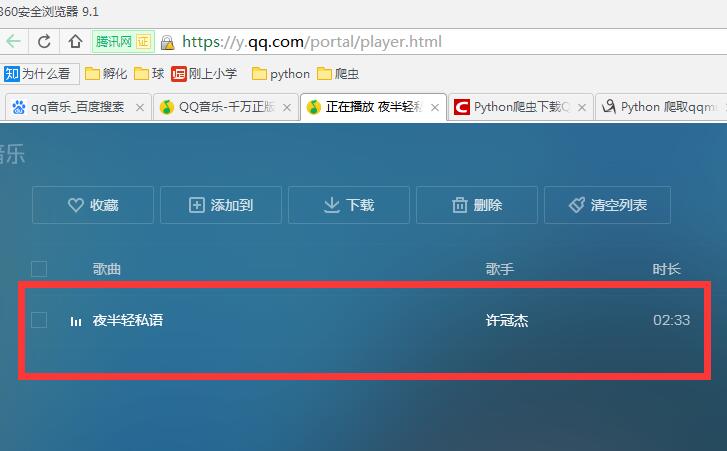
1.打开qq音乐页面,进入我的音乐
2.选择我创建的歌单
3.选择其中一个歌单
4.进入歌单,随便选一首歌,点击播放
5.最后就进入了这个页面,可以播放歌曲了
==========================================================
好了,现在可以看看charles上有哪些url
特喵的,这么多,怎么入手?
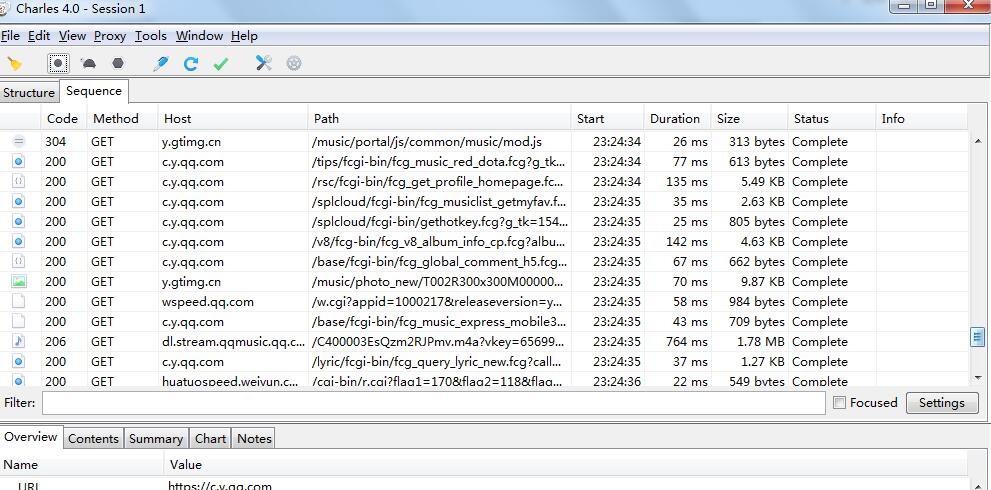
思路:
①不一定要跟着步骤去找url,可以反过来的嘛
先找歌曲文件mp3(原来是m4a格式)
找code是206的url,206一般是歌曲跟视频下载什么的
找到了,不过这个url好像有点儿复杂
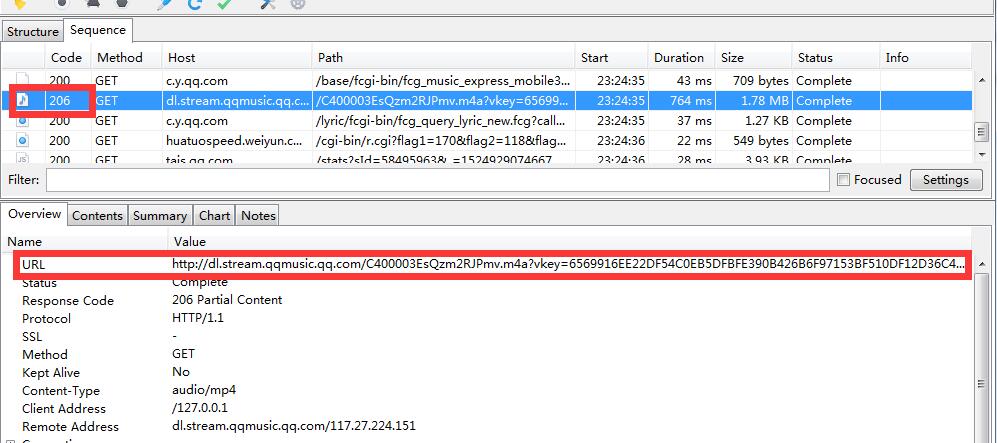
我把这个url分析了下:

不同歌曲间,只需改变那2个变量即可下载!
