转载https://blog.csdn.net/u011392897/article/details/57115818
代码基于jdk1.6_45 jdk1.7_80 jdk1.8_111,三个版本之间并没有什么特别大的改动或者改进。
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
一、基本性质
1、基于双向链表实现的List可以顺序访问,直接父类是AbstractSequentialList,不实现RandomAccess接口,不支持随机访问。
AbstractSequentialList这个抽象类实现了最基本的顺序访问功能,虽然支持随机访问的也支持顺序访问,但是一般设计上还是会把它们两个当成无关联的两个特性。所以当利用随机访问特性时优先extends AbstractList而不是此类,当然实现此类也可以,只是没必要。
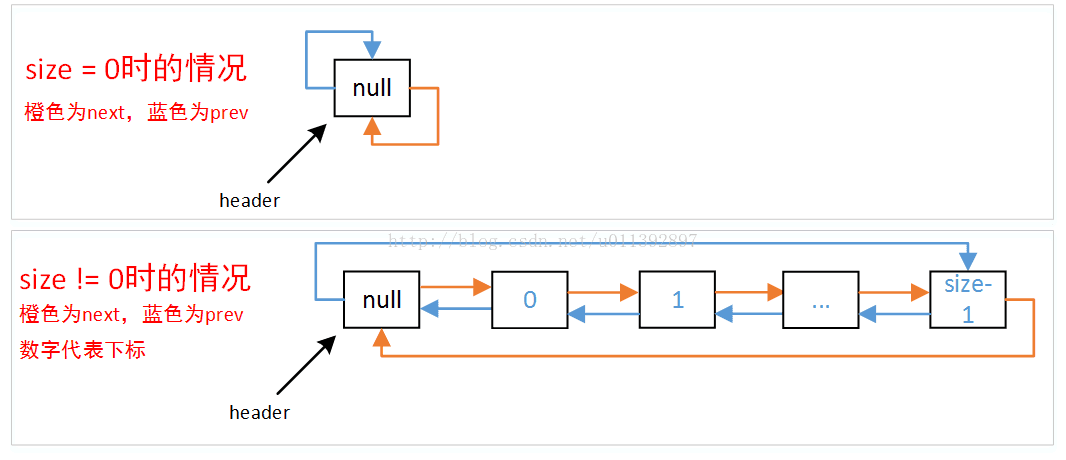
具体点,jdk1.6使用的是一个带有头结点的双向循环链表,头结点不存储实际数据,循环链表指的是能够只通过一个方向的指针重新遍历到自己这个节点的链表,示意图如下。
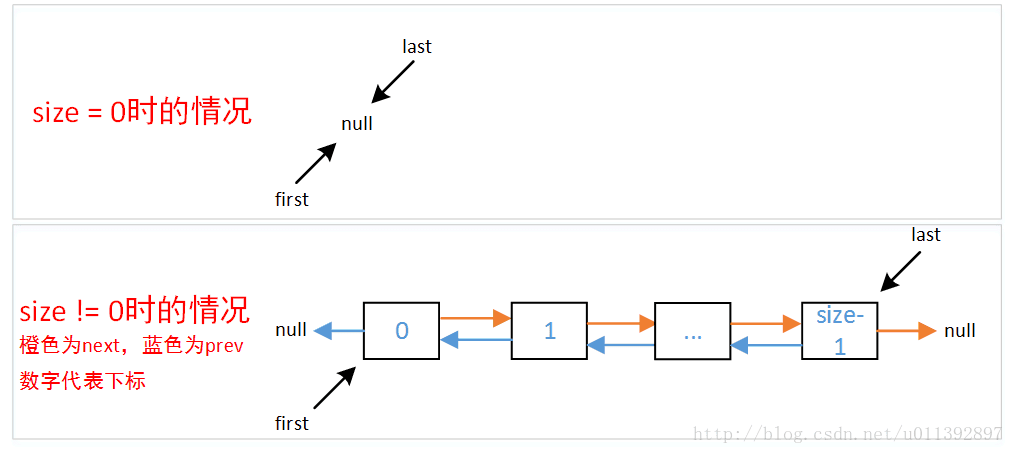
jdk1.7之后使用的是不带头结点的普通的双向链表,增加两个节点指针first、last分别指向首尾节点,示意图如下。
为什么要这样?感觉应该是为了节省那一个空间,毕竟链表带不带头结点实际操作没多大改变,性能也不变。这一点可以算作是678几个版本唯一的有意义的区别了。
虽然链表的插入、删除都是O(1),但那是在节点已知的情况下。LinkedList中定位一个节点需要遍历链表,因此与下标有关的插入、删除时间复杂度都变为O(n),下标无关的删除 remove(obj) 也需要遍历,所以也是O(n),尾部的添加、删除不需要遍历,时间复杂度为O(1),因此LinkedList整体读写效率不如ArrayList。但是链表结构对内存要求低,不需要大块连续内存来满足扩容,能够自动动态地消耗内存,容量变小时会自动释放曾经占用的内存,ArrayList则需要手动trim。
2、相比ArrayList,此类还额外实现了Deque接口,可以充当一般的双端队列或者栈,所以LinkedList很通用,可以作为一些混合数据结构的基础。
3、理论上无容量限制,只受虚拟机自身限制影响,所以没有扩容方法。
4、和ArrayList一样,LinkedList也是是未同步的,多线程并发读写时需要外部同步,如果不外部同步,那么可以使用Collections.synchronizedList方法对LinkedList的实例进行一次封装。
5、和ArrayList一样,LinkedList也对存储的元素无限制,允许null元素。
