-
本文的主要目的就是为了实现以下需求:
-
通过flume收集日志;
-
将收集到的日志分发给kafka;
-
通过sparksteaming对kafka获取的日志进行处理;
-
然后将处理的结果存储到hdfs的指定目录下。
- Flume连通Kafka配置
| a1.sources = r1 a1.channels = c1 a1.sinks =s1
#sources端配置 a1.sources.r1.type=exec a1.sources.r1.command=tail -F /usr/local/soft/flume/flume_dir/kafka.log a1.sources.r1.channels=c1
#channels端配置 a1.channels.c1.type=memory a1.channels.c1.capacity=10000 a1.channels.c1.transactionCapacity=100
#设置Kafka接收器 a1.sinks.s1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka的broker地址和端口 a1.sinks.s1.brokerList=manager:9092,namenode:9092,datanode:9092
#设置Kafka的Topic a1.sinks.s1.topic=realtime
#设置序列化方式 a1.sinks.s1.serializer.class=kafka.serializer.StringEncoder a1.sinks.s1.channel=c1 |
| 注意,关于配置文件中注意3点: 1.配置文件: a. a1.sources.r1.command=tail -F /usr/local/soft/flume/flume_dir//kafka.log b. a1.sinks.s1.brokerList= manager:9092,namenode:9092,datanode:9092 c . a1.sinks.s1.topic=realtime 2.很明显,由配置文件可以了解到: a.我们需要在/usr/local/soft/flume/flume_dir/下建一个kafka.log的文件,且向文件中输出内容(下面会说到); b.flume连接到kafka的地址是 manager:9092,namenode:9092,datanode:9092,注意不要配置出错了; c.flume会将采集后的内容输出到Kafka topic 为realtime上,所以我们启动zk,kafka后需要打开一个终端消费topic realtime的内容。这样就可以看到flume与kafka之间玩起来了~~ |
- 编写测试脚本kafka_output.sh
- 在/usr/local/soft/flume/flume_dir/下建立空文件kafka.log。在root用户目录下新建脚本kafka_output.sh(一定要给予可执行权限),用来向kafka.log输入内容,脚本内容如下:
| for((i=0;i<=1000;i++)); do echo "kafka_test-"+$i>>/usr/local/soft/flume/flume_dir/kafka.log; done |
2.在Cloudera Manger(CM)上启动Zookeeper,Kafka

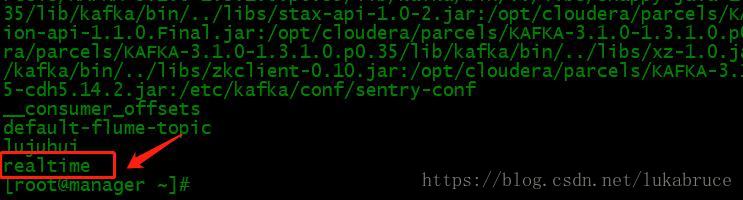
- 在Kafka集群上创建主题realtime:
| kafka-topics.sh --create --zookeeper manager:2181,namenode:2181,datanode:2181 --replication-factor 3 --partitions 1 --topic realtime |
4.打开新终端,在kafka安装目录下执行如下命令,生成对topic realtime 的消费:
| kafka-console-consumer.sh --zookeeper manager:2181,namenode:2181,datanode:2181 --from-beginning --topic realtime
|

5.启动Flume(CM上启动也行):
| 1)cd /opt/cloudera/parcels/CDH-5.7.5-1.cdh5.7.5.p0.3 2) bin/flume-ng agent --conf conf --conf-file etc/flume-ng/conf.empty/flume-conf.properties --name a1 -Dflume.root.logger=INFO,console |

