整体架构图

一、python模拟生成日志
import random
import time
iplist=[101,198,65,177,98,21,34,61,19,11,112,114]
urllist=['baidu.com','google.com','sougou.com','360.com','yahoo.com','yisou.com']
mobile=['xiaomi','vivo','huawei','oppo','iphone','nokia']
def get_ip():
return '.'.join(str(x) for x in random.sample(iplist,4))
def get_time():
return time.strftime('%Y%m%d%H%M%S',time.localtime())
def get_url():
return random.sample(urllist,1)[0]
def get_mobile():
return random.sample(mobile,1)[0]
def get_log(count):
while count>0:
log='{}\t{}\t{}\t{}\n'.format(get_ip(),get_time(),get_url(),get_mobile())
# with open('/usr/local/src/tmp/1.log','a+')as file:
# file.write(log)
print(log)
time.sleep(2)
count=count-1
if __name__ == '__main__':
get_log(10000)效果:
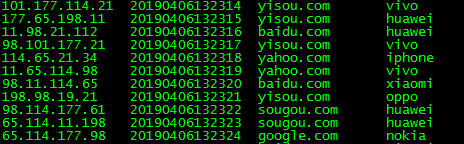
二、配置flume
这里配置两个sink,一个发送到HDFS,一个发送到Kafka
a1.sources=r1
a1.sinks=k1 k2
a1.channels=c1 c2
#define source
a1.sources.r1.type=exec
a1.sources.r1.channels=c1 c2
a1.sources.r1.command=tail -F /usr/local/src/tmp/1.log
a1.sources.r1.shell=/bin/sh -c
a1.sources.r1.selector.type=replicating
#sink1toKafka
a1.sinks.k1.type =org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = streaming
a1.sinks.k1.brokerList= 192.168.220.155:9092
a1.sinks.k1.kafka.bootstrap.servers = 192.168.220.155:9092
a1.sinks.k1.producer.requiredAcks = 1
a1.sinks.k1.batchSize = 5
a1.sinks.k1.channel=c1
#sink2toHDFS
a1.sinks.k2.type=hdfs
a1.sinks.k2.channel=c2
a1.sinks.k2.hdfs.path=hdfs://192.168.220.155:9000/flume
#channel1
a1.channels.c1.type=memory
#channel2
a1.channels.c2.type=memory三、配置Kafka
创建一个topic
./kafka-topics.sh --create --zookeeper master155:2181,node156:2181,node157:2181 --replication-factor 1 --partitions 1 --topic streaming
查看是否成功
./kafka-topics.sh --list --zookeeper master155:2181,node156:2181,node157:2181
./kafka-topics.sh --describe --zookeeper master155:2181,node156:2181,node157:2181 --topic streaming

测试
a.启动python
b.启动flume
flume-ng agent -n a1 -c /opt/flume-1.6/conf -f /usr/local/src/logflume.conf -Dflume.root.logger=INFO,console
c.查看hdfs是否有数据
hdfs dfs -ls /flume


测试成功
d.查看kafka是否能接到数据
kafka-console-consumer.sh --zookeeper master155:2181,node156:2181,node157:2181 --topic streaming

测试成功
到目前为止,已经完成了日志-flume-kafka-hdfs的工作了。
四、SparkStreaming实时日志分析
package Sparkstreaming
import org.apache.spark.SparkConf
//import domain.Loginfo
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
case class Loginfo(ip: String, time: String,source: String,phone:String)
object Lamdatest{
def main(args: Array[String]): Unit = {
if(args.length !=4){
System.err.println("error")
}
val Array(zk,group,topics,numThreads)=args
val conf=new SparkConf().setMaster("local[2]").setAppName("Lamdatest")
val ssc=new StreamingContext(conf,Seconds(5))
val topicMap=topics.split(",").map((_,numThreads.toInt)).toMap
val messages=KafkaUtils.createStream(ssc,zk,group,topicMap)
val cleanlog=messages.map(_._2).map(line=>{
val logs=line.split("\t")
val ip=logs(0)
val time=logs(1)
val source=logs(2)
val phone=logs(3)
Loginfo(ip,time,source,phone)
})
cleanlog.print()
//.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
输入参数启动192.168.220.155:2181,192.168.220.156:2181,192.168.220.157:2181 test streaming 1
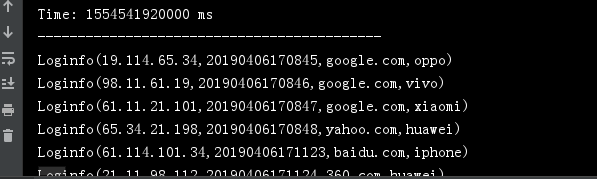
做两个实时任务,统计过去时间段的访客和来源。
val pagecount=cleanlog.map(x=>x.ip).map((_,1)).reduceByKey(_+_)
pagecount.print()
//统计过去16s的来源,每隔2秒计算一次
val window=Seconds(16)
val interval=Seconds(2)
val visitorcount=cleanlog.window(window,interval).map(x=>(x.source,1)).reduceByKey(_+_)
visitorcount.print()