6、和ArrayList一样,LinkedList的迭代器也是快速失败的,并且也不是100%保证,不应去依赖这个性质。
7、实现Cloneable接口,可以被clone。和ArrayList一样,clone是自己写的方法,实际元素也是双方共享。
8、实现Serializable接口,可以被序列化/反序列化。相关的两个方法是自己写的,序列化时只序列化size以及顺序序列化每一个实际的元素,不序列化其他无用的指针,节省空间。反序列化就是把size个元素按顺序再一个个在尾部添加一遍。
二、构造方法
1、默认构造方法(无参构造方法),public LinkedList()
1.6的把header这个变量声明时的初始值是一个空的Entry,构造方法中只是改一下对应指针的指向,具体构造出来的结构可以看下上面的第一张图片中size = 0的情况。
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;
...
/** Constructs an empty list. */
public LinkedList() {
header.next = header.previous = header;
}
-
1.7开始,因为不再使用header节点,所以默认构造方法声明也不做,first和last会被默认初始化为null。
// 这是1.8的代码,1.7的一样
transient int size = 0;
...
/**
* Pointer to first node.
* Invariant: (first == null && last == null) || (first.prev == null && first.item != null) 这是个固定不变的关系
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) || (last.next == null && last.item != null) 这是个固定不变的关系
*/
transient Node<E> last;
/** Constructs an empty list. */
public LinkedList() {
}
因为给LinkedList指定初始容量没什么实际意义,所以不需要指定初始容量的构造方法。
2、Collection拷贝构造方法,public LinkedList(Collection<? extends E> c)
// 三个版本都一样,这个没什么好说的
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
三、常用方法
LinkedList的操作都是基本的链表操作,不超过数据结构教材中讲的内容,不太懂的可以复习下数据结构。
