摘要:本文要实现的是一个使用Flume来处理Kafka的数据,并将其存储到HDFS中去,然后通过Hive外部表关联查询出来存储的数据。
所以在建立一个maven工程,整个工程最终的目录如下:
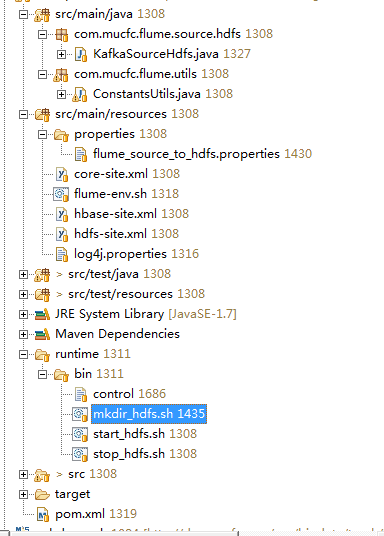
下面开始一步一步讲解
1、定义自己的source
之所以不用源生的,是因为要对得到的消息要一定的处理后再保存到hdfs中去,这里主要就是将每一条消息解析并组装成以“|”做分隔的一条记录

在这个类中定义Start方法来初始化连接kafka:

在这个类中定义处理消费的方法:
其实就是将消息处理成一条以“|”符号隔开的一条数据并放入到channel中:
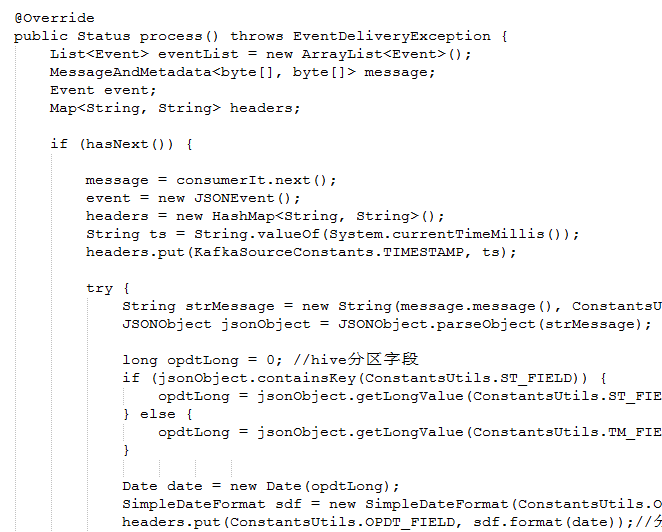
中间还有一部分处理:
笔者都一而过了,这是放到event,下一步就是放在channel中了。

上面的process方法会调用到这:
其实就是将消息解析,并组装成一条以“|”隔开的数据

2、配置文件
接下来就是配置source/channel/sink了。
配置文件部分内容:

注意,这里的channle使用的type是SPILLABLEMEMORY,表示source来的event都会先保存到内存中去,内存不够了再保存到硬盘中去。各项参数此处不再做解释
3、启动脚本:
如果flume程序 所在的集群不在haddop集群中,需要将haddop集群的/hadoop/native文件夹复制到此flume运行的机器,并且将hdfs-site.xml也一起复制过来。如果还操作了hbse/hive,那么hbse-site.xml.hive-site.xml也要复制过来。
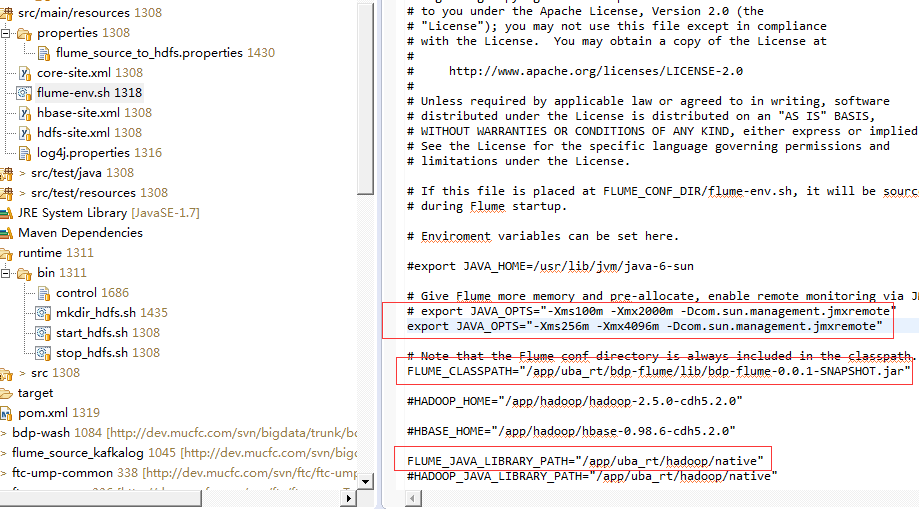
然后编写启动脚本:
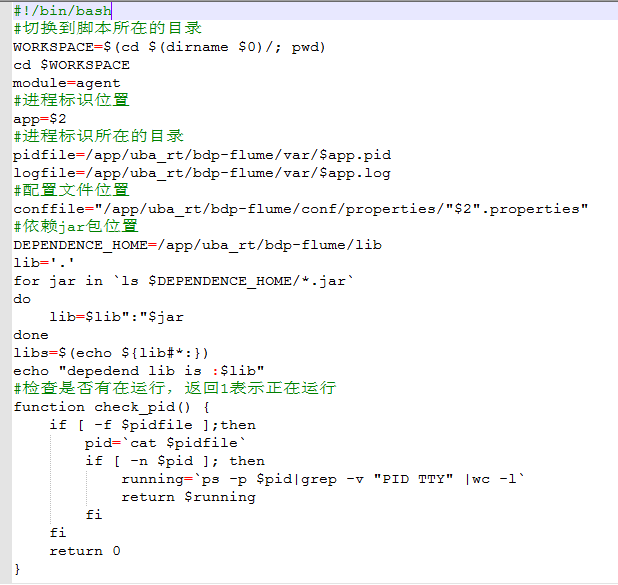