②那么,如何得到那个m4a跟 vkey呢?
这时就是charles大显神威了,直接ctrl+f,搜索那2个变量,直接vkey就行了!
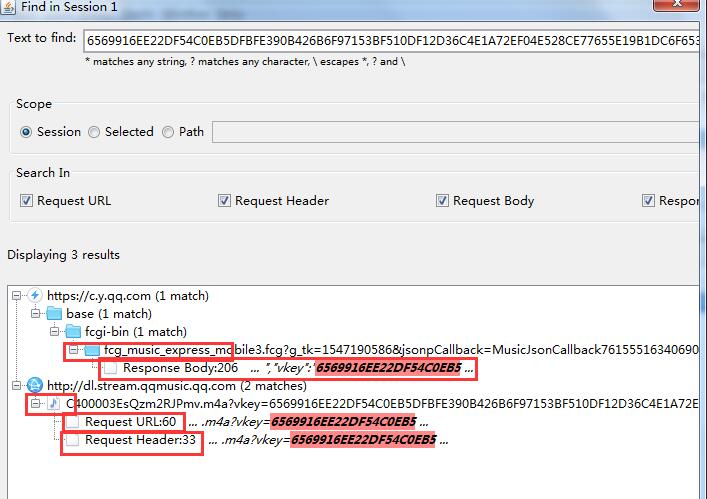
看,结果是2部分,分别是2个网址,下面那个就是歌曲的url了,复制的文本是在Request URL跟Header,那就是刚刚从这里赋值过来的,所以忽略,主要看上面那个
Response Body:206,,,对了,看来vkey就是出自这个网址了,点击进去
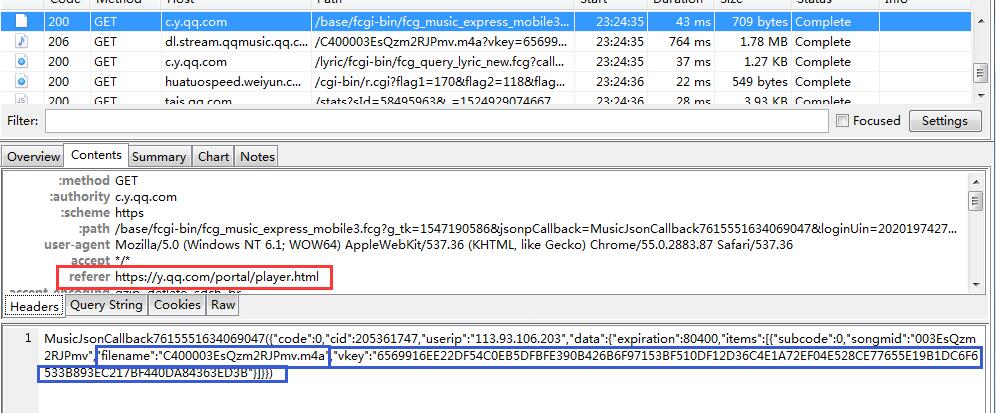
OK,看来找到vkey跟filename的出处了,那么下一步就是分析这个URL的组成了
PS:注意,如果进入这个网址,构造的时候需要在header加上referer:https://y.qq.com/portal/player.html
很明显,这个url也很鸡儿复杂,我还得分析:
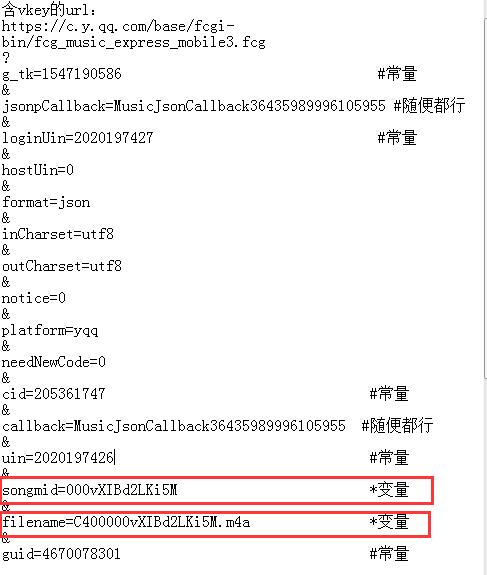
③:看上去这个url很复杂,实际只需2个变量!songmid跟filename,不过仔细一看,这2个变量其实只需songmid就行了,
因为filename=C400+songmid,这时就继续利用charles,ctrl+F 看看这个songmid出自哪里
搜索结果如下:
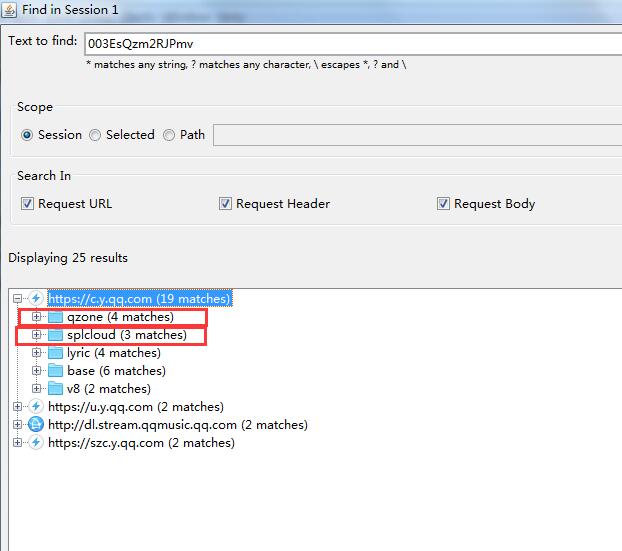
包含songmid字串符的url有这么多,而我的目的页面是这个:
包含360多首歌的songmid,经过对比就是上面qzone跟splcloud这2个网址,我就选了qzone这个继续分析了

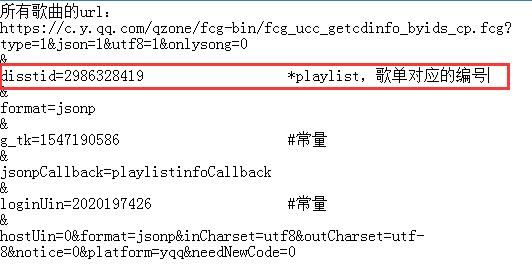
OK!所有歌曲的songmid都在里面了,剩下来就再分析这个URL的组成了 PS:referer:'https://y.qq.com/n/yqq/playlist/2986328419.html'
===============================================
所需的网址全部找出来了,现在把思路整理下:
1.进入包含所有songmid的歌单URL:得到songmid
https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&disstid=2986328419&format=jsonp&g_tk=1547190586&jsonpCallback=playlistinfoCallback&loginUin=2020197426&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0
referer:https://y.qq.com/n/yqq/playlist/2986328419.html
2.进入songmid的URL:得到对应的vkey
https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=1547190586&jsonpCallback=MusicJsonCallback7615551634069047&loginUin=2020197426&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback7615551634069047&uin=2020197426&songmid=003EsQzm2RJPmv&filename=C400003EsQzm2RJPmv.m4a&guid=4670078301
referer:https://y.qq.com/portal/player.html
3.得到歌曲的URL,可以直接下载了
http://dl.stream.qqmusic.qq.com/C400003EsQzm2RJPmv.m4a?vkey=6569916EE22DF54C0EB5DFBFE390B426B6F97153BF510DF12D36C4E1A72EF04E528CE77655E19B1DC6F6533B893EC217BF440DA84363ED3B&guid=4670078301&uin=2020197426&fromtag=66
=========================================================
现在终于可以写代码了!