6.执行kafka_output.sh脚本(注意观察kafka.log内容及消费终端接收到的内容)
|
Flume监控端:
|
| Kafka 消费端:
|
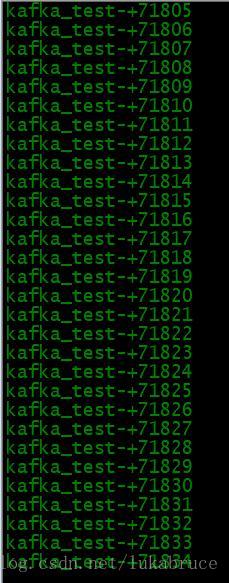
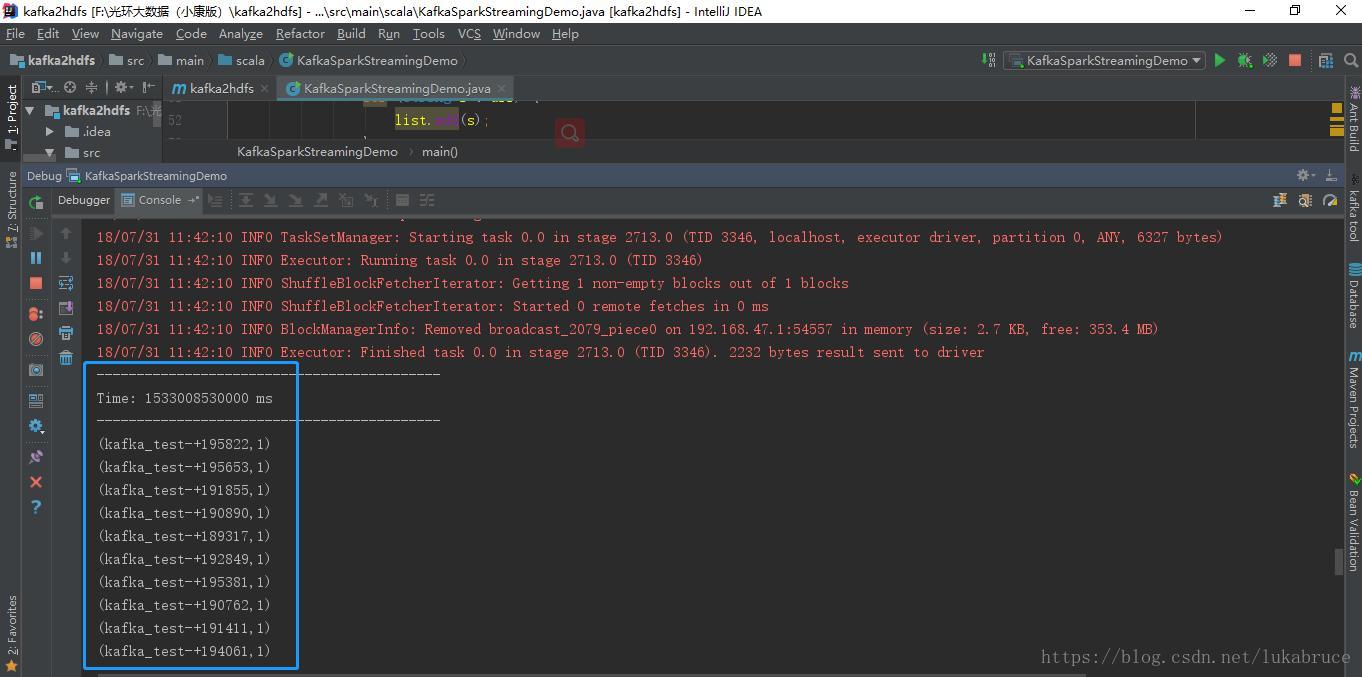
| Sparkstreaming日志处理端:
|



- pom依赖
-
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.realtime.kafka</groupId> <artifactId>kafka2hdfs</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.11.8</scala.version> <spark.version>2.1.0</spark.version> <hadoop.version>2.6.5</hadoop.version> <jackson.version>2.6.2</jackson.version> <encoding>UTF-8</encoding> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming_2.11 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-8_2.11 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume_2.11 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-flume_2.11</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.44</version> </dependency> <!-- json --> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20090211</version> </dependency> <!--jackson json --> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>${jackson.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.41</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> </plugin> </plugins> </pluginManagement> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <executions> <execution> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> </project> - Sparkstreaming代码
package test
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
/**
* @ author: create by LuJuHui
* @ date:2018/7/31
*/
object Kafka2Scala2WC {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Kafka2Scala2WC").setMaster("local[3]") //local[3]指的是在本地运行,启动3个进程
val ssc = new StreamingContext(conf, Seconds(5)) //每5秒钟统计一次数据
val kafkaParams = Map[String, Object](
/*kafka的端口号*/
"bootstrap.servers" -> "manager:9092,namenode:9092,datanode:9092",
/*k-v的反序列化*/
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
/*kafka的组号*/
"group.id" -> "kafka_wc",
/*偏移量重置*/
"auto.offset.reset" -> "latest",
/*是否自动提交*/
"enable.auto.commit" -> (false: java.lang.Boolean)
)
/*kafka的已经创建的主题*/
val topics = Array("realtime") //主题可以有多个“topicA”,“topicB”
/*创建一个离散流*/
val data = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
/*对kafka消费端取出来的数据进行初步处理,获取value值*/
val lines = data.map(_.value())
/*对初步处理的数据进行扁平化处理,并按照空格切分*/
val words = lines.flatMap(_.split(" "))
/*获取的单词作为key值,‘1’作为value值,组成(K,V)对*/
val wordAndOne = words.map((_, 1))
val reduced = wordAndOne.reduceByKey(_ + _)
/*将结果存入hdfs,因为使用的cdh3.7.5版本的hadoop,所以其端口号默认为8020*/
reduced.foreachRDD(rdd => {
rdd.saveAsTextFile("hdfs://namenode:8020/user/kafka/data")
})
/*打印结果*/
reduced.print()
/*启动sparkstreaming程序*/
ssc.start()
/*等待程序退出*/
ssc.awaitTermination()
}
}
【注意:在新建maven项目是一定要根据scala版本去添加对应的依赖jar包,否则会报错】