启动执行:

停止执行:

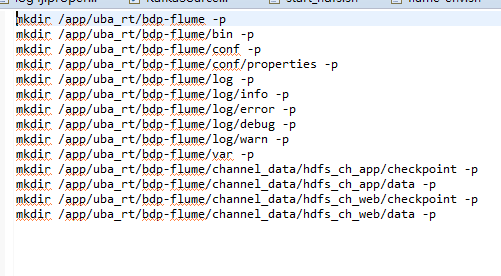
事先要将checkpoint目录建立起来:
4、打包
最后打包成一个tar包,并将配置文件是jar包分离
打包后目录:
所有的jar包都在lib目录,而不是打成一个大jar包
在上面的启动脚本中就可以指明依赖的jar包:
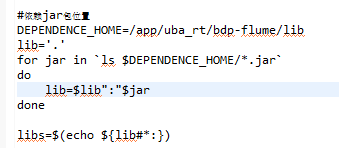
启动时添加 这个参数:

5、运行
flume安装很简单,将flume安装包解压后就可以,同时将我们的应用从上面的tar包上传到此台机器,并解压

并进入bdp-flume建立如下几个目录:
channel_date:channel的硬盘存储目录
log:打印的日志存储目录
var:存放当前flume应用的pid,主要是启动和停止会用到
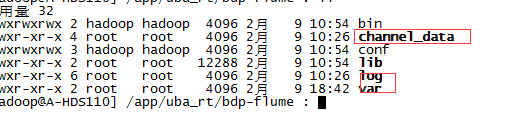
启动:
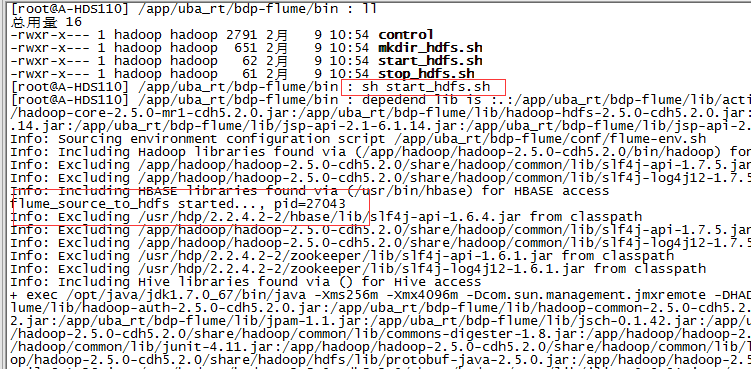
这是log目录下打印的部分日志:

看一下hdfs是否有数据:
注意,这里是直接将文件存放到hdfs的这个路径,并每天有一个文件价(为后面和hive表分区关联方便)

保存的文件:.tmp结尾的表示当前正在写入的,还没有滚动

因为是保存成.snappy文件,所以直接查询会乱码。如果是保存成textfile的话,就不会。但是snappy有压缩,textfile没,建议使用snappy。
6、建立Hive外部表
CREATE TABLE IF NOT EXISTS ods_uba.kafka_appchnl_source_log
(
source_log string,
muid string, -- 'parse ck',
dev_no string, -- 'uu',
user_id string, -- 'ur',
mbl_nbr string, -- 'ud',
chnl_code string, -- 'ch',
opt_type string, -- 'ac',
req_no string, -- 'rn',
vt_time string, -- 'tm',
st_time string -- 'st',
)
PARTITIONED BY (opdt string)
row format delimited
fields terminated by '^' lines terminated by '\n'
stored as textfile
LOCATION '/hive/warehouse/ods_uba.db/kafka_appchnl_source_log';注意:这里Location指的是hdfs文件存放的目录,可以不用完全是hive表默认的存储路径一样。
添加分区数据:
alter table kafka_appchnl_source_log add if not exists partition(opdt='2017-01-06')
查询:
可以用presto和dbveare使用来查询,也可以使用hive命令查询
这是查询出来的部分字段:


更多技术请关注笔者微信技术公众号"单例模式"