1.6的指针操作主要是靠private Entry<E> addBefore(E e, Entry<E> entry)和remove(Entry<E> e)两个方法,因为有头结点的原因,方法操作的一致性高,流程中if判断比较少。
1.7开始变成了linkBefore/unlink方法,因为没有header节点,需要用if判断的就多一些,总共写了linkBefore/linkFirst/linkedLast/unlink/unlinkFirst/unlinkLast这6个方法,其实可以把linkBefore/unlink里面的逻辑再完善下,这样也可以只用两个。
三个版本代码基本上没什么实质性的改动。
先说下这个简单的优化:
// 这是1.8的代码,之前版本逻辑一样
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
一个很小的优化,根据下标判断下哪种路径更短,该从头开始还是从尾部开始。因为下标index是从0开始的,所以if (index < (size >> 1))这句是没有问题的,加上等号才有问题。
简单看下add/remove方法,当作是复习下普通链表。
// 下面是jdk1.8的代码,因为没有使用头结点,所以代码比1.6的看起来麻烦些,if判断更多
public void add(int index, E element) {
checkPositionIndex(index); // 检查下标
if (index == size) // 是在尾部添加
linkLast(element);
else // 中间添加,需要寻找当前index处的节点,把新节点添加在它的前面
linkBefore(element, node(index));
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
add方法简单画了个图,可以看下。
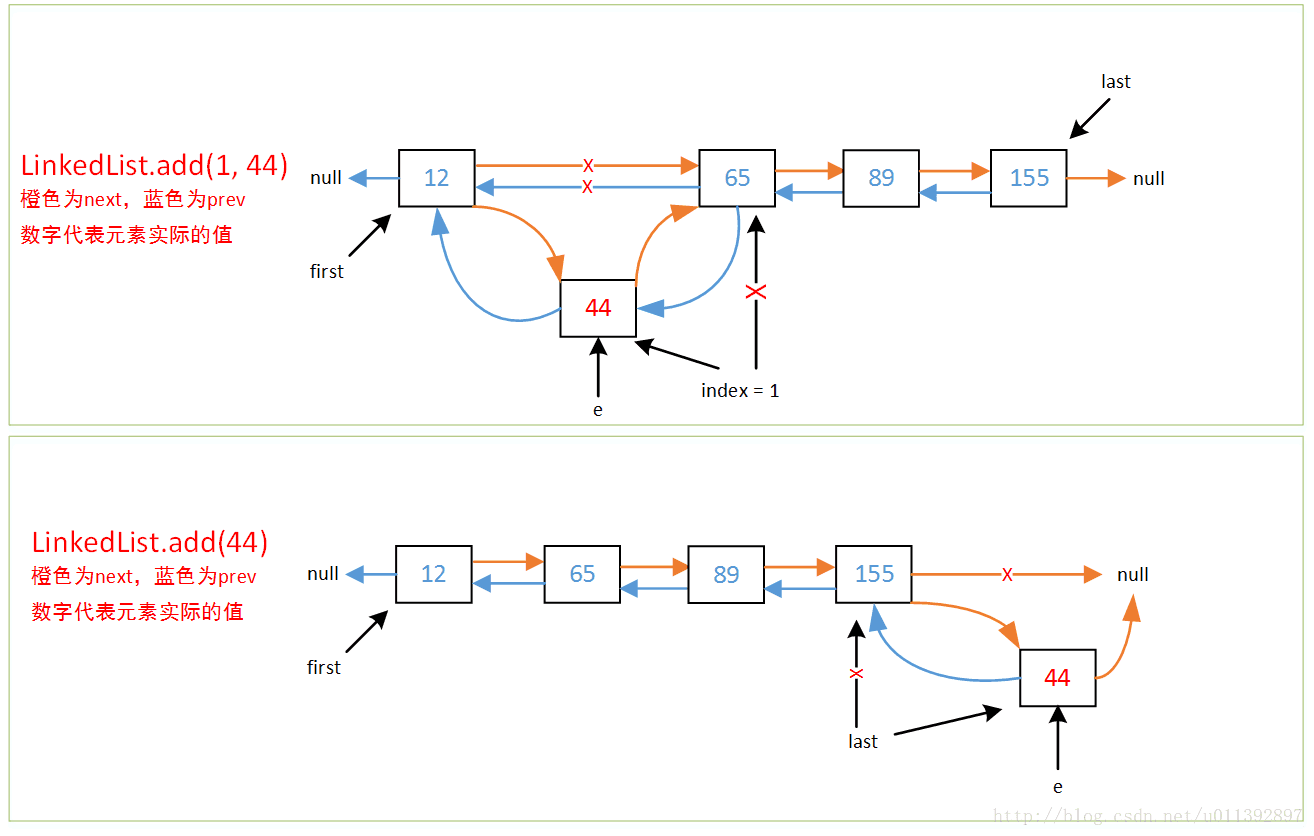
// 下面是jdk1.8的代码,因为没有使用头结点,所以代码比1.6的看起来麻烦些,if判断更多
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) { // 要删除的是第一个节点
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) { // 要删除的是最后一个节点
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove示意图如下。
其他方法就不说了,本身比较简单。
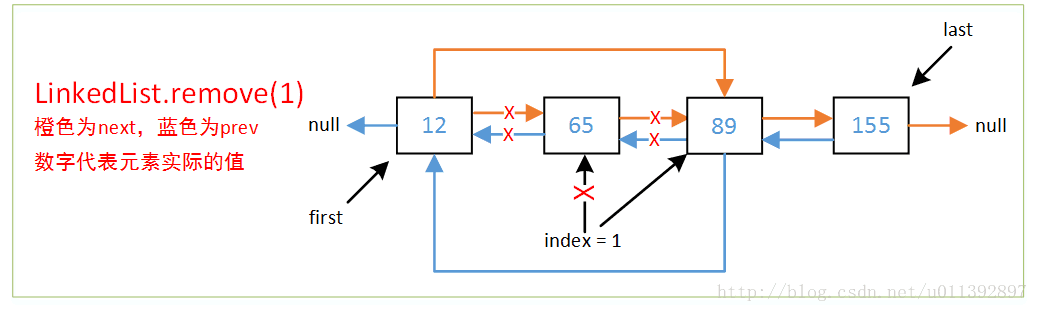
好了,LinkedList的就说到这里,因为都是一些基础的链表操作,数据结构书上都说得很清楚了,就当是复习下链表。LinkedList在各个版本之间的变化也并不大。