一、先搞歌单这部分
import requests,json,re,urllib,os url='https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&disstid=2984189527&format=jsonp&g_tk=1547190586&jsonpCallback=playlistinfoCallback&loginUin=2020197426&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0' header={} header['user-agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' header['referer']='https://y.qq.com/n/yqq/playlist/2984189527.html' req=requests.get(url,headers=header) req1=str(req.text).replace('playlistinfoCallback','').strip('()')#原text不能直接json,要把头跟末尾去掉才行! info=json.loads(req1) print(info)
text的内容:

我去,好恐怖的字典,怎么找出我要的songmid位置?
当然可以自己手动找,不过我之前不是写了个find_path模块吗?正好派上用场
from find_path.find_path import find_path d=find_path() d.work(info,'004WJqnr0OlghO')
搜索结果:
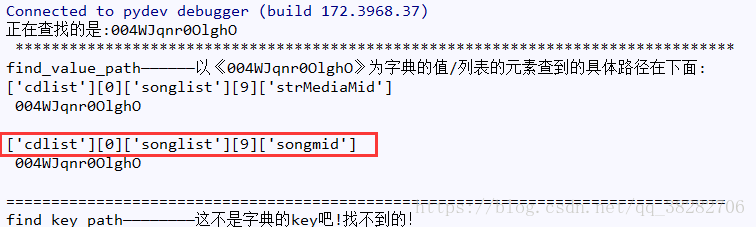
OK!知道什么路径了,现在把songmid、歌手、歌曲名、都提取出来!
import requests,json,re,urllib,os from find_path.find_path import find_path playlist='2984189527' ##指定歌单 url='https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&disstid={}\ &format=jsonp&g_tk=1547190586&jsonpCallback=playlistinfoCallback&loginUin=2020197426\ &hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0'.format(playlist) header={} header['user-agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' header['referer']='https://y.qq.com/n/yqq/playlist/{}.html'.format(playlist) req=requests.get(url,headers=header) req1=str(req.text).replace('playlistinfoCallback','').strip('()')#原text不能直接json,要把头跟末尾去掉才行! info=json.loads(req1) songinfo=info['cdlist'][0]['songlist'] songlist={} for name in songinfo: songlist[name['songmid']]=name['singer'][0]['name']+'-'+name['songname'] print(songlist) ##得到的字典就是'003gltCe0JUvCU': '雷安娜-停不了的爱' 各个歌曲组成
二、现在随便拿一首歌进行下载:
#求vkey header1={} header1['user-agent']='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' header1['referer']='https://y.qq.com/portal/player.html' id='002pRyIY2kSvK1' #要找的歌曲的songmid url='https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=1547190586&jsonpCallback=MusicJsonCallback8769319220381753&loginUin=2020197427&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback8769319220381753&uin=2020197427\ &songmid={}&filename=C400{}.m4a&guid=4670078301'.format(id,id) keyreq=requests.get(url,headers=header1) vkey=re.findall(r'vkey":"(.+)"}]}}',keyreq.text)[0] ##下载歌曲 songurl='http://dl.stream.qqmusic.qq.com/C400{}.m4a?vkey={}\ &guid=4670078301&uin=2020197427&fromtag=66'.format(id,vkey) urllib.request.urlretrieve(songurl,os.getcwd()+'\\'+songlist[id]+'.m4a')

终于搞定了!! 剩下就是自己把代码简化了!然后把歌单里的所有歌曲都下载,代码整合如下
import requests,json,re,urllib,os,time,sys from find_path.find_path import find_path from multiprocessing import Pool import logging logger = logging.getLogger(__name__) class qqmusic_songs(object): def __init__(self,path): self.headers={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'} self.songdict={} #get_songdict会给它赋值 self.path=path def get_songdict(self,playlist): '''得出所输入歌单每首歌songmid:歌名 组成的字典''' headers=self.headers.copy() headers['referer'] = 'https://y.qq.com/n/yqq/playlist/{}.html'.format(playlist) url='https://c.y.qq.com/qzone/fcg-bin/fcg_ucc_getcdinfo_byids_cp.fcg?type=1&json=1&utf8=1&onlysong=0&disstid={}\ &format=jsonp&g_tk=1547190586&jsonpCallback=playlistinfoCallback&loginUin=2020197426\ &hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0'.format(playlist) req=requests.get(url,headers=headers) req1=str(req.text).replace('playlistinfoCallback','').strip('()')#原text不能直接json,要把头跟末尾去掉才行! info=json.loads(req1) songinfo=info['cdlist'][0]['songlist'] #对应的歌单里每首歌的歌曲信息 songdict={} for name in songinfo: songdict[name['songmid']]=name['singer'][0]['name']+'-'+name['songname']+'__['+name['albumname']+']' self.songdict=songdict return songdict ##得到的字典就是'003gltCe0JUvCU': '雷安娜-停不了的爱' 各个歌曲组成 def download_song(self,songmid): '''输入songmid,得出对应的vkey, 用urlretrieve下载歌曲''' headers=self.headers.copy() headers['referer']='https://y.qq.com/portal/player.html' url='https://c.y.qq.com/base/fcgi-bin/fcg_music_express_mobile3.fcg?g_tk=1547190586&jsonpCallback=MusicJsonCallback8769319220381753&loginUin=2020197427&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&cid=205361747&callback=MusicJsonCallback8769319220381753&uin=2020197427' \ '&songmid={}&filename=C400{}.m4a&guid=4670078301'.format(songmid,songmid) try: #不知哪首歌有问题,用try安全 keyreq=requests.get(url,headers=headers) vkey=re.findall(r'vkey":"(.+)"}]}}',keyreq.text)[0] #得出vkey,就可以得出歌曲的url了 ##下载歌曲 songurl='http://dl.stream.qqmusic.qq.com/C400{}.m4a?vkey={}&guid=4670078301&uin=2020197427&' \ 'fromtag=66'.format(songmid,vkey) path=self.path+'\\'+self.songdict[songmid]+'.m4a' if (not os.path.exists(path)): #如果中断,已经有的文件就不用再下载了 urllib.request.urlretrieve(songurl,path,reporthook=self.Schedule) time.sleep(0.8) except Exception as e: logger.warning(e) logger.warning("有问题的网址是%s,歌曲是%s"% (url,self.songdict[songmid])) def Schedule(self, a, b, c): '''urlretrieve的回调函数''' songscount=len(os.listdir(self.path)) per=100.0 * songscount/len(self.songdict) if per > 100: per = 1 sys.stdout.write(" " + "%.2f%% 已经下载%s首歌 共%s首歌" % (per, songscount,len(self.songdict)) + '\r') sys.stdout.flush() def work(self,playlist): '''多进程下载''' time1=time.time() songdict = self.get_songdict(playlist) print('正在下载歌单 %s 的歌曲'% playlist) pool=Pool(8) pool.map(self.download_song, songdict.keys()) pool.close() pool.join() time2=time.time() usetime=time2-time1 songscount = len(os.listdir(self.path)) print('下载完成! 理论上共%s首歌,实际下载了%s首歌,耗时%.1fs'%(len(self.songdict),songscount,usetime)) if __name__ == '__main__': path=r'C:\Users\Administrator\Desktop\歌曲' d=qqmusic_songs(path) d.work('2984189527')

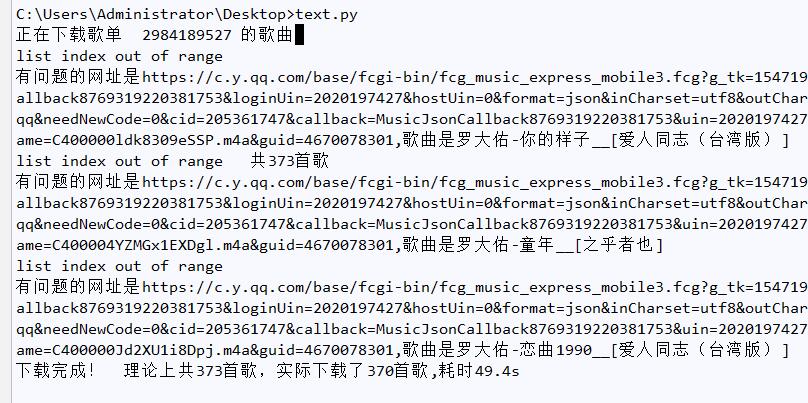
不过话说sys.write这个记录进度的方法,只能在cmd利用,pycharm显示不了的,不过可以用它的terminal控制台运行